![]()
CHAPTER 1
Understanding the need for parallel computing
CONTENTS
1.1 Introduction
1.2 From problem to parallel solution – development steps .
1.3 Approaches to parallelization
1.4 Selected use cases with popular APIs
1.5 Outline of the book
1.1 INTRODUCTION
For the past few years, increase in performance of computer systems has been possible through several technological and architectural advancements such as:
1. Within each computer/node: increasing memory sizes, cache sizes, bandwidths, decreasing latencies that all contribute to higher performance.
2. Among nodes: increasing bandwidths and decreasing latencies of interconnects.
3. Increasing computing power of computing devices.
It can be seen, as discussed further in Section 2.6, that CPU clock frequencies have generally stabilized for the past few years and increasing computing power has been possible mainly through adding more and more computing cores to processors. This means that in order to make the most of available hardware, an application should efficiently use these cores with as little overhead or performance loss as possible. The latter comes from load imbalance, synchronization, communication overheads etc.
Nowadays, computing devices typically used for general purpose calculations, used as building blocks for high performance computing (HPC) systems, include:
• Multicore CPUs, both desktop e.g. a 7th generation Intel i7-7920HQ CPU that features 4 cores with HyperThreading for 8 logical processors clocked at 3.1GHz (up to 4.1GHz in turbo mode) and server type CPUs such as Intel Xeon E5-2680v4 that features 14 cores and 28 logical processors clocked at 2.4 GHz (up to 3.3GHz in turbo mode) or AMD Opteron 6386 SE that features 16 cores clocked at 2.8 GHz (3.5 GHz in turbo mode).
• Manycore CPUs e.g. Intel Xeon Phi x200 7290 that features 72 cores (288 threads) clocked at 1.5 GHz (1.7 GHz in boost).
• GPUs, both desktop e.g. NVIDIA® GeForce® GTX 1070, based on the Pascal architecture, with 1920 CUDA cores at base clock 1506 MHz (1683 MHz in boost), 8GB of memory or e.g. AMD R9 FURY X with 4096 Stream Processors at base clock up to 1050 MHz, 4GB of memory as well as compute oriented type devices such as NVIDIA Tesla K80 with 4992 CUDA cores and 24 GB of memory, NVIDIA Tesla P100 with 3584 CUDA cores and 16 GB of memory, AMD FirePro S9170 with 2816 Stream Processors and 32 GB of memory or AMD FirePro W9100 with 2816 Stream Processors and up to 32GB of memory.
• Manycore coprocessors such as Intel Xeon Phi x100 7120A with 61 cores at 1.238GHz and 16 GB of memory or Intel Xeon Phi x200 7240P with 68 cores at 1.3GHz (1.5 GHz in boost) and 16 GB of memory.
1.2 FROM PROBLEM TO PARALLEL SOLUTION – DEVELOPMENT STEPS
Typically, development of computational code involves several steps:
1. Formulation of a problem with definition of input data including data format, required operations, format of output results.
2. Algorithm design. An algorithm is a procedure that takes input data and produces output such that it matches the requirements within problem definition. It is usually possible to design several algorithms that achieve the same goal. An algorithm may be sequential or parallel. Usually a sequential algorithm can be parallelized i.e. made to run faster by splitting computations/data to run on several cores with necessary communication/synchronization such that correct output is produced.
3. Implementation of an algorithm. In this case, one or more Application Programming Interfaces (APIs) are used to code the algorithm. Typically an API is defined such that its implementation can run efficiently on a selected class of hardware.
4. Code optimization. This step includes application of optimization techniques into the code that may be related to specific hardware. Such techniques may include data reorganization, placement, overlapping communication and computations, better load balancing among computing nodes and cores. It should also be noted that for some APIs, execution of certain API functions may be optimized for the given hardware in a way transparent to the programmer.
Parallelization of a sequential code may be easy as is the case, for example, in so-called embarrassingly parallel problems which allow partitioning of computations/data into independently processed parts and only require relatively quick result integration. The process is more difficult when control flow is complex, the algorithm contains parts difficult to parallelize or when the ratio of computations to communication/synchronization is relatively small. It is generally easier to parallelize a simpler sequential program than a highly optimized sequential version.
