One of the most pressing tasks in biotechnology today is to unlock the function of each of the thousands of new genes identified every day. Scientists do this by analyzing and interpreting proteins, which are considered the task force of a gene. This single source reference covers all aspects of proteins, explaining fundamentals, synthesizing the latest literature, and demonstrating the most important bioinformatics tools available today for protein analysis, interpretation and prediction. Students and researchers of biotechnology, bioinformatics, proteomics, protein engineering, biophysics, computational biology, molecular modeling, and drug design will find this a ready reference for staying current and productive in this fast evolving interdisciplinary field.
- Explains all aspects of proteins including sequence and structure analysis, prediction of protein structures, protein folding, protein stability, and protein interactions
- Presents a cohesive and accessible overview of the field, using illustrations to explain key concepts and detailed exercises for students.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
This chapter describes the functional properties of proteins. The functional properties of proteins depend on their three-dimensional structures. The native structure of a protein can be experimentally determined using X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, electron microscopy, etc. Proteins perform a variety of functions, including enzymatic catalysis, transporting ions and molecules from one organ to another, nutrients, contractile system of muscles, tendons, cartilage, antibodies, and regulating cellular and physiological activities. Deciphering the three-dimensional structure of a protein from its amino acid sequence is a long-standing goal in molecular and computational biology. A protein chain is formed by several amino acids in which the amino group of the first amino acid and the carboxyl group of the last amino acid remain intact, and the chain is said to extend from the amino (N) to the carboxyl (C) terminus. This chain of amino acids is called a polypeptide chain, main chain, or backbone. These polypeptide chains that have specific functions are called proteins. In a polypeptide chain, the -carbon atoms of adjacent amino acids are separated by three covalent bonds arranged as Ca—C—N—Ca. Proteins are broadly classified into two major groups: fibrous proteins, having polypeptide chains arranged in long strands, and globular proteins, with polypeptide chains folded into a spherical or globular shape.
Proteins perform a variety of functions, including enzymatic catalysis, transporting ions and molecules from one organ to another, nutrients, contractile system of muscles, tendons, cartilage, antibodies, and regulating cellular and physiological activities. The functional properties of proteins depend on their three-dimensional structures. The native structure of a protein can be experimentally determined using X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, electron microscopy, etc. Over the past 40 years, the structures of more than 53,000 proteins (as of May 12, 2009) have been determined. On the other hand, the amino acid sequences are determined for more than eight million proteins (as of May 5, 2009). The specific sequence of amino acids in a polypeptide chain folds to generate compact domains with a particular three-dimensional structure. Anfinsen (1973) stated that the polypeptide chain itself contains all the information necessary to specify its three-dimensional structure. Deciphering the three-dimensional structure of a protein from its amino acid sequence is a long-standing goal in molecular and computational biology.
1.1 Building blocks
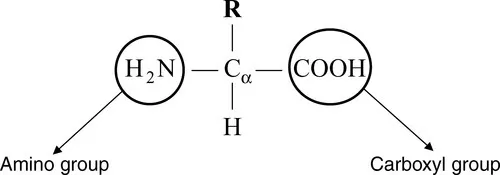
Protein sequences consist of 20 different kinds of chemical compounds, known as amino acids, and they serve as building blocks of proteins. Amino acids contain a central carbon atom (Cα), which is attached to a hydrogen atom, an amino group (NH2), and a carboxyl group (COOH) as shown in Figure 1.1. The letter R in Figure 1.1 indicates the presence of a side chain, which distinguishes each amino acid.
Figure 1.1 Representation of amino acids. R is the side chain that varies for the 20 amino acids.
1.1.1 Amino acids
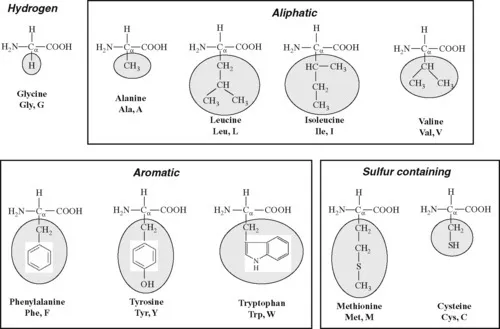
Amino acids are naturally of 20 different types as specified by the genetic code emerged from DNA sequences. Furthermore, nonnatural amino acids occur, in rare cases,as the products of enzymatic modifications after translocation. The major difference among the 20 amino acids is the side chain attached to the Cα through its fourth valance. The variation of side chains in 20 amino acids is shown in Figure 1.2. These residues are represented by conventional three- and one-letter codes. Most of the databases use single-letter codes.
