
eBook - ePub
Data Architecture: A Primer for the Data Scientist
A Primer for the Data Scientist
- 431 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Data Architecture: A Primer for the Data Scientist
A Primer for the Data Scientist
About this book
Over the past 5 years, the concept of big data has matured, data science has grown exponentially, and data architecture has become a standard part of organizational decision-making. Throughout all this change, the basic principles that shape the architecture of data have remained the same. There remains a need for people to take a look at the "bigger picture" and to understand where their data fit into the grand scheme of things.
Data Architecture: A Primer for the Data Scientist, Second Edition addresses the larger architectural picture of how big data fits within the existing information infrastructure or data warehousing systems. This is an essential topic not only for data scientists, analysts, and managers but also for researchers and engineers who increasingly need to deal with large and complex sets of data. Until data are gathered and can be placed into an existing framework or architecture, they cannot be used to their full potential. Drawing upon years of practical experience and using numerous examples and case studies from across various industries, the authors seek to explain this larger picture into which big data fits, giving data scientists the necessary context for how pieces of the puzzle should fit together.
- New case studies include expanded coverage of textual management and analytics
- New chapters on visualization and big data
- Discussion of new visualizations of the end-state architecture
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1.1
An Introduction to Data Architecture
Abstract
Corporate data include everything found in the corporation in the way of data. The most basic division of corporate data is by structured data and unstructured data. As a rule, there are much more unstructured data than structured data. Unstructured data have two basic divisions—repetitive data and nonrepetitive data. Big data is made up of unstructured data. Nonrepetitive big data has a fundamentally different form than repetitive unstructured big data. In fact, the differences between nonrepetitive big data and repetitive big data are so large that they can be called the boundaries of the “great divide.” The divide is so large; many professionals are not even aware that there is this divide. As a rule, nonrepetitive big data has MUCH greater business value than repetitive big data.
Keywords
Structured data; Unstructured data; Corporate data; Repetitive data; Nonrepetitive data; Business value; The great divide of data; Big data
Data architecture is about the larger picture of data and how it fits together in a typical organization. The natural starting point for looking at the big picture of how data fit together in a corporation begins naturally enough with all the data in the corporation.
Fig. 1.1.1 depicts symbolically all the data—of every kind—in the corporation.

Fig. 1.1.1 depicts every kind of data found in the corporation. It depicts data generated by running transactions. It depicts e-mail. It depicts telephone conversations. It depicts data found in personal computers. It depicts metering data. It depicts office memos. It depicts contracts, safety reports, and time sheets. It depicts pay ledgers.
In a word, if it is data and it is in the corporation, it is depicted by the bar shown in Fig. 1.1.1.
Subdividing Data
There are many ways to subdivide the data shown in Fig. 1.1.1. The way that is shown is only one of many ways data can be understood.
One way to understand the data found in the corporation is to look at structured data and nonstructured data. Fig. 1.1.2 shows this subdivision of data.

