
eBook - ePub
Robust Automatic Speech Recognition
A Bridge to Practical Applications
- 306 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Robust Automatic Speech Recognition
A Bridge to Practical Applications
About this book
Robust Automatic Speech Recognition: A Bridge to Practical Applications establishes a solid foundation for automatic speech recognition that is robust against acoustic environmental distortion. It provides a thorough overview of classical and modern noise-and reverberation robust techniques that have been developed over the past thirty years, with an emphasis on practical methods that have been proven to be successful and which are likely to be further developed for future applications.The strengths and weaknesses of robustness-enhancing speech recognition techniques are carefully analyzed. The book covers noise-robust techniques designed for acoustic models which are based on both Gaussian mixture models and deep neural networks. In addition, a guide to selecting the best methods for practical applications is provided.The reader will:
- Gain a unified, deep and systematic understanding of the state-of-the-art technologies for robust speech recognition
- Learn the links and relationship between alternative technologies for robust speech recognition
- Be able to use the technology analysis and categorization detailed in the book to guide future technology development
- Be able to develop new noise-robust methods in the current era of deep learning for acoustic modeling in speech recognition
- The first book that provides a comprehensive review on noise and reverberation robust speech recognition methods in the era of deep neural networks
- Connects robust speech recognition techniques to machine learning paradigms with rigorous mathematical treatment
- Provides elegant and structural ways to categorize and analyze noise-robust speech recognition techniques
- Written by leading researchers who have been actively working on the subject matter in both industrial and academic organizations for many years
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
Introduction
Abstract
Automatic speech recognition (ASR) by machine has been a field of research for more than 60 years. The industry has developed a broad range of commercial products where ASR as user interface has become ever more useful and pervasive. Consumer-centric applications increasingly require ASR to be robust to the full range of real-world noise and other acoustic distorting conditions. However, reliably recognizing spoken words in realistic acoustic environments is still a challenge.
We introduce distortion factors that operate in various stages of speech production, from thought to speech signals, leading to the issues of ASR robustness as the focus of this book. We provide an introductory summary of this book in this chapter, covering the ASR robustness problem for acoustic models based on both Gaussian mixture models and deep neural networks. The book goes significantly beyond much of the existing survey literature, and illustrates the research and product development on ASR robustness to noisy acoustic environments that has been progressing for over 30 years.
Finally, we define the mission, goal, and structure of the book in this chapter. We aim to establish a solid, consistent, and common mathematical foundation for robust ASR, emphasizing the methods proven to be successful and expected to sustain or expand their future applicability.
Keywords
Automatic speech recognition
Noise robustness
ASR applications
Survey
Gaussian mixture models
Deep neural networks
1.1 Automatic Speech Recognition
Automatic speech recognition (ASR) is the process and the related technology for converting the speech signal into its corresponding sequence of words or other linguistic entities by means of algorithms implemented in a device, a computer, or computer clusters (Deng and O’Shaughnessy, 2003; Huang et al., 2001b). ASR by machine has been a field of research for more than 60 years (Baker et al., 2009a,b; Davis et al., 1952). The industry has developed a broad range of commercial products where speech recognition as user interface has become ever useful and pervasive.
Historically, ASR applications have included voice dialing, call routing, interactive voice response, data entry and dictation, voice command and control, gaming, structured document creation (e.g., medical and legal transcriptions), appliance control by voice, computer-aided language learning, content-based spoken audio search, and robotics. More recently, with the exponential growth of big data and computing power, ASR technology has advanced to the stage where more challenging applications are becoming a reality. Examples are voice search, digital assistance and interactions with mobile devices (e.g., Siri on iPhone, Bing voice search and Cortana on winPhone and Windows 10 OS, and Google Now on Android), voice control in home entertainment systems (e.g., Kinect on xBox), machine translation, home automation, in-vehicle navigation and entertainment, and various speech-centric information processing applications capitalizing on downstream processing of ASR outputs (He and Deng, 2013).
1.2 Robustness to Noisy Environments
New waves of consumer-centric applications increasingly require ASR to be robust to the full range of real-world noise and other acoustic distorting conditions. However, reliably recognizing spoken words in realistic acoustic environments is still a challenge. For such large-scale, real-world applications, noise robustness is becoming an increasingly important core technology since ASR needs to work in much more difficult acoustic environments than in the past (Deng et al., 2002).
Noise refers to any unwanted disturbances superposed upon the intended speech signal. Robustness is the ability of a system to maintain its good performance under varying operating conditions, including those unforeseeable or unavailable at the time of system development.
Speech as observed and digitized is generated by a complex process, from the thoughts to actual speech signals. This process can be described in five stages as shown in Figure 1.1, where a number of variables affect the outcome of each stage. Some major stages in this long chain have been analyzed and modeled mathematically in Deng (1999, 2006).
