
eBook - ePub
Problem-solving in High Performance Computing
A Situational Awareness Approach with Linux
- 320 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Problem-solving in High Performance Computing
A Situational Awareness Approach with Linux
About this book
Problem-Solving in High Performance Computing: A Situational Awareness Approach with Linux focuses on understanding giant computing grids as cohesive systems. Unlike other titles on general problem-solving or system administration, this book offers a cohesive approach to complex, layered environments, highlighting the difference between standalone system troubleshooting and complex problem-solving in large, mission critical environments, and addressing the pitfalls of information overload, micro, and macro symptoms, also including methods for managing problems in large computing ecosystems.
The authors offer perspective gained from years of developing Intel-based systems that lead the industry in the number of hosts, software tools, and licenses used in chip design. The book offers unique, real-life examples that emphasize the magnitude and operational complexity of high performance computer systems.
- Provides insider perspectives on challenges in high performance environments with thousands of servers, millions of cores, distributed data centers, and petabytes of shared data
- Covers analysis, troubleshooting, and system optimization, from initial diagnostics to deep dives into kernel crash dumps
- Presents macro principles that appeal to a wide range of users and various real-life, complex problems
- Includes examples from 24/7 mission-critical environments with specific HPC operational constraints
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
Do you have a problem?
Abstract
In this chapter, we learn how problems manifest themselves in complex environments and try to separate cause from effect. We learn how to avoid information clutter, and how to perform systematic problem solving, with a methodical difficulty-based approach.
Keywords
problem
identification
definition
isolation
symptom
Now that you understand the scope of problem solving in a complex environment such as a large, mission-critical data center, it is time to begin investigating system issues in earnest. Normally, you will not just go around and search for things that might look suspicious. There ought to be a logical process that funnels possible items of interest – let us call them events – to the right personnel. This step is just as important as all later links in the problem-solving chains.
Identification of a problem
Let us begin with a simple question. What makes you think you have a problem? If you are one of the support personnel handling environment problems in your company, there are several possible ways you might be notified of an issue.
You might get a digital alert, sent by a monitoring program of some sort, which has decided there is an exception to the norm, possibly because a certain metric has exceeded a threshold value. Alternatively, someone else, your colleague, subordinate, or a peer from a remote call center, might forward a problem to you, asking for your assistance.
A natural human response is to assume that if problem-monitoring software has alerted you, this means there is a problem. Likewise, in case of an escalation by a human operator, you can often assume that other people have done all the preparatory work, and now they need your expert hand.
But what if this is not true? Worse yet, what if there is a problem that no one is really reporting?
If a tree falls in a forest, and no one hears it fall
Problem solving can be treated almost philosophically, in some cases. After all, if you think about it, even the most sophisticated software only does what its designer had in mind, and thresholds are entirely under our control. This means that digital reports and alerts are entirely human in essence, and therefore prone to mistakes, bias, and wrong assumptions.
However, issues that get raised are relatively easy. You have the opportunity to acknowledge them, and fix them or dismiss them. But, you cannot take an action about a problem that you do not know is there.
In the data center, the answer to the philosophical question is not favorable to system administrators and engineers. If there is an obscure issue that no existing monitoring logic is capable of capturing, it will still come to bear, often with interest, and the real skill lies in your ability to find the problems despite missing evidence.
It is almost like the way physicists find the dark matter in the universe. They cannot really see it or measure it, but they can measure its effect indirectly.
The same rules apply in the data center. You should exercise a healthy skepticism toward problems, as well as challenge conventions. You should also look for the problems that your tools do not see, and carefully pay attention to all those seemingly ghost phenomena that come and go. To make your life easier, you should embrace a methodical approach.
Step-by-step identification
We can divide problems into three main categories:
• real issues that correlate well to the monitoring tools and prior analysis by your colleagues,
• false positives raised by previous links in the system administration chain, both human and machine,
• real (and spurious) issues that only have an indirect effect on the environment, but that could possibly have significant impact if left unattended.
Your first tasks in the problem-solving process are to decide what kind of an event you are dealing with, whether you should acknowledge an early report or work toward improving your monitoring facilities and internal knowledge of the support teams, and how to handle come-and-go issues that no one has really classified yet.
