Learn how to process and analysis data using Python Key Features
The book has theories explained elaborately along with Python code and corresponding output to support the theoretical explanations. The Python codes are provided with step-by-step comments to explain each instruction of the code.
The book is not just dealing with the background mathematics alone or only the programs but beautifully correlates the background mathematics to the theory and then finally translating it into the programs.
A rich set of chapter-end exercises are provided, consisting of both short-answer questions and long-answer questions.
Description This book introduces the fundamental concepts of Data Science, which has proved to be a major game-changer in business solving problems. Topics covered in the book include fundamentals of Data Science, data preprocessing, data plotting and visualization, statistical data analysis, machine learning for data analysis, time-series analysis, deep learning for Data Science, social media analytics, business analytics, and Big Data analytics. The content of the book describes the fundamentals of each of the Data Science related topics together with illustrative examples as to how various data analysis techniques can be implemented using different tools and libraries of Python programming language. Each chapter contains numerous examples and illustrative output to explain the important basic concepts. An appropriate number of questions is presented at the end of each chapter for self-assessing the conceptual understanding. The references presented at the end of every chapter will help the readers to explore more on a given topic. What will you learn
Perform processing on data for making it ready for visual plot and understand the pattern in data over time.
Understand what machine learning is and how learning can be incorporated into a program.
Know how tools can be used to perform analysis on big data using python and other standard tools.
Perform social media analytics, business analytics, and data analytics on any data of a company or organization.
Who this book is for The book is for readers with basic programming and mathematical skills. The book is for any engineering graduates that wish to apply data science in their projects or wish to build a career in this direction. The book can be read by anyone who has an interest in data analysis and would like to explore more out of interest or to apply it to certain real-life problems. Table of Contents 1. Fundamentals of Data Science1 2. Data Preprocessing 3. Data Plotting and Visualization 4. Statistical Data Analysis 5. Machine Learning for Data Science 6. Time-Series Analysis 7. Deep Learning for Data Science 8. Social Media Analytics 9. Business Analytics 10. Big Data Analytics About the Author Dr. Gypsy Nandi is an Assistant Professor (Sr) in the Department of Computer Applications, Assam Don Bosco University, India. Her areas of interest include Data Science, Social Network Mining, and Machine Learning. She has completed her Ph.D. in the field of 'Social Network Analysis and Mining'. Her research scholars are currently working mainly in the field of Data Science. She has several research publications in reputed journals and book series. Dr. Rupam Kumar Sharma is an Assistant Professor in the Department of Computer Applications, Assam Don Bosco University, India. His area of interest includes Machine Learning, Data Analytics, Network, and Cyber Security. He has several research publications in reputed SCI and Scopus journals.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
“The goal is to turn data into information, and information into insight”
— Carly Fiorina
Data, in today’s technology-driven world, is vital in decision making. The rate at which data is being generated per day is tremendous. Every company is using data to comprehend their customers better. Data science and data analytics can gain meaningful insights that help companies in identifying possible areas of growth, streamlining of costs, better product opportunities, and effective company decisions. Data analysis can bring an impact in every sector, be it healthcare, medicine, stock market, academic institutes, and so on. Undoubtedly, data will keep growing in momentum for the next few decades and for this, IT jobs are monotonically expanding to deal with the bulk amount of Big Data that has been realized as the need of the hour in data analysis.
This chapter elaborately discusses data science which is one of the most demanding careers in the 21st century. The world of data science may comprise of simple tasks such as estimating the sales of products in the coming year and viewing the trend of products in the market,or many complex tasks such as prediction of disease based on complex neural network model and classifying and recommending products based on fuzzy logic theory. John Wills, the Director of Data Engineering at Slack, has defined a data scientist as a Person who is better at statistics than any software engineer and better at software engineering than any statistician. Thus, data scientist plays a pivotal role in data analysis which is currently a very demanding area of study that is being explored at an exponential growth to gain hidden insights for better decision making.
Structure
The next few sections in this chapter will discuss the following topics:
Introduction to data science
Why learn data science?
Data analytics lifecycle
Types of data analysis
Types of jobs in business analytics
Data science tools
Fundamental areas of study in data science
Role of SQL in data science
Pros and cons of data science
Conclusion
References
Points to remember
Exercises
Objectives
After studying this chapter, you should be able to:
Understand the concept and need for data science.
Discuss the various phases in the data analytics lifecycle.
Learn the various types of data analytics and the important tools applied in data science.