Structured data are data that are well defined. Structured data are typically repetitive. The same structure of data recurs repeatedly. The only difference between one occurrence of data and another is in the contents of the data. As a simple example of structured data, there are records of the sale of a good—an “SKU”—made by a retailer. Each time Walmart makes a sale the item sold, the amount of the sale, the tax paid, and the date and location of the sale are recorded. In a day's time, Walmart will create many records of the sale of many items. From a structural standpoint, the sale of one item will be identical to the sale of another item. The data are called “structured” because of the similarity of the structure of the records.
The high degree of structure and definition of the records make the records easy to handle inside a database management system.
However, structured records are hardly the only kind of data in the corporation. In fact, structured data typically represent only a small fraction of the data found in the corporation. The other kind of data found in the corporation is called unstructured data.
Repetitive/Nonrepetitive Unstructured Data
There are two basic kinds of unstructured data in the corporation—repetitive unstructured data and nonrepetitive unstructured data.
Fig. 1.1.3 depicts the different kinds of unstructured data in the corporation.
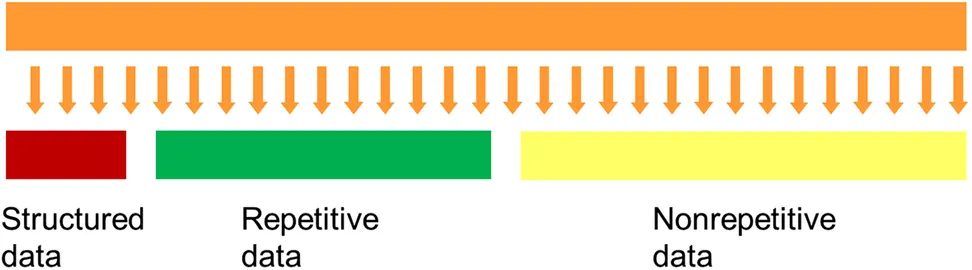
A typical form of repetitive unstructured data in the corporation might be the data generated by an analog machine. For example, a farmer has a machine that reads the identification of railroad cars as the railroad cars pass through the farmer's property. Trains pass through the property night and day. The electronic eye reads and records the passage of each car on the track.
Nonrepetitive unstructured data are data that are nonrepetitive, such as e-mails. Each e-mail can be long or short. The e-mail can be in English or Spanish (or some other languages.) The author of the e-mail can say anything that he/she pleases. It is only a pure accident if the contents of any e-mail are identical to the contents of any other e-mail. And there are many forms of nonrepetitive unstructured data. There are voice recordings, there are contracts, there are customer feedback messages, etc.
Because of its irregular form, unstructured data do not fit well with standard database management systems.
The Great Divide of Data
It is not obvious at all, but the dividing line in unstructured data between unstructured repetitive data and unstructured nonrepetitive data is very significant. In fact, the dividing line between unstructured repetitive data and unstructured nonrepetitive data is so important that the division can be called the “great divide” of data.
Fig. 1.1.4 shows the great divide of data.

It is hardly obvious why there should be this great divide of data. But there are some very good reasons for the divide:
- Repetitive data usually have very limited business value, wh...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- Dedication
- Chapter 1.1: An Introduction to Data Architecture
- Chapter 1.2: The Data Infrastructure
- Chapter 1.3: The “Great Divide”
- Chapter 1.4: Demographics of Corporate Data
- Chapter 1.5: Corporate Data Analysis
- Chapter 1.6: The Life Cycle of Data: Understanding Data Over Time
- Chapter 1.7: A Brief History of Data
- Chapter 2.1: The End-State Architecture—The “World Map”
- Chapter 3.1: Transformations in the End-State Architecture
- Chapter 4.1: A Brief History of Big Data
- Chapter 4.2: What Is Big Data?
- Chapter 4.3: Parallel Processing
- Chapter 4.4: Unstructured Data
- Chapter 4.5: Contextualizing Repetitive Unstructured Data
- Chapter 4.6: Textual Disambiguation
- Chapter 4.7: Taxonomies
- Chapter 5.1: The Siloed Application Environment
- Chapter 6.1: Introduction to Data Vault 2.0
- Chapter 6.2: Introduction to Data Vault Modeling
- Chapter 6.3: Introduction to Data Vault Architecture
- Chapter 6.4: Introduction to Data Vault Methodology
- Chapter 6.5: Introduction to Data Vault Implementation
- Chapter 7.1: The Operational Environment: A Short History
- Chapter 7.2: The Standard Work Unit
- Chapter 7.3: Data Modeling for the Structured Environment
- Chapter 8.1: A Brief History of Data Architecture
- Chapter 8.2: Big Data/Existing System Interface
- Chapter 8.3: The Data Warehouse/Operational Environment Interface
- Chapter 8.4: Data Architecture: A High-Level Perspective
- Chapter 9.1: Repetitive Analytics: Some Basics
- Chapter 9.2: Analyzing Repetitive Data
- Chapter 9.3: Repetitive Analysis
- Chapter 10.1: Nonrepetitive Data
- Chapter 10.2: Mapping
- Chapter 10.3: Analytics From Nonrepetitive Data
- Chapter 11.1: Operational Analytics: Response Time
- Chapter 12.1: Operational Analytics
- Chapter 13.1: Personal Analytics
- Chapter 14.1: Data Models Across the End-State Architecture
- Chapter 15.1: The System of Record
- Chapter 16.1: Business Value and the End-State Architecture
- Chapter 17.1: Managing Text
- Chapter 18.1: An Introduction to Data Visualizations
- Glossary
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Architecture: A Primer for the Data Scientist by W.H. Inmon,Daniel Linstedt,Mary Levins in PDF and/or ePUB format, as well as other popular books in Business & Business Intelligence. We have over 1.5 million books available in our catalogue for you to explore.