
eBook - ePub
Commercial Data Mining
Processing, Analysis and Modeling for Predictive Analytics Projects
- 304 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Commercial Data Mining
Processing, Analysis and Modeling for Predictive Analytics Projects
About this book
Whether you are brand new to data mining or working on your tenth predictive analytics project, Commercial Data Mining will be there for you as an accessible reference outlining the entire process and related themes. In this book, you'll learn that your organization does not need a huge volume of data or a Fortune 500 budget to generate business using existing information assets. Expert author David Nettleton guides you through the process from beginning to end and covers everything from business objectives to data sources, and selection to analysis and predictive modeling.
Commercial Data Mining includes case studies and practical examples from Nettleton's more than 20 years of commercial experience. Real-world cases covering customer loyalty, cross-selling, and audience prediction in industries including insurance, banking, and media illustrate the concepts and techniques explained throughout the book.
- Illustrates cost-benefit evaluation of potential projects
- Includes vendor-agnostic advice on what to look for in off-the-shelf solutions as well as tips on building your own data mining tools
- Approachable reference can be read from cover to cover by readers of all experience levels
- Includes practical examples and case studies as well as actionable business insights from author's own experience
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
Introduction
Abstract
The introduction commences with an overview of the readership, scope, and reason for the book, with reference to the complete cycle of a data mining project. Then a brief summary of each chapter is given, and finally some reading recommendations are provided.
Keywords
overview
chapter summaries
data mining
analysis
data
project cycle
This book is intended to benefit a wide audience, from those who have limited experience in commercial data analysis to those who already analyze commercial data, offering a vision of the whole process and its related topics. The author includes material from over 20 years of professional business experience as well as a diversity of research projects he was involved in, in order to enrich the content and give an original approach to commercial data analysis. In the appendix, practical case studies derived from real-world projects are used to illustrate the concepts and techniques that are explained throughout the book. Numerous references are included for those readers who wish to go into greater depth about a given topic.
Many of the methods, techniques, and ideas presented, such as data quality, data mart, customer relationship management, data sources, and Internet searches, can be applied by small business owners, freelance professionals, or medium to large-sized companies. The reader will see that it is not a prerequisite to have large volumes of data, and many tools used for data analysis are available for a nominal cost.
Although the steps in Chapter 2 through 10 can be carried out sequentially, note that, in practice, aspects such as data sources, data representation, and data quality are often carried out in parallel and reiteratively. This also applies to the variable/factor selection, analysis, and modeling steps. However, note that the better each step is performed, the fewer iterations will be necessary.
In order to obtain meaningful results, data analysis requires an attention to detail, an adequate project definition, meticulous preparation of the data, investigative capacity, patience, rigor, and objectives that are well defined from the beginning. If these requirements are taken together as a starting point, then a basis can be built from which a data warehouse is converted into a high-value asset. One of the motivators for data analysis is to realize a return on investment for the database infrastructures that many businesses have installed. Another is to gain competitive leverage and insight for products and services by better understanding the marketplace, including customer and competitor behavior.
The analysis and comprehension of business data are fundamental parts of all organizations. Monitoring national economies and retail sales tendencies depend on data analysis, as does measuring the profitability, costs, and competitiveness of commercial organizations and businesses. Analyzing customer data has become easier due to data management infrastructures that separate the operational data from the analytical data, and from Internet applications and cloud computing, which facilitate the gathering of large-volume historical data logs.
On the other hand, computer systems have swamped us with large volumes of data and information, much of which is irrelevant for a specific analysis objective. Also, customer behavior has become more complex due to the diversity of applications that compete in the marketplace, especially for mobile devices. Thus, the objective of data analysis should be that of discovering useful and meaningful knowledge and separating the relevant from the irrelevant.
Chapter 2 through 10 follow the sequential steps for a typical data mining project. A scheme of the organization of these chapters can be seen in Figure 1.1. Chapter 2, “Business Objectives,” discusses the definition of a data mining project, including its initial concept, motivation, business objectives, viability, estimated costs, and expected benefit (returns). Key considerations are defined and a way of quantifying the cost and benefit is presented in terms of the factors that most influence the project. Finally, two case studies illustrate how the cost/benefit evaluation can be applied to real-world projects.
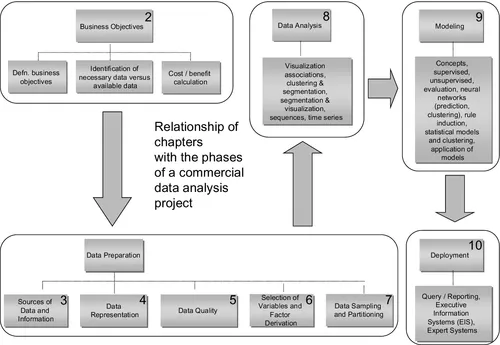
Figure 1.1Relationship between chapters and the phases of a commercial data analysis project
Chapter 3, “Incorporating Various Sources of Data and Information,” discusses possible sources of data and information that can be used for a commercial data mining project and how to establish which data sources are available and can be accessed for a commercial data analysis project. Data sources include a business’s own internal data about its customers and its business activities, as well as external data that affects a business and its customers in different domains and in given sectors: competitive, demographic, and macro-economic.
Chapter 4 “Data Representation,” looks at the different ways data can be conceptualized in order to facilitate its interpretation and visualization. Visualization methods include pie charts, histograms, graph plots, and radar diagrams. The topics covered in this chapter include representation, comparison, and processing of different types of variables; principal types of variables (numerical, categorical ordinal, categorical nominal, binary); normalization of the values of a variable; distribution of the values of a variable; and identification of atypical values or outliers. The chapter also discusses some of the more advanced types of data representation, such as semantic networks and graphs.