Always use simple tools first
The data center world is a rich and complex one, and it is all too easy to get lost in it. Furthermore, your past knowledge, while a valuable resource, can also work against you in such a setup. You may assume too much and overreach, trying to fix problems with an excessive dose of intellectual and physical force. To demonstrate, let us take a look at the following example. The actual subject matter is not trivial, but it illustrates how people often make illogical, far-reaching conclusions. It is a classic case of our sensitivity threshold searching for the mysterious and vague in the face of great complexity.
A system administrator contacts his peer, who is known to be an expert on kernel crashes, regarding a kernel panic that has occurred on one of his systems. The administrator asks for advice on how to approach and handle the crash instance and how to determine what caused the system panic.
The expert lends his help, and in the processes, also briefly touches on the methodology for the analysis of kernel crash logs and how the data within can be interpreted and used to isolate issues.
Several days later, the same system administrator contacts the expert again, with another case of a system panic. Only this time, the enthusiastic engineer has invested some time reading up on kernel crashes and has tried to perform the analysis himself. His conclusion to the problem is: “We have got one more kernel crash on another server, and this time it seems to be quite an old kernel bug.”
The expert then does his own analysis. What he finds is completely different from his colleague. Toward the end of the kernel crash log, there is a very clear instance of a hardware exception, caused by a faulty memory bank, which led to the panic.
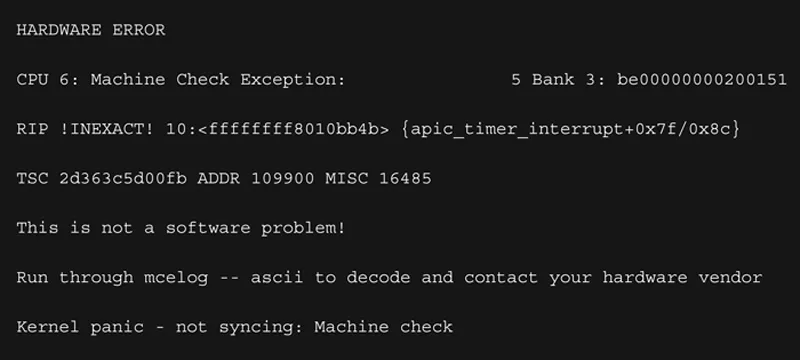
Copyright ©Intel Corporation. All rights reserved.
You may wonder what the lesson to this exercise is. The system administrator did a classic mistake of assuming the worst, when he should have invested time in checking the simple things first. He did this for two reasons: insufficient knowledge in a new domain, and the tendency of people doing routine work to disregard the familiar and go for extremes, often with little foundation to their claims. However, once the mind is set, it is all too easy to ignore real evidence and create false logical links. Moreover, the administrator may have just learned how to use a new tool, so he or she may be biased toward using that tool whenever possible.
Using simple tools may sound tedious, but there is value in working methodically, top down, and doing the routine work. It may not reveal much, but it will not expose new, bogus problems either. The beauty in a gradual escalation of complexity in problem solving is that it allows trivial things to be properly identified and resolved. This saves time and prevents the technicians from investing effort in chasing down false positives, all due to their own internal convictions and the basic human need for causality.
At certain times, it will be perfectly fine – and even desirable – to go for heavy tools and deep-down analysis. Most of the time, most of the problems will have simple root causes. Think about it. If you have a monitor in place, this means you have a mathematical formula, and you can explain the problem. Now, you are just trying to prevent its manifestation or minimize damage. Likewise, if you have several levels of technical support handling a problem, it means you have identified the severity level, and you know what needs to be done.
Complex problems, the big ones, will often manifest themselves in very weird ways, and you will be tempted to ignore them. On the same note, you will overinflate simple things and make them into huge issues. This is why you need to be methodical and focus on simple steps, to make the right categorization of problems, and make your life easier down the road.
Too much knowledge leads to mistakes
Our earlier example is a good example of how wrong knowledge and wrong assumptions can make the system administrator blind to the obvious. Indeed, the more experienced you get, the less patient you will be to resolving simple, trivial, well-known issues. You will not want to be fixing them, and you may even display an unusual amount of disregard and resistance when asked to step in and help.
