This extremely up-to-date book, Speech Production and Second Language Acquisition, is the first volume in the exciting new series, Cognitive Science and Second Language Acquisition. This new volume provides a thorough overview of the field and proposes a new integrative model of how L2 speech is produced.
The study of speech production is its own subfield within cognitive science. One of the aims of this new book, as is true of the series, is to make cognitive science theory accessible to second language acquisition. Speech Production and Second Language Acquisition examines how research on second language and bilingual speech production can be grounded in L1 research conducted in cognitive science and in psycholinguistics. Highlighted is a coherent and straightforward introduction to the bilingual lexicon and its role in spoken language performance.
Like the rest of the series, Speech Production and Second Language Acquisition is tutorial in style, intended as a supplementary textbook for undergraduates and graduate students in programs of cognitive science, second language acquisition, applied linguistics, and language pedagogy.

- 248 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Speech Production and Second Language Acquisition
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
I
1 An Overview of Theories of First Language Speech Production
DOI: 10.4324/9780203763964-1
Interest in the psycholinguistic processes involved in producing L1 speech dates back to as early as the beginning of the 20th century, when Meringer (1908) first published his systematic collection of slips of the tongue made by German native speakers. Nevertheless, the first comprehensive theories of L1 production were not constructed until the 1970s. In the 35 years that have passed since then, the research into oral L1 production has grown into an autonomous discipline within the field of cognitive psychology. Although many questions concerning how we produce language have remained unanswered, with the help of the modern methods of experimental psychology and the recently available neuroimaging techniques, we now have a good understanding of a number of speech processes. The aim of this chapter is to acquaint the reader with the most influential theories of L1 production. Most theories of monolingual and bilingual speech production follow two main trends: the spreading activation theory (e.g., Dell, 1986; Dell & O’Seaghda, 1991; Stemberger, 1985) and the modular theory of speech processing (e.g., Fry, 1969; Garret, 1976; Laver, 1980; Levelt, 1989, 1993; Levelt et al., 1999; Nooteboom, 1980). Researchers working in the spreading activation paradigm assume that speech processing is executed in an interactive network of units and rules, in which decisions are made on the basis of the activation levels of the so-called nodes that represent these units and rules. Traditional modular theories, on the other hand, postulate that the speech-encoding system consists of separate modules, in which only one way connections between levels are allowed.
Spreading Activation Theory
The spreading activation theory of speech production has not been adopted as widely as Levelt’s (1989, 1993) modular model, which is the most frequently cited theory in L2 speech production research. Nevertheless assumptions of the spreading activation models have influenced most of the research carried out on the slips of the tongue (e.g., Poulisse, 1993, 1999), unintentional code-switching (e.g., Poulisse & Bongaerts, 1994), and the organization of the bilingual lexicon (e.g., Colomé, 2001; Costa et al., 1999; Hermans et al., 1998; van Hell & de Groot, 1998).
Stemberger (1985) and Dell (1986) devised the first comprehensive model of interactive activation spreading in speech production. Because Stemberger’s model differs from that of Dell only in some details used in describing the grammatical encoding procedures, here only Dell’s model is discussed. Like in modular models of speech production (e.g., Fry, 1969; Garrett, 1976; Levelt, 1989), in Dell’s spreading activation theory it is also assumed that there are four levels of knowledge involved in producing L1 speech: semantic (i.e., word meaning), syntactic (e.g., phrase building and word order rules),), morphological (e.g., the morphological make up of words and rules of affixation), and phonological levels (e.g., phonemes and phonological rules). Adopting the tenets of generative grammar (Chomsky, 1965), and those of the so-called frame-slot models of production (for more detail, see the section Syntactic Processing in chap. 2), Dell postulated that the generative rules on a given level build a frame with slots to be filled in by insertion rules. For example, on the syntactic level the rules in English create a position for the subject of the sentence, another one for the verb phrase and, if needed, slots for prepositional phrases. As a next step, words or phrases to fill in these slots are selected. At the morphological level there are slots for stems and affixes, and at the phonological level slots are assumed to exist for onsets and rimes as well as for phonemes. To illustrate this process, let us take Dell’s own example, the sentence “This cow eats grass.” In this sentence there is a slot for the determiner “this,” the noun “cow,” the present-tense verb “eats,” and the noun “grass.” In the case of the word “eats,” a slot is created at the morphological level for the stem “eat” and another one for the affix “s.” In the process of phonological encoding, there is an onset slot for [k] and a rime slot for [au] at the syllable level, and a consonant slot for [k] and a vowel slot for [au] at the phoneme level.