Analyze the fundamental areas of study in data science
1.1. Introduction to data science
Data science is the task of scrutinizing and processing raw data to reach a meaningful conclusion. Data is mined and classified to detect and study behavioral data and patterns, and the techniques used for this may vary according to the requirements. All data that is available for analysis can be classified into four types. They are nominal data, ordinal data, interval data, and ratio data. A common useful acronym used for these four types of data is NOIR (Nominal Ordinal Interval Ratio), which means black in French. A detailed description of each of these types of data is provided in Chapter 2: Data Preprocessing.
For data collection, there are two major sources of data – primary and secondary. Primary data is data that is never collected before and can be gathered in a variety of ways such as, participatory or non-participatory observation, conducting interviews, collecting data through questionnaires or schedules, and so on. Secondary data, on the other hand, is data that is already gathered and can be accessed and used by other users easily. Secondary data can be from existing case studies, government reports, newspapers, journals, books and also from many popular dedicated websites that provide several datasets. Few standard popular websites for downloading datasets include the UCI Machine Learning Repository, the Kaggle datasets, IMDB datasets, and Stanford Large Network Dataset Collection. Though there are clear benefits of using readily available secondary data, it must be however verified as to how authenticated and valid such data is.
It is said that we all are data analysts in varying degrees of our everyday lives. We analyze the need and working principle of an electronic gadget before purchasing it, or we predict the demand of a particular course for the next few years in terms of job prospects before enrolling our children in that particular course. We do not need to be an exceptionally good expert in analytics to do analysis. The need for complex data analysis has been immensely felt over these years in main business sectors and companies to discover historical patterns for improving the performance of the business in the future.
1.2. Why learn data science?
There has been a revolutionary change in the behavioral pattern of customers in case of online purchases, stock market investment, advertising products to other customers, and so on. Each of these activities requires an in-depth analysis of existing relevant data which makes data science a promising field of study in today’s fast-growing data-driven world.
Few of the industry verticals where data science has found its prominence and is used for operational and strategic decision making are discussed below:
Ecommerce: Ecommerce sites hugely involve data science for maximizing revenue and profitability. These sites analyze the shopping and purchasing behavior of customers and accordingly recommend products to customers for more purchases online.
Finance: The finance market is an emerging field in the data industry. The financial analytics market takes care of risk analysis, fraud detection, shareholders’upcoming share status, working capital management, and so on.
Retail: Retail industries take care of a 360-degree view and feedback reviews of customers. The retail analytics market analyzes customers’ purchasing trends and demands in order to get products based on customers’ liking. Retail industries involve data science for optimal pricing, personalized offers, better marketing strategies, market basket analysis, stock management, and so on.
Healthcare: The healthcare sector also nowadays heavily relies on analytics of patient data to predict diseases and health issues. Healthcare industries make an analysis of data-driven patient quality care, improved patient care, classification of the type of symptoms of patients and predicted health deficiencies, and so on.
Education: The sources of data in education is vast, starting from student-centric data, enrollment in various courses, scholarship and fee details, examination results, and so on. Education analytics play a major role in academic institutions for better admission scenario, empowerment of students for successful examination results, and all-round student performance.
Human Resource (HR): HR analytics involves HR-related data that can be used for building strong leadership, employee acquisition, employee retention, workforce optimization, and performance management.
Sports: Nowadays, sports analytics is often used in international tournaments to analyze the performance of players, the predicted scores, prevention of injuries, and the possibility of winning or losing a match by a particular team.
The use of data science is nowadays found in every prominent domain, few of which have been addressed above. The few other sectors that need a mention are telecom industries, sales, supply chain management, risk monitoring, manufacturing industries, and IT companies. The recent competitions in businesses and companies consider data science no longer as an optional requirement but rather hire data analysts and data scientists for the same to deal with hidden massive data to provide meaningful results and generate reports to arrive at profit-making decisions. Also, the recent trends in the job market show that data analysts, data scientists, and data engineers have a huge demand in the IT companies and this demand will continue for the next decade. Hence, making data analyst, data scientist, or data engineer as a career can uplift your job profile and the demand will be witnessed in many companies in the years to come.
1.3. Data analytics lifecycle
While the terms data science and data analytics are often used interchangeably, the two terms are quite different based on the difference in the scope of their performances. Data science is an umbrella term that comprises a large variety of fields compared to data analytics which is more focused and can be considered to be a subset of data science. Hence to understand data science thoroughly, let us first try to understand the various phases in the data analytics lifecycle.
