
eBook - ePub
Intel Xeon Phi Processor High Performance Programming
Knights Landing Edition
- 662 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Intel Xeon Phi Processor High Performance Programming
Knights Landing Edition
About this book
Intel Xeon Phi Processor High Performance Programming is an all-in-one source of information for programming the Second-Generation Intel Xeon Phi product family also called Knights Landing. The authors provide detailed and timely Knights Landingspecific details, programming advice, and real-world examples. The authors distill their years of Xeon Phi programming experience coupled with insights from many expert customers — Intel Field Engineers, Application Engineers, and Technical Consulting Engineers — to create this authoritative book on theessentials of programming for Intel Xeon Phi products.
Intel® Xeon Phi™ Processor High-Performance Programming is useful even before you ever program a system with an Intel Xeon Phi processor. To help ensure that your applications run at maximum efficiency, the authors emphasize key techniques for programming any modern parallel computing system whether based on Intel Xeon processors, Intel Xeon Phi processors, or other high-performance microprocessors. Applying these techniques will generally increase your program performance on any system and prepareyou better for Intel Xeon Phi processors.
- A practical guide to the essentials for programming Intel Xeon Phi processors
- Definitive coverage of the Knights Landing architecture
- Presents best practices for portable, high-performance computing and a familiar and proven threads and vectors programming model
- Includes real world code examples that highlight usages of the unique aspects of this new highly parallel and high-performance computational product
- Covers use of MCDRAM, AVX-512, Intel® Omni-Path fabric, many-cores (up to 72), and many threads (4 per core)
- Covers software developer tools, libraries and programming models
- Covers using Knights Landing as a processor and a coprocessor
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Section II
Parallel Programming
Introduction
This section focuses on application programming with consideration for the scale of many-core. Chapter 7 discusses when code changes for parallelism can be an evolution versus a revolution. Chapter 8 covers tasks and threads with OpenMP and TBB in particular. Chapters 9–12 include an overview of many data parallel vectorization tools and techniques. Chapter 13 covers libraries. Chapter 14 discusses profiling tools and techniques including roofline estimation techniques and ways to pick which data structures to place in the MCDRAM. Chapter 15 covers MPI. Chapter 16 takes a look at a collection of “rising stars” that provide PGAS style programming — including OpenSHMEM, Coarray Fortran, and UPC. While these will not generally be the most efficient parallel programming techniques for Knights Landing, there is a lot of merit in exploring this space during the upcoming years starting with Knights Landing. Chapter 17 discusses the emerging benefits of parallel graphics rendering using Software-Defined Visualization libraries. Chapter 18 (Offload to Knights Landing) discusses offload style programming including programming details on how to offload to a Knights Landing coprocessor, or across the fabric to a Knights Landing processor. Chapter 18 is a “must read” if you have code that used Knights Corner offload methods, or if you will use Knights Landing in offload mode. We discuss “offload over fabric” which may be of interest for retaining offload code investments and maximizing application performance in clusters with a mix of multicore and many-core processors. Chapter 19 discusses Power Analysis on Knights Landing enabling insight into the growing emphasis on energy efficiency.
This book has three sections: I. Knights Landing, II. Parallel Programming, and III. Pearls. The book also has an extensive Glossary and Index to facilitate jumping around the book.
Chapter 7
Programming overview for Knights Landing
Abstract
Discusses the keys to effective parallel programming. While getting maximal performance from Knights Landing is largely the same challenge as with any processor, the challenge of parallel programming remains. The basics of managing parallelism at the domain, thread, data, and locality levels are discussed. The provocative “To Refactor, or Not to Refactor” question is examined.
Keywords
OpenMP; Threading building blocks; Vectorization; MPI; AVX-512 intrinsics; Code modernization
Programming Knights Landing should be approached as one would program any modern high-performance processor. Getting maximal performance from Knights Landing is largely the same challenge as with any processor, with added opportunity because the top performance is extremely high.