In Dell’s (1986) spreading activation model, the lexicon is considered a network of interconnected items and “contains nodes for linguistic units such as concepts, words, morphemes, phonemes, and phonemic features, such as syllables and syllabic constituents as well” (p. 286). In the lexicon, conceptual nodes are assumed to be connected to word nodes that define words, and word nodes are conjoined with morpheme nodes, which again represent specific morphemes. Next, there is a connection between morpheme and phoneme nodes specifying phonemes, and finally phoneme nodes are linked to phonological feature nodes such as labial, nasal, voiced, and so on. In order for the words to be able to be selected for specific slots in the sentence, each word is labeled for the syntactic category it belongs to (e.g., in our example sentence “cow” is labeled as noun). Similarly, morphemes and phonemes are also marked for the class they are the members of (e.g., “eat” as stem, “s” as affix) (see Fig. 1.1 for the illustration of how encoding works in spreading activation models).
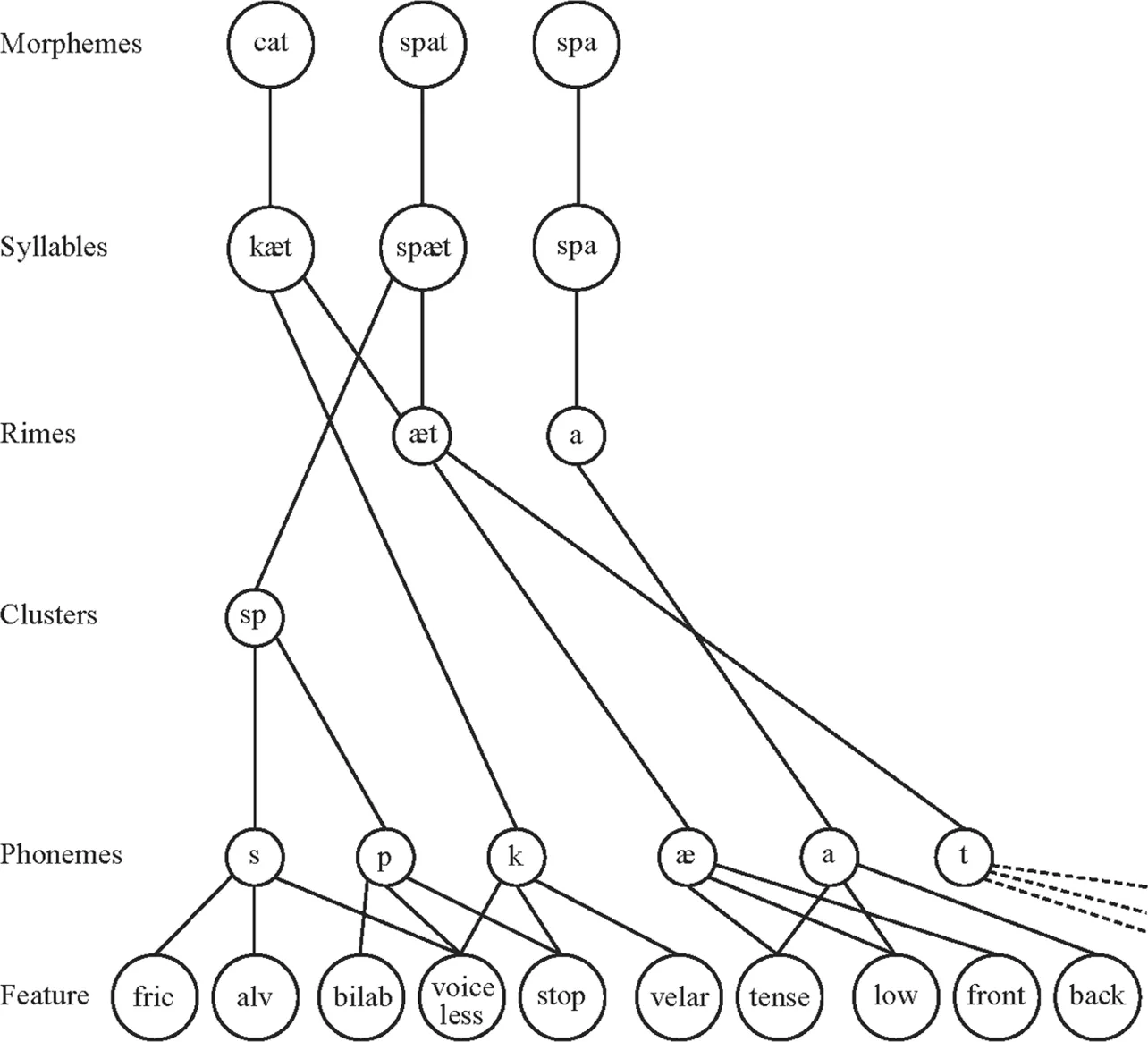
Copyright 1986 by Gary Dell. Adapted by permission.
The mechanism responsible for sentence production is the process of spreading activation. In error-free processing, the node of the required category that has the highest level of activation is accessed. Immediately after this node is selected, it spreads its activation further to the lower level nodes. As an illustration, in the case of the word node “construct,” activation is forwarded to the constituent syllable nodes: “con” and “struct.” First, “con” is more highly activated than “struct”; otherwise one might say “structcon” instead of “construct.” Next, activation will be passed on to the phonological segment nodes [k], [o], and [n]. Once the encoding of the syllable “con” is