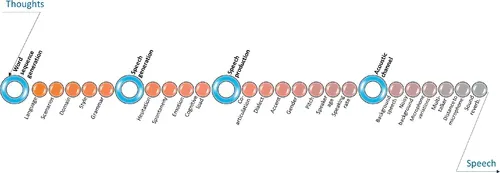
Figure 1.1 From thoughts to speech.
All of the above could lead to ASR robustness issues. This book addresses challenges mostly in the acoustic channel area where interfering signals lead to ASR performance degradation.
In this area, robustness of ASR to noisy background can be approached from two directions:
• reducing the noise level by exploring hardware utilizing spatial or directional information from microphone technology and transducer principles, such as noise canceling microphones and microphone arrays;
• software algorithmic processing taking advantage of the spectral and temporal separation between speech and interfering signals, which is the major focus of this book.
1.3 Existing Surveys in the Area
Researchers and practitioners have been trying to improve ASR robustness to operating conditions for many years (Huang et al., 2001a; Huang and Deng, 2010). A survey of the 1970s speech recognition systems has identified (Lea, 1980) that “a primary difficulty with speech recognition is this ability of the input to pick up other sounds in the environment that act as interfering noise.” The term “robust speech recognition” emerged in the late 1980s. Survey papers in the 1990s include (Gong, 1995; Juang, 1991; Junqua and Haton, 1995). By 2000, robust speech recognition has gained significant importance in the speech and language processing fields. Actually, it was the most popular area in the International Conference on Acoustics, Speech and Signal Processing, at least during 2001-2003 (Gong, 2004). Since 2010, robust ASR remains one of the most popular areas in the speech processing community, and tremendous and steady progress in noisy speech recognition have been made.
A large number of noise-robust ASR methods, in the order of hundreds, have been proposed and published over the past 30 years or so, and many of them have created significant impact on either research or commercial use. Such accumulated knowledge deserves thorough examination not only to define the state of the art in this field from a fresh and unifying perspective, but also to point to potentially fruitful future directions. Nevertheless, a well-organized framework for relating and analyzing these methods is conspicuously missing. The existing survey papers (Acero, 1993; Deng, 2011; Droppo and Acero, 2008; Gales, 2011; Gong, 1995; Haeb-Umbach, 2011; Huo and Lee, 2001; Juang, 1991; Kumatani et al., 2012; Lee, 1998) in noise-robust ASR either do not cover all recent advances in the field or focus only on a specific sub-area. Although there are also few recent books (Kolossa and Haeb-Umbach, 2011; Virtanen et al., 2012), they are collections of topics with each chapter written by different authors and it is hard to provide a unified view across all topics. Given the importance of noise-robust ASR, the time is ripe to analyze and unify the solutions. The most recent overview paper (Li et al., 2014) elaborates on the basic concepts in noise-robust ASR and develops categorization criteria and unifying themes. Specifically, it hierarchically classifies the major and significant noise-robust ASR methods using a consistent and unifying mathematical language. It establishes their interrelations and differentiates among important techniques, and discusses current technical challenges and future research directions. It also identifies relatively promising, short-term new research areas based on a careful analysis of successful methods, which can serve as a reference for future algorithm development in the field. Furthermore, in the literature spanning over 30 years on noise-robust ASR, there is inconsistent use of basic concepts and terminology as adopted by different researchers in the field. This kind of inconsistency is confusing at times, especially for new researchers and students. It is, therefore, important to examine discrepancies in the current literature and re-define a consistent terminology. However, due to the restriction of page length, the overview paper (Li et al., 2014) did not discuss the technologies in depth. More importantly, all the aforementioned books and articles largely assumed that the acoustic models for ASR are based on Gaussian mixture model hidden Markov models (GMM-HMMs).
More recently, a new acoustic modeling techniq...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- About the Authors
- List of Figures
- List of Tables
- Acronyms
- Notations
- Chapter 1: Introduction
- Chapter 2: Fundamentals of speech recognition
- Chapter 3: Background of robust speech recognition
- Chapter 4: Processing in the feature and model domains
- Chapter 5: Compensation with prior knowledge
- Chapter 6: Explicit distortion modeling
- Chapter 7: Uncertainty processing
- Chapter 8: Joint model training
- Chapter 9: Reverberant speech recognition
- Chapter 10: Multi-channel processing
- Chapter 11: Summary and future directions
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Robust Automatic Speech Recognition by Jinyu Li,Li Deng,Reinhold Haeb-Umbach,Yifan Gong in PDF and/or ePUB format, as well as other popular books in Technology & Engineering & Acoustical Engineering. We have over 1.5 million books available in our catalogue for you to explore.