Furthermore, when your mind is tuned to reach high and far, you will miss all the little things happening right under your nose. You will make the mistake of being “too proud,” and you will search for problems that increase your excitement level. When no real issues of that kind are to be found, you will, by the grace of human nature, invent them.
It is important to be aware of this logical fallacy lurking in our brains. This is the Achilles’s heel of every engineer and problem solver. You want to be fighting the unknown, and you will find it anywhere you look.
For this reason, it is critical to make problem solving into a discipline rather than an erratic, ad-hoc effort. If two system administrators in the same position or role use completely different ways of resolving the same issue, it is a good indication of a lack of a formal problem-solving process, core knowledge, understanding of your environment, and how things come to bear.
Moreover, it is useful to narrow down the investigative focus. Most people, save an occasional genius, tend to operate better with a small amount of uncertainty rather than complete chaos. They also tend to ignore things they consider trivial, and they get bored easily with the routine.
Therefore, problem solving should also include a significant effort in automating the well known and trivial, so that engineers need not invest time repeating the obvious and mundane. Escalations need to be precise and methodical and well documented, so that everyone can repeat them with the same expected outcome. Skills should be matched to problems. Do not expect inexperienced technicians to make the right decisions when analyzing kernel crashes. Likewise, do not expect your expert to be enthused about running simple commands and checks, because they will often skip them, ignore possibly valuable clues, and jump to their own conclusions, adding to the entropy of your data center.
With the right combination of known and unknown, as well as the smart utilization of available machine and human resources, it is possible to minimize the waste during investigations. In turn, you will have fewer false positives, and your real experts will be able to focus on those weird issues with indirect manifestation, because those are the true big ones you want to solve.
Problem definition
We still have not resolved any one of our three possible problems. They still remain, but at least now, we are a little less unclear how to approach them. We will now focus some more energy on trying to classify problems so that our investigation is even more effective.
Problem that happens now or that may be
Alerts from monitoring systems are usually an indication of a problem, or a possible problem happening in real time. Your primary goal is to change the setup in a manner that will make the alert go away. This is the classic definition of threshold-based problem solving.
We can immediately spot the pitfalls in this approach. If a technician needs to make the problem go away, they will make it go away. If it cannot be solved, it can be ignored, the threshold values can be changed, or the problem interpreted in a different way. Sometimes, in business environments, sheer management pressure in the face of an immediate inability to resolve a seemingly acute problem can lead to a rather simple resolution: reclassification of a problem. If you cannot resolve it, acknowledge it, relabel it, and move on.
Furthermore, events often have a maximum response time. This is called service level agreement (SLA), and it determines how quickly the support team should provide a resolution to the problem. Unfortunately, the word resolution is misused here. This does not mean that the problem should be fixed. This only means that an adequate response was provided, and that the next step in the investigation is known.
With time pressure, peer pressure, management mission statement, and real-time urgency all combined, problem resolution loses some of its academic focus and it becomes a social issue of the particular environment. Now, this is absolutely fine. Real-life business is not an isolated mathematical problem. However, you need to be aware of that and remember when handling real-time issues.
Problems that...
Table of contents
- Cover
- Title page
- Table of Contents
- Copyright
- Dedication
- Preface
- Acknowledgments
- Introduction: data center and high-end computing
- Chapter 1: Do you have a problem?
- Chapter 2: The investigation begins
- Chapter 3: Basic investigation
- Chapter 4: A deeper look into the system
- Chapter 5: Getting geeky – tracing and debugging applications
- Chapter 6: Getting very geeky – application and kernel cores, kernel debugger
- Chapter 7: Problem solution
- Chapter 8: Monitoring and prevention
- Chapter 9: Make your environment safer, more robust
- Chapter 10: Fine-tuning the system performance
- Chapter 11: Piecing it all together
- Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Problem-solving in High Performance Computing by Igor Ljubuncic in PDF and/or ePUB format, as well as other popular books in Computer Science & Systems Architecture. We have over 1.5 million books available in our catalogue for you to explore.