
eBook - ePub
Entity Information Life Cycle for Big Data
Master Data Management and Information Integration
- 254 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Entity Information Life Cycle for Big Data
Master Data Management and Information Integration
About this book
Entity Information Life Cycle for Big Data walks you through the ins and outs of managing entity information so you can successfully achieve master data management (MDM) in the era of big data. This book explains big data's impact on MDM and the critical role of entity information management system (EIMS) in successful MDM. Expert authors Dr. John R. Talburt and Dr. Yinle Zhou provide a thorough background in the principles of managing the entity information life cycle and provide practical tips and techniques for implementing an EIMS, strategies for exploiting distributed processing to handle big data for EIMS, and examples from real applications. Additional material on the theory of EIIM and methods for assessing and evaluating EIMS performance also make this book appropriate for use as a textbook in courses on entity and identity management, data management, customer relationship management (CRM), and related topics.
- Explains the business value and impact of entity information management system (EIMS) and directly addresses the problem of EIMS design and operation, a critical issue organizations face when implementing MDM systems
- Offers practical guidance to help you design and build an EIM system that will successfully handle big data
- Details how to measure and evaluate entity integrity in MDM systems and explains the principles and processes that comprise EIM
- Provides an understanding of features and functions an EIM system should have that will assist in evaluating commercial EIM systems
- Includes chapter review questions, exercises, tips, and free downloads of demonstrations that use the OYSTER open source EIM system
- Executable code (Java .jar files), control scripts, and synthetic input data illustrate various aspects of CSRUD life cycle such as identity capture, identity update, and assertions
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
InformatikSubtopic
InformationsmanagementChapter 1
The Value Proposition for MDM and Big Data
Abstract
This chapter gives a definition of master data management (MDM) and describes how it generates value for organizations. It also provides an overview of Big Data and the challenges it brings to MDM.
Keywords
Master data; master data management; MDM; Big Data; reference data management; RDMDefinition and Components of MDM
Master Data as a Category of Data
Modern information systems use four broad categories of data including master data, transaction data, metadata, and reference data. Master data are data held by an organization that describe the entities both independent and fundamental to the organization’s operations. In some sense, master data are the “nouns” in the grammar of data and information. They describe the persons, places, and things that are critical to the operation of an organization, such as its customers, products, employees, materials, suppliers, services, shareholders, facilities, equipment, and rules and regulations. The determination of exactly what is considered master data depends on the viewpoint of the organization.
If master data are the nouns of data and information, then transaction data can be thought of as the “verbs.” They describe the actions that take place in the day-to-day operation of the organization, such as the sale of a product in a business or the admission of a patient to a hospital. Transactions relate master data in a meaningful way. For example, a credit card transaction relates two entities that are represented by master data. The first is the issuing bank’s credit card account that is identified by the credit card number, where the master data contains information required by the issuing bank about that specific account. The second is the accepting bank’s merchant account that is identified by the merchant number, where the master data contains information required by the accepting bank about that specific merchant.
Master data management (MDM) and reference data management (RDM) systems are both systems of record (SOR). A SOR is “a system that is charged with keeping the most complete or trustworthy representation of a set of entities” (Sebastian-Coleman, 2013). The records in an SOR are sometimes called “golden records” or “certified records” because they provide a single point of reference for a particular type of information. In the context of MDM, the objective is to provide a single point of reference for each entity under management. In the case of master data, the intent is to have only one information structure and identifier for each entity under management. In this example, each entity would be a credit card account.
Metadata are simply data about data. Metadata are critical to understanding the meaning of both master and transactional data. They provide the definitions, specifications, and other descriptive information about the operational data. Data standards, data definitions, data requirements, data quality information, data provenance, and business rules are all forms of metadata.
Reference data share characteristics with both master data and metadata. Reference data are standard, agreed-upon codes that help to make transactional data interoperable within an organization and sometimes between collaborating organizations. Reference data, like master data, should have only one system of record. Although reference data are important, they are not necessarily associated with real-world entities in the same way as master data. RDM is intended to standardize the codes used across the enterprise to promote data interoperability.