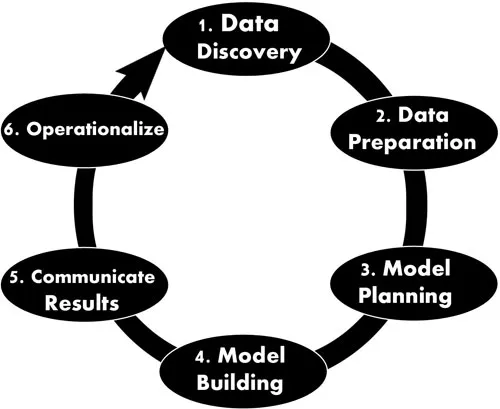
Data analytics involves mainly six important phases that are carried out in a cycle - data discovery, data preparation, planning of data models, the building of data models, communication of results, and operationalization. Figure 1.1 illustrates the six phases of the data analytics lifecycle that is followed one phase after another to complete one cycle. It is interesting to note that these six phases of data analytics can follow both forward and backward movement between each phase and are iterative. The lifecycle of the data analytics provides a framework for the best performances of each phase from the creation of the project until its completion. This framework was built by a large team of data scientists with much care and experiments. The key stakeholders in data science projects are business analysts, data engineers, database administrators, project managers, executive project sponsors, and data scientists.
Figure 1.1: The Data Analytics Life Cycle
Let us now briefly discuss all the six phases of the data analytics lifecycle followed in any data science projects:
1.3.1. Data discovery
In this first phase of data analytics, the stakeholders regularly perform the following tasks - examine the business trends, make case studies of similar data analytics, and study the domain of the business industry. The entire team makes an assessment of the in-house resources, the in-house infrastructure, total time involved, and technology requirements. Once all these assessments and evaluations are completed, the stakeholders start formulating the initial hypothesis for resolving all business challenges in terms of the current market scenario.
1.3.2. Data preparation
In the second phase after the data discovery phase, data is prepared by transforming it from a legacy system into a data analytics form by using the sandbox platform. A sandbox is a scalable platform commonly used by the data scientists for data preprocessing. It includes huge CPUs, high capacity storage and high I/O capacity. The IBM Netezza 1000 is one such data sandbox platform used by the IBM Company for handling data marts. The stakeholders involved during this phase are mostly involved in the preprocessing of data for preliminary results by using a standard sandbox platform.
1.3.3. Model planning
The third phase of the lifecycle is model planning, where the data analytics team makes proper planning of the methods to be adapted and the various workflow to be followed during the next phase of model building. At this stage, the various division of work among the team is decided to clearly define the workload among the team members. The data prepared in the previous phase is further explored to understand the various features and their relationships and also perform feature selection for applying it to the model.
1.3.4. Model building
The next phase of the lifecycle is model building in which the team works on developing datasets for training and testing as well as for production purposes. Also, the execution of the model, based on the planning made in the previous phase, is carried out. The kind of environment needed for execution of the model is decided and prepared so that if a more robust environment is required, it is accordingly applied.
1.3.5. Communicate results
Phase five of the life cycle checks the results of the project to find whether it is a success or failure. The result is scrutinized by the entire team along with its stakeholders to draw inferences on the key findings and summarize the entire work done. Also, the business values are quantified and an elaborate narrative on the key findings is prepared that is discussed among the various stakeholders.
1.3.6. Operationalization
In phase six, a final report is prepared by the team along with the briefings, source codes, and related documents. The last phase also involves running the pilot project to implement the model and test it in a real-time environment. As data analytics help build models that lead to better decision making, it, in turn, adds values to individuals, customers, business sectors and other organizations. While proceeding through theses six phases, the various stakeholders that can be involved in the planning, implementation, and decision-making are data analysts, business in...
Table of contents
Cover Page
Title Page
Copyright Page
Dedication
About the Authors
Acknowledgement
Preface
Errata
Table of Contents
1. Fundamentals of Data Science
2. Data Preprocessing
3. Data Plotting and Visualization
4. Statistical Data Analysis
5. Machine Learning for Data Science
6. Time-Series Analysis
7. Deep Learning for Data Science
8. Social Media Analytics
9. Business Analytics
10. Big Data Analytics
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Science Fundamentals and Practical Approaches by Rupam Kumar Sharma,Kapil Jain in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Processing. We have over 1.5 million books available in our catalogue for you to explore.