
eBook - ePub
TV Content Analysis
Techniques and Applications
- 674 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
TV Content Analysis
Techniques and Applications
About this book
The rapid advancement of digital multimedia technologies has not only revolutionized the production and distribution of audiovisual content, but also created the need to efficiently analyze TV programs to enable applications for content managers and consumers. Leaving no stone unturned, TV Content Analysis: Techniques and Applications provides a de
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
Digital MarketingIndex
Computer Science
Chapter 1

Local Spatiotemporal Features for Robust Content-Based Video Copy Detection
Katholieke Universiteit Leuven
Katholieke Universiteit Leuven
Katholieke Universiteit Leuven
Contents
1.1 Introduction
1.1.1 Local Spatiotemporal Features for Video CBCD
1.1.2 Overview
1.2 Efficient Local Spatiotemporal Interest Point
1.2.1 Short Overview of Spatiotemporal Interest Points
1.2.2 Hessian-Based STIP Detector
1.2.3 Hessian-Based STIP Descriptor
1.2.4 Adaptations for Video CBCD
1.3 Disk-Based Pipeline for Efficient Indexing and Retrieval
1.3.1 Pipeline Overview
1.3.2 Indexing and Retrieving High-Dimensional Data
1.3.3 Disk-Based p-Stable LSH
1.4 Experimental Evaluation
1.4.1 Setting Up the Experiment
1.4.2 Comparison between Spatial and Spatiotemporal Features
1.4.3 Robustness to Transformations
1.4.4 Video Copy Detection from Handheld Shooting
1.5 Application: Monitoring Commercial Airtime
1.6 Conclusions
Acknowledgments
References
Detecting (near) copies of video footage in streams or databases has several useful applications. Reuse of video material by different data aggregators can help as a guide to link stories across channels, while finding copies of copyrighted video fragments is of great interest for their rightful owners. Most methods today are based on global descriptors and fingerprinting techniques as they can be computed very efficiently. The downside, however, is that they are inherently not very well suited to detect copies after transformations have been applied that change the overall appearance, such as the addition of logos and banners, picture-in-picture, cropping, etc. To cope with such variations, methods based on local features have been proposed. Most such robust content-based copy detection (CBCD) systems proposed to date have in common that they initially rely on the detection of two-dimensional (2D) interest points on specific or all frames and only use temporal information in a second step (if at all). Here we propose the use of a recently developed spatiotemporal feature detector and descriptor based on the Hessian matrix. We explain the theory behind the features as well as the implementation details that allow for efficient computations. We further present a disk-based pipeline for efficient indexing and retrieval of video content based on two-stable locality sensitive hashing (LSH). Through experiments, we show the increased robustness when using spatiotemporal features as opposed to purely spatial features. Finally, we apply the proposed system to faster than real-time monitoring of 71 commercials in 5 h of TV broadcasting.
1.1 Introduction
Many TV channels around the globe broadcast news, often on a daily basis. For approximately half of their news stories, they all obtain the same video footage from a few big press agencies. Nevertheless, the same material is presented substantially different depending on the channel, due to a high level of post-processing: logos and banners are added, items are shown picture-in-picture, gamma-correction, cropping, zoom-in, trans-coding, and other transformations are applied to the raw input data so as to adapt the content to the look and feel of a particular channel, as illustrated in Figure 1.1.


Figure 1.1 Video footage reuse in broadcasts. All shots were correctly retrieved by our system from a 88+ h database (Image from Walker, K., TRECVID 2006, LDC2006E40, Linguistic Data Consortium, Philadelphia, PA, 2006 With permission.)
For data aggregators on the Internet, such as news sites collecting information from different channels and presenting it in a unified framework to the user, detecting reuse of the same video footage is a useful tool to link stories across channels, independent of language or political opinion. Likewise, for researchers in broadcasting companies, it may be interesting to retrieve the original video footage based on broadcasted fragments, especially when the metadata are incomplete or missing, which is often the case for older archives.