Reference codes may be internally developed, such as standard department or building codes or may adopt external standards, such as standard postal codes and abbreviations for use in addresses. Reference data are often used in defining metadata. For example, the field “BuildingLocation” in (or referenced by) an employee master record may require that the value be one of a standard set of codes (system of reference) for buildings as established by the organization. The policies and procedures for RDM are similar to those for MDM.
Master Data Management
In a more formal context, MDM seems to suffer from lengthy definitions. Loshin (2009) defines master data management as “a collection of best data management practices that orchestrate key stakeholders, participants, and business clients in incorporating the business applications, information management methods, and data management tools to implement the policies, procedures, services, and infrastructure to support the capture, integration, and shared use of accurate, timely, consistent, and complete master data.” Berson and Dubov (2011) define MDM as the “framework of processes and technologies aimed at creating and maintaining an authoritative, reliable, sustainable, accurate, and secure environment that represents a single and holistic version of the truth for master data and its relationships…”
These definitions highlight two major components of MDM as shown in Figure 1.1. One component comprises the policies that represent the data governance aspect of MDM, while the other includes the technologies that support MDM. Policies define the roles and responsibilities in the MDM process. For example, if a company introduces a new product, the policies define who is responsible for creating the new entry in the master product registry, the standards for creating the product identifier, what persons or department should be notified, and which other data systems should be updated. Compliance to regulation along with the privacy and security of information are also important policy issues (Decker, Liu, Talburt, Wang, & Wu, 2013).
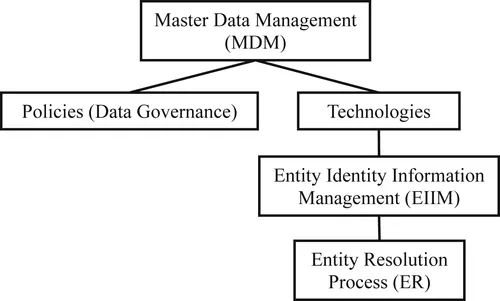
Figure 1.1 Components of MDM.
The technology component of MDM can be further divided into two major subcomponents, the entity resolution (ER) process and entity identity information management (EIIM).
Entity Resolution
The base technology is entity resolution (ER), which is sometimes called record linking, data matching, or de-duplication. ER is the process of determining when two information system references to a real-world entity are referring to the same, or to different, entities (Talburt, 2011). ER represents the “sorting out” process when there are multiple sources of information that are referring to the same set of entities. For example, the same patient may be admitted to a hospital at different times or through different departments such as inpatient and outpatient admissions. ER is the process of comparing the admission information for each encounter and deciding which admission records are for the same patient and which ones are for different patients.
ER has long been recognized as a key data cleansing process for removing duplicate records in database systems (Naumann & Herschel, 2010) and promoting data and information quality in general (Talburt, 2013). It is also essential in the two-step process of entity-based data integration. The first step is to use ER to determine if two records are referencing the same entity. This step relies on comparing the identity information in the two records. Only after it has been determined that the records carry information for the same entity can the second step in the process be executed, in which other information in the records is merged and reconciled.
Most de-duplication applications start with an ER process that uses a set of matching rules to link together into clusters those records determined to be duplicates (equivalent references). This is followed by a process to select one best example, called a survivor record, from each cluster of equivalent records. After the survivor record is selected, the presumed duplicate records in the cluster are discarded with only the single surviving records passing into the next process. In record de-duplication, ER directly addresses the data quality problem of redundant and duplicate data prior to data integration. In this role, ER is fundamentally a data cleansing tool (Herzog, Scheuren & Winkler, 2007). However, ER is increasingly being used in a broader context for two important reasons.
The first reason is that information quality has matured. As part of that, many organizations are beginning to apply a product model to their information management as a way of achieving and sustaining high levels of information quality over time (Wang, 1998). This is evidenced by several important developments of recent years, including the recognition of Sustaining Information Quality as one of the six domains in the framework of information quality developed by the International Association for Information and Data Quality (Yonke, Walenta & Talburt, 2012) as the basis for the Information Quality Certified Professional (IQCP) credential.