finished, the level of activation of this syllable node decreases so that it would not be selected repeatedly. Following this, the encoding of the next syllable “struct” can start. In Dell’s (1986) model selected nodes are tagged, and their tags specify the order in which they need to be encoded. Activation spreads not only from one level to the other, but also across levels. For example, at the lexical level, semantically and phonologically related items in the lexicon also receive some activation (e.g., if “dog” is the target word, “hog” and “cat” are also activated to some degree). This explains the occurrence of lexical substitutions and phonologically related lexical errors such as saying “cat” instead of “dog” or “hog” instead of “dog.”
Dell (1986) also assumed that activation can spread bidirectionally, that is, top-down and bottom-up. In the case of sentence production, activation spreads downward from words to morphemes, from morphemes to syllable. On the other hand, speech perception is seen as the backward spreading of activation: when one perceives a sound, it sends activation to the syllable nodes, syllable nodes activate morphemes, and so on. To illustrate this, if one hears the phonemes [k] [æ] [t], they will activate the syllable node [kæt], which passes on activation to the word node “cat,” which in turn selects the concept CAT. Because monitoring involves perceiving one’s own speech, the existence of a separate monitor is not assumed, and monitoring is hypothesized to be done in the same way as understanding the interlocutor’s speech. For example, in the case of the phonological substitution error of saying “hog” instead of “dog,” once the speaker perceives the phoneme [h], activation will flow backward to the syllable node of [hog], and the encoding process will start again from the syllable level of [dog].
