Damage to the brain can impair language in many different ways, severely harming some linguistic functions whilst sparing others. To achieve some understanding of the apparently bewildering diversity of language disorders, it is necessary to interpret impaired linguistic performance by relating it to a model of normal linguistic performance. Originally published in 1987, this book describes the application of such models of normal language processing to the interpretation of a wide variety of linguistic disorders. It deals with both the production and the comprehension of language, with language at both the sentence and the single-word level, with written as well as with spoken language and with acquired as well as with developmental disorders.

eBook - ePub
The Cognitive Neuropsychology of Language (Psychology Revivals)
- 416 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
The Cognitive Neuropsychology of Language (Psychology Revivals)
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
1 | Functional Architecture of the Language-Processing System |
Department of Psychology, Birkbeck College, University of London, Malet Street, London WC1E 7HX
The contributors to this book share a core set of assumptions about human linguistic behaviour and how it may be studied. The first of these assumptions is that language performance—the perception and the production of written and spoken language—is mediated by an internal information-processing system, the language-processing system, which acts to form and to transform various types of linguistic representations. The second assumption is that this language-processing system is modular in character. The term “modular” is meant to indicate that the system is made up of relatively independent sub-systems—that is, individual information processing components—each responsible for a particular circumscribed linguistic processing task, such as identifying letters, producing spoken words, or accessing semantic representations. The third assumption is that there are two different but equally valid and equally valuable methods for investigating the nature of a modularly organised language-processing system. One way is to carry out laboratory investigations of some language-processing task with normal subjects. Alternatively, one can study people in whom brain damage has impaired the ability to perform certain language-processing tasks. This is “the cognitive neuropsychology of language,” a sphere of investigation in which theories about the language-processing system are used to interpret data from patients with linguistic impairments, and data from such patients are used to test and to refine such theories. All of the work reported in this book adopts this approach to the study of language.
Our book is not intended as a basic introductory text. Nevertheless, it does aspire to a degree of comprehensiveness; the book includes material on all the major aspects of language processing. We see the book as providing something like a state-of-the-art review, an attempt to capture what is currently going on in a new and rapidly-expanding field.
This first chapter is not meant as an introduction to cognitive neuropsychology, either; it is meant instead as a guide to the sixteen chapters which follow. Some readers may wish to begin with it, to provide an idea of where they will be going. Others may prefer to read it last, to find out where they have been. General introductions to the subject are available elsewhere: some examples are Coltheart (1985), relevant chapters in Harris and Coltheart (1986), Ellis (1984) and Ellis and Young (1986).
The study of the cognitive neuropsychology of language received a considerable impetus in 1973, when Marshall and Newcombe published their paper “Patterns of paralexia.” In this paper, they defined three different varieties of acquired dyslexia (reading disorder caused by brain damage), which they referred to as visual dyslexia, surface dyslexia, and deep dyslexia. What was of particular significance was that a model of normal reading was proposed in this paper, and the three different acquired dyslexias were interpreted as three different patterns of impairment to this multicomponent model.
The impetus provided by this paper was two-fold. Firstly, a considerable amount of research in the decade following the paper was devoted to learning more about the characteristics of two of these dyslexic syndromes: deep dyslexia (e.g., Coltheart, Patterson, & Marshall, 1980), and surface dyslexia (e.g., Patterson, Marshall, & Coltheart, 1985). Secondly, additional acquired-dyslexic syndromes were defined and interpreted in relation to models of normal reading (phonological dyslexia, for example—see Beauvois and Derouesné, 1979, and Shallice and Warrington, 1980); and subsequently syndromes of impaired spelling were also defined and related to models of normal spelling (e.g., Beauvois & Derouesné, 1981; Bub & Kertesz, 1982; Ellis, 1982, 1984; Hatfield & Patterson, 1983; Shallice, 1981).
There can be no doubt that the fractionation of “acquired dyslexia” and of “acquired dysgraphia” into specific syndromes, and the efforts to interpret these syndromes in relation to models of normal reading and spelling, have allowed considerable progress to be made in our understanding of normal and abnormal processes in reading and spelling. But it has also become clear that the syndrome approach is basically a ground-clearing exercise that needs to be supplanted once initial progress has been made.