Another reason is the relatively recent approval of the ISO 8000-110:2009 standard for master data quality prompted by the growing interest by organizations in adopting and investing in master data management (MDM). The ISO 8000 standard is discussed in more detail in Chapter 11.
Entity Identity Information Management
Entity Identity Information Management (EIIM) is the collection and management of identity information with the goal of sustaining entity identity integrity over time (Zhou & Talburt, 2011a). Entity identity integrity requires that each entity must be represented in the system one, and only one, time, and distinct entities must have distinct representations in the system (Maydanchik, 2007). Entity identity integrity is a fundamental requirement for MDM systems.
EIIM is an ongoing process that combines ER and data structures representing the identity of an entity into specific operational configurations (EIIM configurations). When these configurations are all executed together, they work in concert to maintain the entity identity integrity of master data over time. EIIM is not limited to MDM. It can be applied to other types of systems and data as diverse as RDM systems, referent tracking systems (Chen et al., 2013a), and social media (Mahata & Talburt, 2014).
Identity information is a collection of attribute-value pairs that describe the characteristics of the entity – characteristics that serve to distinguish one entity from another. For example, a student name attribute with a value such as “Mary Doe” would be identity information. However, because there may be other students with the same name, additional identity information such as date-of-birth or home address may be required to fully disambiguate one student from another.
Although ER is necessary for effective MDM, it is not, in itself, sufficient to manage the life cycle of identity information. EIIM is an extension of ER in two dimensions, knowledge management and time. The knowledge management aspect of EIIM relates to the need to create, store, and maintain identity information. The knowledge structure created to represent a master data object is called an entity identity structure (EIS).
The time aspect of EIIM is to assure that an entity under management in the MDM system is consistently labeled with the same, unique identifier from process to process. This is only possible through an EIS that stores the identity information of the entity along with its identifier so both are available to future processes. Persistent entity identifiers are not inherently part of ER. At any given point in time, the only goal of an ER process is to correctly classify a set of entity references into clusters where all of the references in a given cluster reference the same entity. If these clusters are labeled, then the cluster label can serve as the identifier of the entity. Without also storing and carrying forward the identity information, the cluster identifiers assigned in a future process may be different.
The problem of changes in labeling by ER processes is illustrated in Figure 1.2. It shows three records, Records 1, 2, and 3, where Records 1 and 2 are equivalent references to one entity and Record 3 is a reference to a different entity. In the first ER run, Records 1, 2, and 3 are in a file with other records. In the second run, the same Records 1, 2, and 3 occur in context with a different set of records, or perhaps the same records that were in Run 1, but simply in a different order. In both runs the ER process consistently classifies Records 1 and 2 as equivalent and places Record 3 in a cluster by itself. The problem from an MDM standpoint is that the ER processes are not required to consistently label these clusters. In the first run, the cluster...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- Foreword
- Preface
- Acknowledgements
- Chapter 1. The Value Proposition for MDM and Big Data
- Chapter 2. Entity Identity Information and the CSRUD Life Cycle Model
- Chapter 3. A Deep Dive into the Capture Phase
- Chapter 4. Store and Share – Entity Identity Structures
- Chapter 5. Update and Dispose Phases – Ongoing Data Stewardship
- Chapter 6. Resolve and Retrieve Phase – Identity Resolution
- Chapter 7. Theoretical Foundations
- Chapter 8. The Nuts and Bolts of Entity Resolution
- Chapter 9. Blocking
- Chapter 10. CSRUD for Big Data
- Chapter 11. ISO Data Quality Standards for Master Data
- Appendix A. Some Commonly Used ER Comparators
- References
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Entity Information Life Cycle for Big Data by John R. Talburt,Yinle Zhou in PDF and/or ePUB format, as well as other popular books in Informatik & Informationsmanagement. We have over 1.5 million books available in our catalogue for you to explore.