However, the high level of postprocessing poses specific challenges to the problem of content-based video copy detection. Most of the methods proposed to date are based on global methods and fingerprinting techniques (e.g., [8,15,20]). These work well for exact copies, but have inherently problems with added banners, logos, picture-in-picture, rescaling, cropping, etc. For this reason, specific preprocessing steps are often applied, such as ignoring parts of the video where these additions typically appear, or searching for strong gradients to detect picture-in-picture.
In order to cope with such variations, the use of local features, also referred to as interest points, has been proposed in the context of CBCD by [10,11,19,26]. In [10], a detailed comparative study of different video copy detection methods has been performed, including both global and local descriptors. The 2D local features proved indeed more robust than the global features, although they come with a higher computational cost. In the overview, the authors also tested a single local spatiotemporal feature based on the Harris corner detector [17], but the computational cost proved too high to be considered practical.
1.1.1 Local Spatiotemporal Features for Video CBCD
Almost all CBCD systems proposed to date that are based on local features, have in common that they rely on the detection of 2D interest points on specific or all frames of the videos and use the descriptors of the local neighborhood of these points as indices to retrieve the video. Typically, temporal information, if used at all, is added to these features only in a second step. Joly et al. [10] detect local features in key frames only but use information from precedent and following frames as well when computing the descriptor. Law et al. [19] proposed a method for CBCD by means of tracking 2D interest points throughout the video sequence. They use the 2D Harris detector [7] and Kanade–Lucas–Tomasi (KLT) feature tracking software [28]. By using the trajectories, the local descriptor is enhanced with temporal information, while the redundancy of the local descriptors is reduced. The obtained descriptors are invariant to image translation and affine illumination transformations, but are not scale-invariant.
When applying spatial features, the frames that are analyzed are either determined by subsampling (i.e., extracting features from every nth frame), by key-frame selection or a combination of the two. In the case of subsampling, there is no guarantee that the same frames will be selected in both the reference and query videos. Hence, one relies on the assumption that similar features will be found in temporally nearby frames—an assumption which only holds up to some extent and for slowly changing scenes only. For key-frame selection, global methods are typically used (e.g., based on motion intensity) which are often not reliable with respect to specific transformations such as picture-in-picture, the addition of banners, etc. A system that is using key frames is highly dependent on the robustness of the used shot-boundary detection. In this regard, local spatiotemporal features have several advantages:
1. The features are extracted at interesting locations not only spatially but also over time, which makes them more discriminative as well as better localized within the shot.
2. As the spatiotemporal features are detected at interesting areas throughout the shot, they allow for an easy and robust alignment between shots by simply finding the corresponding features.
3. The resulting set of descriptors contains information from within the whole shot, rather than focusing on a few selected (key)frames (see also Figure 1.2).
4. By analyzing a spatiotemporal volume instead of spatial planes at certain (key)frames, the performance of the system is no longer dependent on the robustness of the chosen shot-cut detection algorithm.
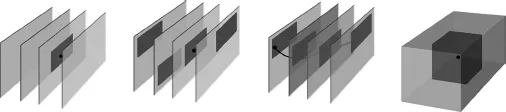
Figure 1.2 A visual comparison of different local features used in the context of CBCD. In the first three drawings, a 2D feature is detected at a specific (key)frame. The descriptor is computed (from left to right) using solely spatial information; by adding temporal information by including information from neighbor...
Table of contents
- Cover
- Title Page
- Copyright
- Contents
- Preface
- Acknowledgments
- Editors
- Contributors
- PART I: CONTENT EXTRACTION
- PART II: CONTENT STRUCTURING
- PART III: CONTENT RECOMMENDATION
- PART IV: CONTENT QUALITY
- PART V: WEB AND SOCIAL TV
- PART VI: CONTENT PRODUCTION
- Glossary
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access TV Content Analysis by Yiannis Kompatsiaris, Bernard Merialdo, Shiguo Lian, Yiannis Kompatsiaris,Bernard Merialdo,Shiguo Lian in PDF and/or ePUB format, as well as other popular books in Computer Science & Digital Marketing. We have over 1.5 million books available in our catalogue for you to explore.