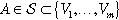Data mining is often referred to by real-time users and software solutions providers as knowledge discovery in databases (KDD). Good data mining practice for business intelligence (the art of turning raw software into meaningful information) is demonstrated by the many new techniques and developments in the conversion of fresh scientific discovery into widely accessible software solutions. This book has been written as an introduction to the main issues associated with the basics of machine learning and the algorithms used in data mining.Suitable for advanced undergraduates and their tutors at postgraduate level in a wide area of computer science and technology topics as well as researchers looking to adapt various algorithms for particular data mining tasks. A valuable addition to the libraries and bookshelves of the many companies who are using the principles of data mining (or KDD) to effectively deliver solid business and industry solutions.
- Provides an introduction to the main issues associated with the basics of machine learning and the algorithms used in data mining
- A valuable addition to the libraries and bookshelves of companies using the principles of data mining (or KDD) to effectively deliver solid business and industry solutions
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
The time will come when we will have to forget everything we have learnt.
— Ramana Maharshi
Machine learning, a subfield of artificial intelligence, has shown tremendous improvements in the last 20 years. This is reflected in numerous commercial and open source systems for machine learning and their applications in industry, medicine, economics, natural and technical sciences, ecology, finance, and many others. Machine learning is used for data analysis and knowledge discovery in databases (data mining), automatic generation of knowledge bases for expert systems, learning to plan, game playing, construction of numerical and qualitative models, text classification and text mining (e.g., on the world wide web), for automatic knowledge acquisition to control dynamic processes, automatic recognition of speech, handwriting, and images, etc.
The basic principle of machine learning is the automatic modeling of underlying processes that have generated the collected data. Learning from data results in rules, functions, relations, equation systems, probability distributions and other knowledge representations such as decision rules, decision and regression trees, Bayesian nets, neural nets, etc. Models explain the data and can be used for supporting decisions concerning the same underlying process (e.g., forecasting, diagnostics, control, validation, and simulations).
We start with an overview and definitions of overlapping and frequently (mis)used buzzwords and acronyms, such as machine learning (ML), data mining (DM), knowledge discovery in databases (KDD), and intelligent data analysis (IDA). We continue with a short overview of machine learning methods and historical development of different directions in machine learning research: symbolic rule learning, neural nets and reinforcement learning, numerical learning methods, and formal learning theory. We describe a few interesting early machine learning systems, review typical applications and finish with an overview of data mining standards and tools.
1.1 THE NAME OF THE GAME
Why do we not, since the phenomena are well known, build a “knowledge refinery” as the basis of a new industry, comparable in some ways to the industry of petroleum refining, only more important in the long run? The product to be refined is codified human knowledge.
— Donald Michie
The main problem of contemporary data analysis is the huge amount of data. In the last decade, computers have provided inexpensive and capable means to collect and store the data. The increase in data volume causes difficulties in extracting useful information. The traditional manual data analysis has become insufficient, and methods for efficient computer-based analysis are now needed. Therefore, a new interdisciplinary field has emerged, that encompasses statistical, pattern recognition, machine learning, and visualization tools to support the analysis of data and discovery of principles hidden within the data. In different communities this field is known by different names: knowledge discovery in databases (KDD), data mining (DM), or intelligent data analysis (IDA).
The terms data mining (in the database community) and knowledge discovery in databases (in machine learning and artificial intelligence communities) appeared around 1990, but the term data mining became more popular in the business community and in the press. Frequently, data mining and knowledge discovery are used interchangeably.
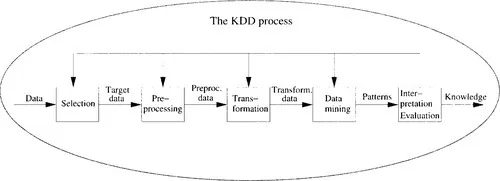
KDD focuses on the knowledge discovery from data (Figure 1.1), including how the data are stored and accessed; how algorithms can be scaled to massive data sets and still run efficiently; how results can be interpreted and visualized; and how the overall man-machine interaction can usefully be modeled and supported. The KDD process can be viewed as a multidisciplinary activity that encompasses techniques beyond the scope of any particular discipline such as machine learning. Note that the KDD process uses data mining as one of its steps.