We have to note that although Levelt and his colleagues’ work on speech production is called the modular model, Dell’s theory is also modular in the sense that it supposes the existence of hierarchical networks of words, morphemes, syllables, phonemes, and phonological features. However, unlike in Levelt’s model, where at least certain bits of the message need to be processed by the higher order module before lower order processing mechanisms can be initiated, traditional spreading activation models allow for parallel processing at the various levels.1
Levelt’s Modular Model of Speech Production
Several attempts have been made in the literature to set up a comprehensive model of speech processing, but the most widely used theoretical framework in L2 language production research is Levelt’s (1989, 1993, 1995, 1999a, 1999b) model originally developed for monolingual communication (for a schematic representation, see Fig. 1.2). Here we describe the newest version of the model (Levelt, 1999a). Levelt argued that speech production is modular; that is, it can be described through the functioning of a number of processing components that are relatively autonomous in the system. Two principal components are distinguished: the rhetorical/semantic/syntactic system and the phonological/phonetic system. The model supposes the existence of three knowledge stores: the mental lexicon, the syllabary (containing gestural scores, i.e., chunks of automatized movements used to produce the syllables of a given language), and the store containing the speaker’s knowledge of the external and internal world. This last store comprises the discourse model, which is “a speaker’s record of what he believes to be shared knowledge about the content of the discourse as it evolved” (Levelt, 1989, p. 114), the model of the addressee (the present context of interaction and the ongoing discourse), and encyclopedic knowledge (information about the world). The basic mechanisms of speech processing are conceptualized by Levelt in a fairly straightforward manner: People produce speech first by conceptualizing the message, then by formulating its language representation (i.e., encoding it), and finally by articulating it. With regard to speech perception, speech is first perceived by an acoustic-phonetic processor, then undergoes linguistic decoding in the speech comprehension system (i.e., the parser), and is finally interpreted by a conceptualizing module. The unique feature of the model is the integration of the processes of acoustic-phonetic encoding and sentence processing into one comprehensive system, and its richness in detail. For example, it precisely specifies the role of the lexicon and the procedures of monitoring in relation to the processing components and delineates explicit directional paths between the modules outlining their cooperation in producing their joint product, speech.
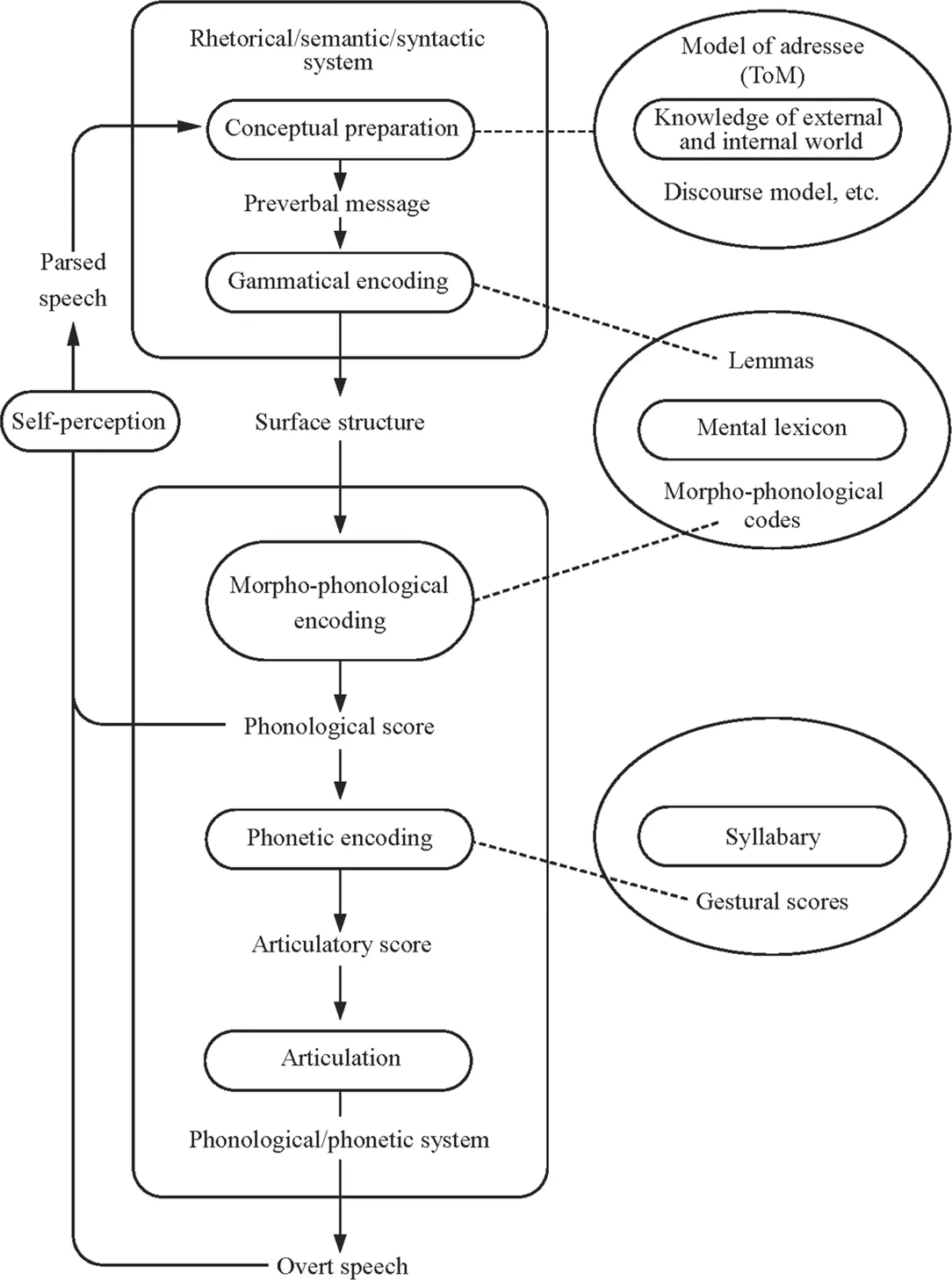
Copyright 1999 by Oxford University Press. Reprinted by permission.