The reasons for this are perhaps easiest to illustrate with respect to the basic syndromes of acquired dyslexia—deep, surface, and phonological dyslexia. A central symptom of deep dyslexia is the semantic error—the patient, in a single-word reading task, reads admiral as “colonel,” forest as “trees,” or turtle as “crocodile.” How are we to explain such errors? One possibility is semantic damage: perhaps the semantic component of the language-processing system is degraded in such a way that relatively specific semantic details such as those which distinguish admiral from colonel, or turtle from crocodile, can no longer be used. An alternative possibility is a difficulty of access to names: the patient cannot produce the name “turtle,” so, instead of simply not responding, chooses something semantically close to the name he cannot find.
Picture-word matching tasks allow us to distinguish between these two possibilities. The deep dyslexic patient is given the word turtle, with pictures of a turtle, a crocodile, and some unrelated object such as a table, and is asked to point to the picture that matches the word. If there is semantic damage in deep dyslexia, errors in picture choice will occur. The patient will never point to table, but will sometimes choose crocodile, since he will not always know whether the word he is looking at is turtle or crocodile. If the reading-aloud problem is instead one of name retrieval, the picture-word matching task will not yield errors. So, do deep dyslexics make errors in this kind of picture-word matching task?
Some (e.g., G.R.—Newcombe & Marshall, 1980) do. Others (e.g., P.W. and D.E.—Patterson & Besner, 1985) do not. The conclusion seems inescapable: for some deep dyslexics the semantic errors are caused by semantic impairment whereas for others they are not. So, is there no single answer to the question “What is the cause of semantic errors in deep dyslexia?” More generally, is there no justification for using one deep dyslexic patient to study an entity, a syndrome known as “deep dyslexia,” since there is no guarantee that any one patient will be representative of all?
Surface dyslexia provides the same kind of example. Suppose we find a patient who in oral reading of single words makes frequent regularisation errors such as reading broad as “brode,” pint to rhyme with “mint,” or quay as “kway.” How are we to explain such errors? It seems obvious that the words are not being processed lexically—i.e., word-specific information is not being accessed—so the patients have to read aloud non-lexically, by rules relating orthographic units to phonological units. But at what stage is lexical processing defective? One possibility is that these irregular words are not being recognised as words and so not gaining access to the lexical system at all. Another possibility is that the pronunciations of the words are inaccessible at an output stage (even though the words have been recognised correctly at a lexical input stage), so if a pronunciation is required it can only be produced by non-lexical rules.
Tests of comprehension allow us to distinguish between these two possibilities. If the problem is at a lexical input stage, the surface dyslexic will fail to comprehend a word like quay as well as failing to read it aloud correctly. If the problem is at a lexical output stage, the patient will understand the word even though misreading it. The question is thus: when surface dyslexics misread an irregular word, do they always also misunderstand it?
Some (e.g., C.D.—Coltheart, Masterson, Byng, Prior, & Riddoch, 1983) do. Others (e.g., E.S.T.—Kay & Patterson, 1985) do not. The conclusion seems inescapable: for some surface dyslexics, the failure of lexical processing always arises at a lexical input stage, whereas for others the failure can be at a lexical output stage. So there is no single answer to the question “Where is the lexical-processing deficit in surface dyslexia?” More generally, there is no justification for treating surface dyslexia as a homogeneous syndrome.
Phonological dyslexia—an impairment in the reading aloud of non-words—provides the same kind of example. Firstly, there may be at least three different sources of the non-word reading impairment. For some patients it is at an orthographic analysis stage of the non-word reading process (e.g., M.S.—Newcombe & Marshall, 1985). For others it is at the stage of assigning phonemes to graphemes (e.g., W.B.—Funnell, 1983a). For yet others it is at a phonological assembly stage (e.g., M.V.—Bub, Black, Howell, & Kertesz, this volume). Secondly, the lexical processing system, whilst functioning well enough in phonological dyslexia to permit words to be read aloud well, may nevertheless be damaged in various ways in various patients (e.g., W.B.’s semantic system was impaired) or may be intact. Thus phonological dyslexia is a heterogeneous condition even though all patients assigned this label have in common poor non-word reading and good word reading.