Chapter 5, “Data Quality,” discusses data quality, which is a primary consideration for any commercial data analysis project. In this book the definition of “quality” includes the availability or accessibility of data. The chapter discusses typical problems that can occur with data, errors in the content of the data (especially textual data), and relevance and reliability of the data and addresses how to quantitatively evaluate data quality.
Chapter 6, “Selection of Variables and Factor Derivation,” considers the topics of variable selection and factor derivation, which are used in a later chapter for analysis and modeling. Often, key factors must be selected from a large number of variables, and to do this two starting points are considered: (i) data mining projects that are defined by looking at the available data, and (ii) data mining projects that are driven by considering what the final desired result is. The chapter also discusses techniques such as correlation and factor analysis.
Chapter 7, “Data Sampling and Partitioning,” discusses sampling and partitioning methods, which is often done when the volume of data is too great to process as a whole or when the analyst is interested in selecting data by specific criteria. The chapter considers different types of sampling, such as random sampling and sampling based on business criteria (age of client, length of time as client, etc.).
With Chapter 2 through 7 having laid the foundation for obtaining and defining a dataset for analysis, Chapter 8, “Data Analysis,” describes a selection of the most common types of data analysis for data mining. Data visualization is discussed, followed by clustering and how it can be combined with visualization techniques. The reader is also introduced to transactional analysis and time series analysis. Finally, the chapter considers some common mistakes made when analyzing and interpreting data.
Chapter 9, “Modeling,” begins with the definition of a data model and what its inputs and outputs are, then goes on to discuss concepts such as supervised and unsupervised learning, cross-validation, and how to evaluate the precision of modeling results. The chapter then considers various techniques for modeling data, from AI (artificial intelligence) approaches, such as neural networks and rule induction, to statistical techniques, such as regression. The chapter explains which techniques should be used for various modeling scenarios. It goes on to discuss how to apply models to real-world production data and how to evaluate and use the results. Finally, guidelines are given for how to perform and reiterate the modeling phase, especially when the initial results are not the desired or optimal ones.
Chapter 10, “Deployment Systems: From Query Reporting to EIS and Expert Systems,” discusses ways that the results of data mining can be fed into the decision-making and operative processes of the business.
Chapter 11 through 19 address various background topics and specific data mining domains. A scheme of the organization of these chapters can be seen in Figure 1.2.
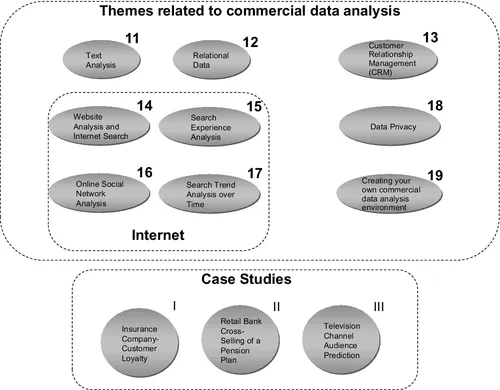
Figure 1.2Chapter topics related to commercial data analysis and projects based on real-world cases
Chapter 11, “Text Analysis,” discusses both simple and more advanced text processing and text analysis: basic processing takes into account format checking based on pattern identification, and more advanced techniques consider named entity recognition, concept identification based on synonyms and hyponyms, and information retrieval concepts.
Chapter 12, “Data Mining from Relationally Structured Data, Marts, and Warehouses,” deals with extracting a data mining file from relational data. The chapter reviews the concepts of “data mart” and “data warehouse” and discusses how the informational data is separated from the operational data, then describes the path of extracting data from an operational environment into a data mart and finally into a unique file that can then be used as the starting point for data mining.
Chapter 13, “CRM – Customer Relationship Management and Anal...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright page
- Acknowledgments
- Chapter 1: Introduction
- Chapter 2: Business Objectives
- Chapter 3: Incorporating Various Sources of Data and Information
- Chapter 4: Data Representation
- Chapter 5: Data Quality
- Chapter 6: Selection of Variables and Factor Derivation
- Chapter 7: Data Sampling and Partitioning
- Chapter 8: Data Analysis
- Chapter 9: Data Modeling
- Chapter 10: Deployment Systems: From Query Reporting to EIS and Expert Systems
- Chapter 11: Text Analysis
- Chapter 12: Data Mining from Relationally Structured Data, Marts, and Warehouses
- Chapter 13: CRM – Customer Relationship Management and Analysis
- Chapter 14: Analysis of Data on the Internet I – Website Analysis and Internet Search
- Chapter e14: Analysis of Data on the Internet I – Website Analysis and Internet Search
- Chapter 15: Analysis of Data on the Internet II – Search Experience Analysis
- Chapter e15: Analysis of Data on the Internet II – Search Experience Analysis
- Chapter 16: Analysis of Data on the Internet III – Online Social Network Analysis
- Chapter e16: Analysis of Data on the Internet III – Online Social Network Analysis
- Chapter 17: Analysis of Data on the Internet IV – Search Trend Analysis over Time
- Chapter e17: Analysis of Data on the Internet IV – Search Trend Analysis over Time
- Chapter 18: Data Privacy and Privacy-Preserving Data Publishing
- Chapter 19: Creating an Environment for Commercial Data Analysis
- Chapter 20: Summary
- Appendix: Case Studies
- Glossary
- Glossary
- Bibliography
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Commercial Data Mining by David Nettleton in PDF and/or ePUB format, as well as other popular books in Business & Business Intelligence. We have over 1.5 million books available in our catalogue for you to explore.