A beginner's guide to simplifying Extract, Transform, Load (ETL) processes with the help of hands-on tips, tricks, and best practices, in a fun and interactive wayKey Features• Explore data wrangling with the help of real-world examples and business use cases• Study various ways to extract the most value from your data in minimal time• Boost your knowledge with bonus topics, such as random data generation and data integrity checksBook DescriptionWhile a huge amount of data is readily available to us, it is not useful in its raw form. For data to be meaningful, it must be curated and refined.If you're a beginner, then The Data Wrangling Workshop will help to break down the process for you. You'll start with the basics and build your knowledge, progressing from the core aspects behind data wrangling, to using the most popular tools and techniques.This book starts by showing you how to work with data structures using Python. Through examples and activities, you'll understand why you should stay away from traditional methods of data cleaning used in other languages and take advantage of the specialized pre-built routines in Python. Later, you'll learn how to use the same Python backend to extract and transform data from an array of sources, including the internet, large database vaults, and Excel financial tables. To help you prepare for more challenging scenarios, the book teaches you how to handle missing or incorrect data, and reformat it based on the requirements from your downstream analytics tool.By the end of this book, you will have developed a solid understanding of how to perform data wrangling with Python, and learned several techniques and best practices to extract, clean, transform, and format your data efficiently, from a diverse array of sources.What you will learn• Get to grips with the fundamentals of data wrangling• Understand how to model data with random data generation and data integrity checks• Discover how to examine data with descriptive statistics and plotting techniques• Explore how to search and retrieve information with regular expressions• Delve into commonly-used Python data science libraries• Become well-versed with how to handle and compensate for missing dataWho this book is forThe Data Wrangling Workshop is designed for developers, data analysts, and business analysts who are looking to pursue a career as a full-fledged data scientist or analytics expert. Although this book is for beginners who want to start data wrangling, prior working knowledge of the Python programming language is necessary to easily grasp the concepts covered here. It will also help to have a rudimentary knowledge of relational databases and SQL.

- 576 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
The Data Wrangling Workshop
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
InformatiqueSubtopic
Traitement des données1. Introduction to Data Wrangling with Python
Overview
This chapter will help you understand the importance of data wrangling in data science. You will gain practical knowledge of how to manipulate the data structures that are available in Python by comparing the different implementations of the built-in Python data structures. Overall, this chapter describes the importance of data wrangling, identifies the important tasks to be performed in data wrangling, and introduces basic Python data structures. By the end of this chapter, you will be adept at working with lists, sets, and dictionaries, which are the key building blocks of data structures in Python.
Introduction
Since data science and analytics have become key parts of our lives, the role of a data scientist has become even more important. Finding the source of data is an essential part of data science; however, it is the science part that makes you – the practitioner – truly valuable.
To practice high-quality science with data, you need to make sure it is properly sourced, cleaned, formatted, and pre-processed. This book will teach you the most essential basics of this invaluable component of the data science pipeline: data wrangling. In short, data wrangling is the process that ensures that the data is being presented in a way that is clean, accurate, formatted, and ready to be used for data analysis.
A prominent example of data wrangling with a large amount of data is the analysis conducted at the Supercomputer Center of the University of California San Diego (UCSD) every year. Wildfires are very common in California and are caused mainly by the dry weather and extreme heat, especially during the summers. Data scientists at the UCSD Supercomputer Center run an analysis every year and gather data to predict the nature and spread direction of wildfires in California. The data comes from diverse sources, such as weather stations, sensors in the forest, fire stations, satellite imagery, and Twitter feeds. However, this data might be incomplete or missing.
After collecting the data from various sources, if it is not cleaned and formatted using ways including scaling numbers and removing unwanted characters in strings, it could result in erroneous data. In cases where we might get a flawed analysis, we might need to reformat the data from JavaScript Object Notation (JSON) into Comma Separated Value (CSV); we may also need the numbers to be normalized, that is, centered and scaled with relation to themselves. Processing data in such a way might be required when we feed data to certain machine learning models.