Figure 1.1 The process of knowledge discovery in databases.
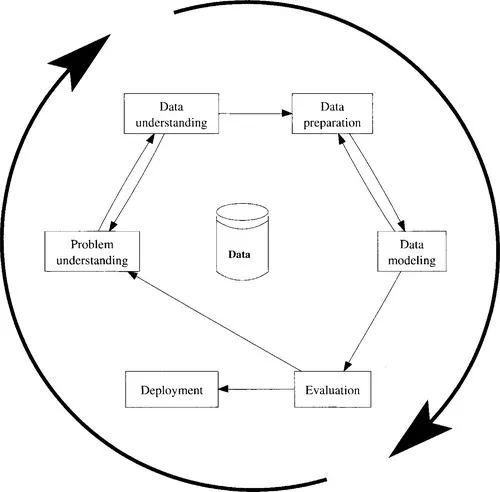
Data mining (DM) is an interactive and iterative process in which many steps need to be repeatedly refined in order to provide for an appropriate solution to the data analysis problem. Data mining standard CRISP-DM defines a process model that reflects the life cycle of a data mining project. It contains the phases (see Figure 1.2) of a data mining project and identifies relationships between them. The phases are cyclically iterated until some desired goal is reached. By comparing Figures 1.1 and 1.2 it is clear that basically they describe the same thing.
Figure 1.2 The cycle of a data mining process in the CRISP-DM standard.
The ambiguity whether KDD = DM arises from the fact that, strictly speaking, data mining (DM) covers the methods used in the data modeling step. This accounts both for visual methods as well as for methods that (semi) automatically deal with the extraction of knowledge from large masses of data, thus describing the data in terms of the interesting discovered regularities. Most automatic data mining methods have their origins in machine learning (ML). However, ML cannot be seen as a true subset of data mining, as it also encompasses other fields, not utilized for data mining (e.g. theory of learning, computational learning theory, and reinforcement learning).
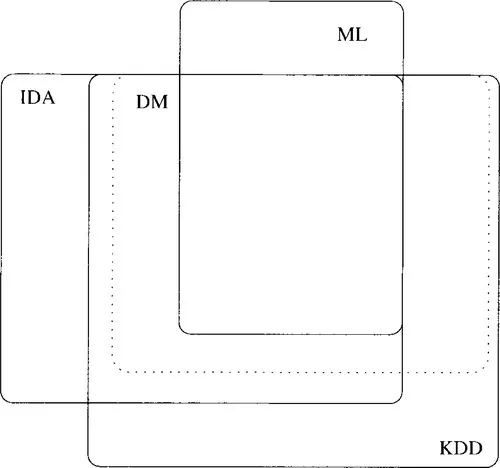
A closely related field of intelligent data analysis (IDA) is similar to KDD and DM. It also refers to the interactive and iterative process of data analysis, with the distinguishing feature that the architectures, methodologies and techniques used in this process are those of artificial intelligence (AI) and machine learning. Figure 1.3 shows the relation of IDA to KDD, DM and ML in the strictest sense. In practice (and in the following text) KDD and DM are treated as synonyms.
Figure 1.3 Relation between ML, DM, KDD, and IDA in the stricter sense.
There is a large intersection between KDD/DM and IDA. Both fields investigate data analysis, and they share many common methods. The main difference is that IDA uses AI methods and tools, while KDD/DM employ both AI and non-AI methods. Therefore, ML methods are in the intersection of the two fields, whereas classical statistical methods and on-line analytical processing (OLAP) belong to KDD/DM but not to IDA. Typically, KDD and DM are concerned with the extraction of knowledge from large datasets (databases), whereas in IDA the datasets are smaller.
1.2 OVERVIEW OF MACHINE LEARNING METHODS
A learning machine, broadly defined, is any device whose actions are influenced by past experiences.
— Nils J. Nilsson
This overview is intended to give an impression of the field of machine learning. Therefore detailed explanations are omitted. The meaning of various terms mentioned in this section will become more familiar later in the book.