In Levelt’s model, the processing components are “specialists” in the particular functions they are to execute; that is, they do not share processing functions. A component will start processing if, and only if, it has received its characteristic input. This model assumes that processing is incremental, which means that as soon as part of the preverbal message is passed on to the formulator, the conceptualizer starts working on the next chunk regardless of the fact that the previous chunk is still being processed (Kempen & Hoenkamp, 1987). As a consequence, the articulation of a sentence can begin long before the speaker has completed the planning of the whole of the message. Thus, parallel processing is taking place as the different processing components work simultaneously. This is possible only because most of the actual production mechanisms, particularly in the encoding phase, are fully automatic. The incremental, parallel, and automatized nature of processing needs to be assumed in order to account for the great speed of language production.
Let us now look at the main processing components involved in generating speech as depicted in Fig. 1.2, which is the “blueprint” of the language user. In the first phase, called conceptual preparation, the message is generated through macroplanning and microplanning. Macroplanning involves the elaboration of the communicative intention. Communicative intentions are expressed by speech acts, which are actions one performs by speaking such as informing, directing, requesting, apologizing, and so on (Austin, 1962; Searle, 1969). In order to perform a speech act, one needs to select the information to be encoded and decide on the order in which this information will be conveyed. Once these decisions have been made, microplanning can start. In microplanning, speakers decide on the perspective that they need to take in conveying the message (e.g., whether he or she should say “The book is behind the vase” or “The vase is in front of the book”). The so-called “accessibility status” also needs to be determined. This means that one needs to consider whether an object, a person, a situation, and so forth have already been mentioned in previous discourse. This influences decisions such as whether a noun or phrase or pronoun (e.g., “the mother” or “she”) should be used. Similar decisions concerning what constitutes new and old informat...
Table of contents
- Cover Page
- Half Title Page
- Title Page
- Copyright Page
- Dedication
- Table of Contents
- Series Page
- Series Editor’s Preface
- Acknowledgments
- Introduction: Issues in L2 Speech Production Research
- PART I
- PART II
- Glossary
- References
- Author Index
- Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Speech Production and Second Language Acquisition by Judit Kormos in PDF and/or ePUB format, as well as other popular books in Languages & Linguistics & Linguistics. We have over 1.5 million books available in our catalogue for you to explore.