This is an example of how data wrangling and data science can prove to be helpful and relevant. This chapter will discuss the fundamentals of data wrangling. Let's get started.
Importance of Data Wrangling
A common mantra of the modern age is Data is the New Oil, meaning data is now a resource that's more valuable than oil. But just as crude oil does not come out of the rig as gasoline and must be processed to get gasoline and other products, data must be curated, massaged, or cleaned and refined to be used in data science and products based on data science. This is known as wrangling. Most data scientists spend the majority of their time data wrangling.
Data wrangling is generally done at the very first stage of a data science/analytics pipeline. After the data scientists have identified any useful data sources for solving the business problem at hand (for instance, in-house database storage, the internet, or streaming sensor data such as an underwater seismic sensor), they then proceed to extract, clean, and format the necessary data from those sources.
Generally, the task of data wrangling involves the following steps:
- Scraping raw data from multiple sources (including web and database tables)
- Imputing (replacing missing data using various techniques), formatting, and transforming – basically making it ready to be used in the modeling process (such as advanced machine learning)
- Handling read/write errors
- Detecting outliers
- Performing quick visualizations (plotting) and basic statistical analysis to judge the quality of formatted data
The following is an illustrative representation of the positioning and the essential functional role of data wrangling in a typical data science pipeline:
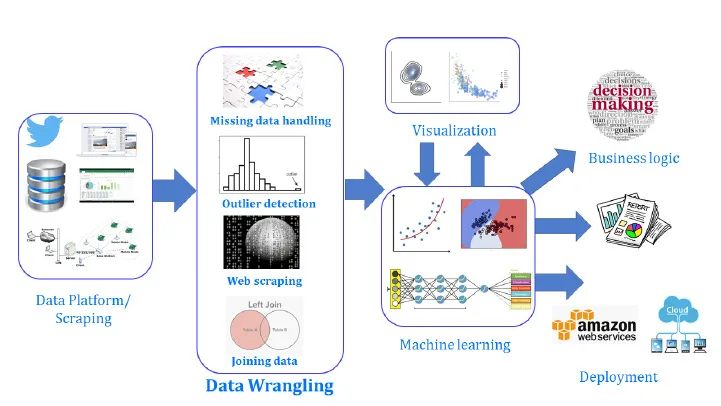
Figure 1.1: Process of data wrangling
The process of data wrangling includes finding the appropriate data that's necessary for the analysis. Often, analysis is exploratory, so there is not enough scope. You often need to do data wrangling for this type of analysis to be able to understand your data better. This could lead to more analysis or machine learning.
This data can be from one or multiple sources, such as tweets, bank transaction statements in a relational database, sensor data, and so on. This data needs to be cleaned. If there is missing data, we will either delete or substitute it, with the help of several techniques. If there are outliers, we need to detect them and then handle them appropriately. If the data is from multiple sources, we will have to combine it using Structured Query Language (SQL) operations like JOIN.
In an extremely rare situation, data wrangling may not be needed. For example, if the data that's necessary for a machine learning task is already sto...
Table of contents
- The Data Wrangling Workshop
- Preface
- 1. Introduction to Data Wrangling with Python
- 2. Advanced Operations on Built-In Data Structures
- 3. Introduction to NumPy, Pandas, and Matplotlib
- 4. A Deep Dive into Data Wrangling with Python
- 5. Getting Comfortable with Different Kinds of Data Sources
- 6. Learning the Hidden Secrets of Data Wrangling
- 7. Advanced Web Scraping and Data Gathering
- 8. RDBMS and SQL
- 9. Applications in Business Use Cases and Conclusion of the Course
- Appendix
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access The Data Wrangling Workshop by Brian Lipp,Shubhadeep Roychowdhury,Dr. Tirthajyoti Sarkar in PDF and/or ePUB format, as well as other popular books in Informatique & Traitement des données. We have over 1.5 million books available in our catalogue for you to explore.