Other examples of syndrome dissolution are provided in this book’s final chapter by Ellis, who argues that the cognitive neuropsychology of language is now at a stage where the syndrome approach is no longer a useful one. His arguments have to do with acquired language disorders. In contrast, it may well be the case that the study of developmental disorders of language has not yet reached the stage where it would be profitable to abandon the syndrome approach. Indeed, Seymour in Chapter 16 shows that progress can be made in understanding developmental dyslexia by distinguishing subtypes—that is, syndromes—of developmental dyslexia, such as developmental phonological dyslexia. Future work may reveal that developmental phonological dyslexia is itself a heterogeneous condition, and eventually it may become clear that a policy of assigning individual cases to syndrome categories is no longer paying off. But before this stage could be reached we will need to know more about the syndrome of developmental dyslexia, and further progress will need to be made in developing a model of learning to read that is sufficiently detailed and explicit that it can conveniently be used for interpreting individual cases of developmental dyslexia.
Sufficiently detailed and explicit models of skilled language processing, of course, do now exist—at least for processing at the single-word level—and it is because of their availability that cognitive neuropsychology can move beyond the syndrome approach in the study of acquired language disorders. Figure 1 (reproduced from Chapter 13 in this book) illustrates one such model, which is intended to describe a functional architecture for the language-processing system, i.e. to describe the processes involved in the production and the reception of written and spoken single words and non-words. This model is sufficiently general that most of the contributors to this book would be willing to adopt, or at least to countenance, something like it; yet it is specific enough to provide a useful framework within which to discuss all of the chapters of the book—at least those chapters which are mainly concerned with processing at the single-word level. Each of these chapters can thus be thought of as providing information about particular regions of the model as it is set out in Fig. 1.1.
PROCESSING SINGLE WORDS AND NON-WORDS
Visual and Auditory Input Processing
In any model of the kind represented by Fig. 1.1, initial lexical processing of speech or print is mediated by word-recognition devices, one for spoken words and one for printed words. These are labelled “Auditory Input Lexicon” and “Orthographic Input Lexicon” for generality. Different people have proposed different specific ideas about the nature of these devices, such as the logogen model (e.g., Morton & Patterson, 1980) or the cohort model of auditory word recognition, summarised in Chapter 7.
The nature of the input to these word-recognition devices (that is, what the components of Fig. 1.1 labelled “Orthographic Analysis” and “Acoustic Analysis” actually do) has been a somewhat neglected theoretical topic. As far as visual word recognition is concerned, the most explicit proposal concerning input to this device is that it takes the form of abstract letter identities (Coltheart, 1981; Johnston & McClelland, 1980). On this view, a printed word is first processed by a feature analysis system, and the output of this system is passed on to a system of letter identifiers, which are abstract in the sense that a single identifer responds to all fonts and cases of a particular letter—the same detector, for example, is used to identify A and a. An alternative arrangement which would have the same effect would be to have separate A and a detectors which generate identical output.
Once abstract identities have been assigned to all the letters in the input string, these identities are transmitted to the Orthographic Input Lexicon system to permit the word to be identified. Figure 2.1 in Chapter 2 illustrates precisely this approach to the question of what the input is to the Orthographic Input Lexicon. Chapter 2 also provides some evidence that this approach cannot be correct—or, rather, that it is at best only part of the story.