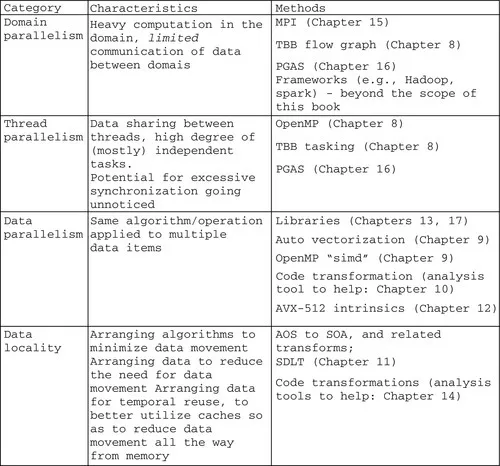
Breaking down the challenge of effective parallel programming can be done many ways. The National Energy Research Scientific Computing Center (NERSC), home to the Cori supercomputer based on Knights Landing, described the work as consisting of four elements:
▪ Manage Domain Parallelism
▪ Increase Thread Parallelism
▪ Exploit Data Parallelism
▪ Improve Data Locality
We could describe these casually as MPI, OpenMP/Threading Building Blocks (TBB), vectorization, and data layout and still capture the essence of the recommendations as it would be for most developers targeting Knights Landing. Of course, there are many variations on these. PGAS models (Chapter 16) may seem to blend elements. Keeping clear thinking about our approach for each element will help us manage the most expensive element of parallel computing: communication (moving data around).
We describe parallel programming, in terms of the four elements and their characteristics in Fig. 7.1. The first three elements address three key opportunities for parallelism in a modern machine: nodes, cores/threads, and vectors. The last element affects them all—attention to minimization of communication, that is, data movement.
To Refactor, or Not to Refactor, That Is the Question
“Code Modernization” is a term thrown around to encompass a wide range of activities we can do to update an application to make maximal use of today’s machines. There is not a hard and fast definition, but there is one question that is on everyone’s mind about “code modernization”: How much of my application do I need to change? Of course, the answer is “it depends.” Ultimately, the answer rests in whether an application needs to be refactored or not.
Factoring an application, and its algorithms, to decompose into three levels of parallelism is best done with data locality in mind. The proper factoring of an application is the very essence of parallel programming design. Poor factoring cannot be made up for by hard work within the confines of one level of parallelism.
The three biggest drivers for refactoring programs coincide with the largest changes that have occurred in the past few decades in supercomputers: massive growth in all levels of parallelism, and radical increases in computational performance without a corresponding improvement in the performance of memory systems and other data movement capabilities. The growth in parallelism motivates us to cleanly separate work to be done into activities that can run independently. Barriers, or other synchronizations, are the enemy of scaling (using more core/threads/vectors). The growing gap between processor and memory performance means that higher performance can be driven more by reductions in communication (data movement) than in reduction of computations. This can be at odds with many design decisions, including data layout, made in an era when computations were more important to eliminate than memory accesses. That day is long gone!
Evolutionary Optimization of Applications
A natural place to start is to examine if our program is open to optimization via an evolutionary approach, which does not require radical restructuring (refactoring). Fundamentally, we want to know whether this will reach an acceptable percentage of the capabilities of the machine. Fig. 7.2 illustrates the sort of iterative process we would employ. We are hoping to find a “hotspot” that we can tune without having to restructure substantial amounts of the application. Using tools to find MPI issues may have us optimize at the domain level of parallelism. Using tools to find node level issues may have us optimize at the thread or data parallelism level. Data locality challenges may surface doing either. Fig. 7.2 illustrates such a tool-driven approach for improving threading and vectoriz...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- Acknowledgments
- Foreword
- Preface
- Section I: Knights Landing
- Section II: Parallel Programming
- Section III: Pearls
- Contributors
- Glossary
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Intel Xeon Phi Processor High Performance Programming by James Jeffers,James Reinders,Avinash Sodani in PDF and/or ePUB format, as well as other popular books in Informatik & Parallele Programmierung. We have over one million books available in our catalogue for you to explore.