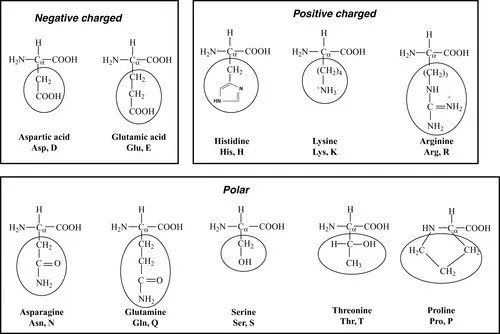
Figure 1.2 The common 20 amino acids in proteins. The three- and one-letter codes for the amino acids are also given. The amino acids are classified into hydrophobic (hydrogen, aliphatic, aromatic, and sulfur containing) and hydrophilic (negatively charged, positively charged, and polar). The side chains are marked with oval boxes.
The amino acids are broadly divided into two groups, hydrophobic and hydrophilic, based on the tendency of their interactions in the presence of water molecule. The hydrophobic residues have the tendency of adhering to one another in aqueous environment. Generally, amino acids, Ala (A), Cys (C), Phe (F), Gly (G), Ile (I), Leu (L), Met (M), Val (V), Trp (W), and Tyr (Y), are considered as hydrophobic residues. In this category, Ala, Ile, Leu, and Val contain aliphatic side chains; Phe, Trp,and Tyr contain aromatic side chains; and Cys and Met contain sulfur atom. Gly has no side chain, and it has hydrogen (H) at the fourth position. Two Cys residues in different parts of the polypeptide chain but adjacent to each other in the threedimensional structure of a protein can be oxidized to form a disulfide bridge. The formation of disulfide bridges in protein structures stabilizes the protein, making it less susceptible to degradation.
Amino acids, Asp (D), Glu (E), His (H), Lys (K), Asn (N), Pro (P), Gln (Q), Arg (R), Ser (S), and Thr (T), are classified as hydrophilic residues. In this category, Asp and Glu are negatively charged; His, Lys, and Arg are positively charged; and others are polar and uncharged.
1.1.2 Formation of peptide bonds
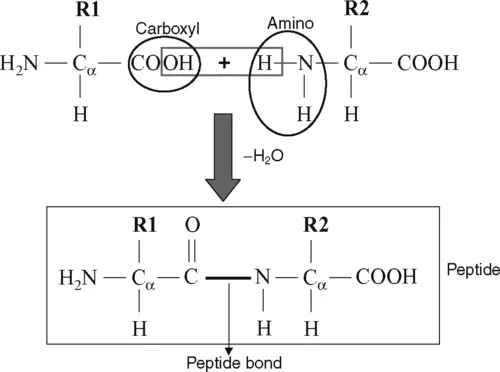
The carboxyl group of one amino acid interacts with the amino group of another to form a peptide bond by the elimination of water (Figure 1.3). Amino acids are joined end-to-end during protein synthesis by the formation of such peptide bonds. The peptide bond (C
N) has a partial double-bond character due to resonance, and hence there is no rotation about the peptide bond. In Figure 1.3, the peptide is represented as a planar unit with the C
O and N
H groups positioning in opposite directions in the plane. This is called trans-peptide. There is another form, cis-peptide in which the C
O and N
H groups point in the same direction. To avoid steric hindrance, the trans form is frequently presented in protein structures for all amino acids except Pro, which has both trans and cis forms. The cis prolines are found in bends of the polypeptide chains.
Figure 1.3 Formation of a peptide bond by the elimination of a water molecule.
A protein chain is formed by several amino acids in which the amino group of the first amino acid and the carboxyl group of the last amino acid remain intact, and the chain is said to extend from the amino (N) to the carboxyl (C) terminus. This chain of amino acids is called a polypeptide chain, main chain, or backbone. Amino acids in a polypeptide chain lack a hydrogen atom at the amino terminal and an OH group at the carboxyl terminal (except at the ends), and hence amino acids are also called amino acid residues (simply residues). Nature selects the combination of amino acid residues to form polypeptide chains for their function, similar to the combination of alpha...
Table of contents
Cover image
Title page
Table of Contents
Copyright page
Dedication
Foreword
Preface
Acknowledgments
Chapter 1: Proteins
Chapter 2: Protein Sequence Analysis
Chapter 3: Protein Structure Analysis
Chapter 4: Protein Folding Kinetics
Chapter 5: Protein Structure Prediction
Chapter 6: Protein Stability
Chapter 7: Protein Interactions
Appendix A
Index
Color Plate
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Protein Bioinformatics by M. Michael Gromiha in PDF and/or ePUB format, as well as other popular books in Biological Sciences & Molecular Biology. We have over 1.5 million books available in our catalogue for you to explore.