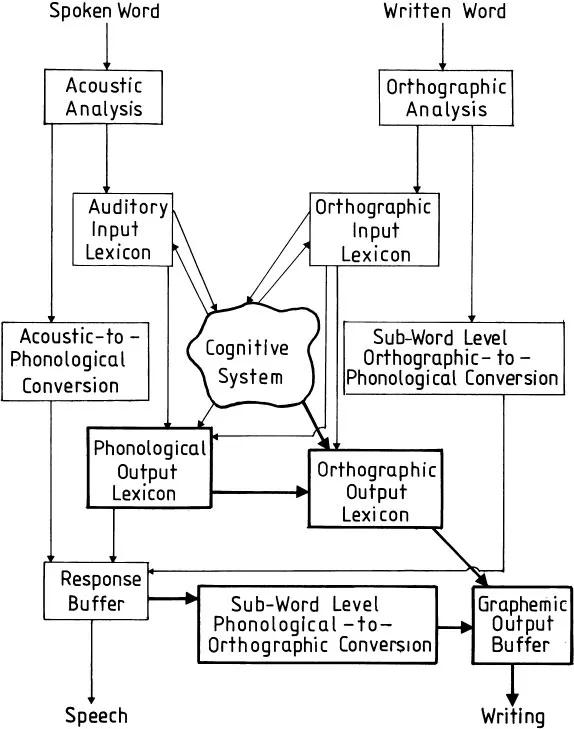
FIG. 1.1 A simple process model for the recognition, comprehension and production of spoken and written words and non-words. (Reproduced from Chapter 13 of this volume.)
Patient T.M., described by Howard in Chapter 2, was unlike most patients with acquired dyslexia in that he was very poor at one of the most elementary reading tasks, cross-case matching. He was at chance, for example, in tasks such as selecting which of the printed letters B, K, D, P corresponds to the printed target b. This task is normally used to assess whether the abstract letter identifiers are functioning normally, and so T.M.’s inability to perform the task at all implies that he could not carry out abstract letter identification at all. However, his ability to read words was by no means entirely abolished: he generally read correctly between 30% and 40% of words given to him in tests of single-word reading. Howard suggests that this is because there is not one but two sources of input to the Orthographic Input Lexicon. The first source is abstract letter identities as discussed above: this source is abolished in T.M. The second source is not easily characterised, but must make use of such features of words as idiosyncratic shapes, or must treat words globally in some fashion. This source of input will not permit word identification to be very precise, but will allow at least some degree of correct identification even when the precise system, the one based on abstract letter identification, cannot be used.
Howard also suggests that the global or feature-based input may well be precise enough to be useful when there are strong contextual constraints—as in reading continuous text, where word identification may often simply be a matter of confirming expectations. Seymour, in Chapter 16, proposes a similar two-component theory of input to the Orthographic Input Lexicon in the context of a discussion of the earliest stages of learning to read. His view is that the global or feature-based input system is what is used when children have just learned to read a few words.
The Orthographic Analysis component of Fig. 1.1 is used not only when the input is a printed word, but also when it is a print...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- List of Contributors
- Preface
- 1. Functional Architecture of the Language-Processing System
- 2. Reading Without Letters?
- 3. Direct-Route Reading and the Locus of Lexical Decision
- 4. Speech Output Processes and Reading
- 5. Impairments of Semantic Processing: Multiple Dissociations
- 6. Contrasting Patterns of Sentence Comprehension Deficits in Aphasia
- 7. Spoken Language Comprehension in Aphasia: A Real-Time Processing Perspective
- 8. Patterns of Speech Production Deficit Within and Across Aphasia Syndromes: Application of a Psycholinguistic Model
- 9. Grammatical Disturbances of Speech Production
- 10. Symptom Co-Occurrence and Dissociation in the Interpretation of Agrammatism
- 11. The Role of the Phoneme-to-Grapheme Conversion System and of the Graphemic Output Buffer in Writing
- 12. Speech and Writing Errors in “Neologistic Jargonaphasia”: A Lexical Activation Hypothesis
- 13. Speak and Spell: Dissociations and Word-Class Effects
- 14. Is There More Than Ah-oh-oh? Alternative Strategies for Writing and Repeating Lexically
- 15. Phonemic Deafness in Infancy and Acquisition of Written Language
- 16. Developmental Dyslexia: A Cognitive Experimental Analysis
- 17. Intimations of Modularity, or, the Modelarity of Mind: Doing Cognitive Neuropsychology Without Syndromes
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access The Cognitive Neuropsychology of Language (Psychology Revivals) by Max Coltheart, Giuseppe Sartori, Remo Job, Max Coltheart,Giuseppe Sartori,Remo Job in PDF and/or ePUB format, as well as other popular books in Psychology & Cognitive Neuroscience & Neuropsychology. We have over 1.5 million books available in our catalogue for you to explore.