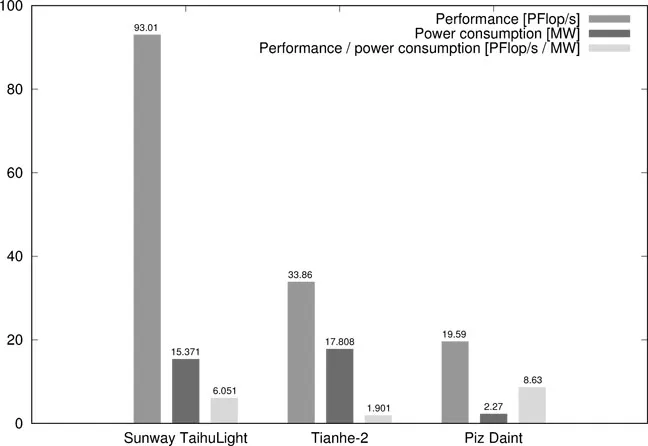
Typically parallelization aims for minimization of application execution time. However, other factors such as power consumption and reliability have become increasingly more important, especially in the latest large scale systems. Performance, power consumption and performance to power consumption ratios of the most powerful TOP500 [4] clusters are shown in Figure 1.1.
FIGURE 1.1 Top high performance computing systems according to the TOP500 list, June 2017, based on data from [4]
In spite of higher computational capabilities, power consumption of the first cluster on the list is lower than that of the second. Even better in terms of performance to power consumption ratio is Piz Daint that occupies the third spot. Such trends are shown in more detail in Section 2.6.
1.3 APPROACHES TO PARALLELIZATION
There are several approaches to programming parallel applications, including the following ones:
1. Programming using libraries and runtime systems that expose parallelism among threads, for instance: NVIDIA CUDA, OpenCL, OpenMP, Pthreads or among processes such as Message Passing Interface (MPI). In such cases, languages typically used for programming include C or Fortran. Such APIs may require management of computing devices such as GPUs (CUDA, OpenCL), handling communication of data between processes (MPI), between the host and GPU (unless new APIs such as uniform memory in CUDA are used).
2. Declarative in which existing sequential programs may be extended with directives that indicate which parts of the code might be executed in parallel on a computing device such as a multicore CPU or an accelerator such as GPU. Directives may instruct how parallelization is performed such as how iterations of a loop are distributed across threads executing in parallel, including how many iterations in a chunk are assigned to a thread (Section 4.2.2 shows how this can be done in OpenMP). It is also possible to mark code regions to ask the compiler to perform analysis and identification by itself (such as the kernels construct in OpenACC).
It should be noted that APIs such as OpenMP and OpenACC, which allow directives, also contain libraries that include functions that can be called within code to manage computing devices and parallelism.
3. Programming using higher level frameworks where development of an application might be simplified in order to increase productivity, usually assuming a certain class of applications and/or a programming model. For instance, in the KernelHive [141] system an application is defined as a workflow graph in which vertices denote operations on data while directed edges correspond to data transfers. Vertices may be assigned functions such as data partitioners, mergers or computational kernels. Definition of the graph itself is done visually which makes development easy and fast. Input data can be placed on data servers. Computational kernels are defined in OpenCL for portability across computing devices and are the only snippets of code of the application a programmer is expected to provide. An execution engine, along with other modules, is responsible for selection of computing devices taking into account optimization criteria such as minimization of application execution time [141] or minimization of application execution time with a bound on the total power consumption of selected services [55] or others.
Other frameworks or higher level abstractions for using computing devices include: rCUDA [63, 64] (it allows concurrent and remote access to GPUs through an API and makes it possible to use many GPUs in parallel), VirtualCL (VCL) Cluster Platform [19] (enables to run OpenCL applications in a cluster with potentially many computing devices) and Many GPUs Package (MGP) [18] (enables to launch OpenMP and OpenCL applications on clusters that include several GPUs), OMPICUDA [105] (allowing to run applications implemented with OpenMP/MPI on hybrid CPU and GPU enabled cluster systems), CUDA on Apache™ Hadoop® [3, 86] (two levels of paralleli...