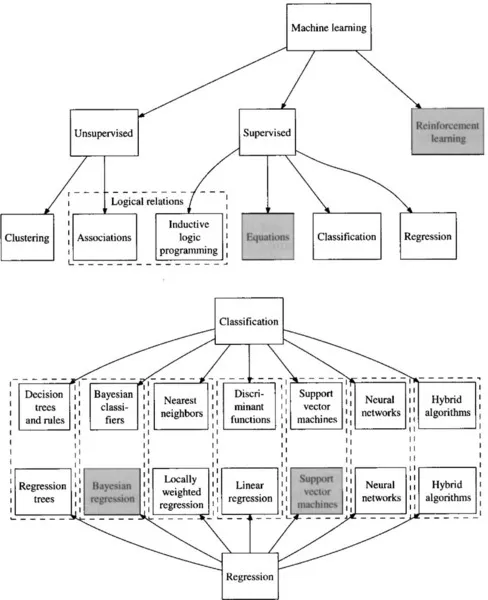
We differentiate machine learning methods with respect to how the obtained (induced) knowledge is used (see Figure 1.4): classification, regression, clustering, learning of associations, relations, and (differential) equations. Besides, machine learning is used in reinforcement learning within an iterative approach for optimization of value function approximation. Equation and reinforcement learning are not thoroughly discussed in this book, and are only described here for completeness.
Figure 1.4 A taxonomy of machine learning methods. The methods not thoroughly discussed in the book are grayed.
1.2.1 Classification
Machine learning methods are most frequently used for classification. Let us suppose that we have an object, described with many attributes (features, properties). Each object can be assigned to exactly one class from the finite set of possible classes. Attributes are independent observable variables, either continuous or discrete. The class is a dependent unobservable discrete variable and its value is determined from values of respective independent variables. Machine learning methods are, among others, used for creation of classifiers. The task of the classifier is to determine the class to which the object in question should be assigned.
A typical classification task is medical diagnosis: a patient is described with continuous (e.g. age, height, weight, body temperature, heart rate, blood pressure) and discrete attributes (e.g. sex, skin discoloration, location of pain). The classifier’s task is to produce a diagnosis – to label the patient with one of several possible diagnoses (e.g. healthy, influenza, pneumonia).
To determine the class, a classifier needs to describe a discrete function, a mapping from the attribute space to the class space. This function may be given in advance, or can be learnt from data. Data consists of learning examples (sometimes also called training instances) that describe solved past problems. For illustration let us again consider medical diagnostics. Here, solved past problems are medical records, including diagnoses, for all patients that had been treated in a hospital. The learning algorithm’s task is therefore to determine the mapping by learning from the set of patients with known diagnoses. This mapping (represented as a function, a rule, … ) can later be used for diagnosing new patients.
Different classifiers represent mapping functions in many different ways. Most common classifiers are decision trees, decision rules, naive Bayesian classifiers, Bayesian belief networks, nearest neighbor classifiers, linear discriminant functions, logistic regression, support vector machines, and artificial neural networks.
Decision trees and rules. Algorithms for building decision trees and rules can select attributes and suitable subsets of their values according to their quality, and use them as building blocks of a conjunctive rule’s antecedent. A consequent consists of one or more classes. When a new example arrives it is classified by applying a suitable rule.
For the given attribute A and its values V1 … Vm, decision trees and rules form conjunctive terms such as A = Vj or
. Continuous attributes are either discretized in advance or, even better, the terms like A > x, ...
Table of contents
Cover image
Title page
Table of Contents
Copyright page
Foreword
Preface
Chapter 1: Introduction
Chapter 2: Learning and Intelligence
Chapter 3: Machine Learning Basics
Chapter 4: Knowledge Representation
Chapter 5: Learning as Search
Chapter 6: Measures for Evaluating the Quality of Attributes
Chapter 7: Data Preprocessing
Chapter 8: *Constructive Induction
Chapter 9: Symbolic Learning
Chapter 10: Statistical Learning
Chapter 11: Artificial Neural Networks
Chapter 12: Cluster Analysis
Chapter 13: **Learning Theory
Chapter 14: **Computational Learning Theory
Appendix A: *Definitions of some lesser known terms
References
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Machine Learning and Data Mining by Igor Kononenko,Matjaz Kukar in PDF and/or ePUB format, as well as other popular books in Computer Science & Artificial Intelligence (AI) & Semantics. We have over 1.5 million books available in our catalogue for you to explore.