
eBook - ePub
Probabilidad y estadística: un enfoque teórico-práctico
Marcos Moya Navarro, Natalia Robles Obando
This is a test
Share book
- 332 pages
- Spanish
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Probabilidad y estadística: un enfoque teórico-práctico
Marcos Moya Navarro, Natalia Robles Obando
Book details
Book preview
Table of contents
Citations
About This Book
La obra Probabilidad y Estadística es el fruto de las experiencias académicas y profesionales de sus autores, así como de sus inquietudes por describir, analizar y simular los fenómenos que se presentan en los campos científicos y prácticos. El material que aquí se presenta se caracteriza por estar orientado especialmente a los problemas comunes de la ingeniería de la producción, de la industrial y de la administración. Su desarrollo es de complejidad creciente y los conceptos tratados se ilustran ampliamente con ejercicios resueltos y problemas para que el estudiante los desarrolle y refuerce así el aprendizaje.
Frequently asked questions
How do I cancel my subscription?
Can/how do I download books?
At the moment all of our mobile-responsive ePub books are available to download via the app. Most of our PDFs are also available to download and we're working on making the final remaining ones downloadable now. Learn more here.
What is the difference between the pricing plans?
Both plans give you full access to the library and all of Perlego’s features. The only differences are the price and subscription period: With the annual plan you’ll save around 30% compared to 12 months on the monthly plan.
What is Perlego?
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 1000+ topics, we’ve got you covered! Learn more here.
Do you support text-to-speech?
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more here.
Is Probabilidad y estadística: un enfoque teórico-práctico an online PDF/ePUB?
Yes, you can access Probabilidad y estadística: un enfoque teórico-práctico by Marcos Moya Navarro, Natalia Robles Obando in PDF and/or ePUB format, as well as other popular books in Mathématiques & Études et recherches mathématiques. We have over one million books available in our catalogue for you to explore.
Information
Topic
MathématiquesCapítulo 1
Estadística descriptiva
La estadística descriptiva es la base fundamental para entender los conceptos de la teoría de la probabilidad y los procesos de inferencia estadística. El nacimiento de la estadística descriptiva inicia con la necesidad de los países de obtener información acerca de sus ciudadanos. Un ejemplo de este hecho se puede observar en el nuevo testamento de la Sagrada Escritura, cuando María y José tienen que ir a Belén para el censo que había ordenado el emperador de ese tiempo.
Por un lado, se define la estadística descriptiva como el conjunto de métodos estadísticos necesarios para la recopilación, presentación y caracterización apropiada de un conjunto de datos.
Por otro lado, se define la inferencia estadística como el proceso de caracterizar una población de datos a partir de la caracterización de una muestra de esa población de datos mediante metodología estadística conocida como métodos de muestreo.
Además, se define una población de datos como la totalidad de los elementos de una característica en particular que se considera en el estudio. Consecuentemente, si el estudio incluye varias características o variables, puede tener varias poblaciones asociadas, es decir, una población asociada a cada una de las características o variables del conjunto de datos. Al conjunto generador de poblaciones se le llamará universo. Por ejemplo, si el universo es la totalidad de los estudiantes de la Escuela de Ingeniería en Producción Industrial del Instituto Tecnológico de Costa Rica, y se consideran el peso, la estatura y el tipo de sangre tres características de interés, entonces existen tres poblaciones asociadas a este universo, una por cada característica de estudio.
Por su tamaño una población puede ser finita o infinita. Cuando una población es muy grande, y por lo tanto difícil de muestrear en su totalidad, se dice que es una población infinitamente medible. Ejemplo de poblaciones infinitamente medibles es el conjunto de los glóbulos rojos del cuerpo humano y el número de granos de arena del desierto del Sahara.
Se define una muestra como una parte de la población. La muestra seleccionada de la población debe ser representativa de esta para que el proceso de inferencia estadística sea confiable. El conjunto de métodos estadísticos para hacer esta selección se conoce como métodos de muestreo.
Un parámetro se define como una medida de una característica de la población que se calcula para describir a la población completa.
Un estadístico se define como una medida de una característica de la población que se calcula a partir de los datos de una muestra.
Tipos de datos
Existen básicamente dos tipos de variables aleatorias que producen dos categorías de datos: datos cualitativos y datos cuantitativos. Se define una variable aleatoria como una variable en la cual no se puede predecir con exactitud el valor que tomará esta variable antes de que ocurra. Un ejemplo típico de una variable aleatoria es el número que saldrá favorecido con el premio mayor en el juego de la lotería del próximo domingo.
Las variables aleatorias cualitativas producen respuestas categóricas, mientras que las variables aleatorias cuantitativas producen respuestas numéricas. Las variables aleatorias cuantitativas se clasifican en variables continuas y variables discretas. Las variables aleatorias discretas surgen de procesos de conteo; las variables aleatorias continuas surgen de procesos de medición. Una variable aleatoria se define como continua si se toma un intervalo de valores de la variable, tan cercanos como se quiera, y aun así existe un valor intermedio de ese intervalo que la variable aleatoria puede tomar.
Se definen cuatro escalas de medición reconocidas para las variables aleatorias: escala nominal, escala ordinal, escala de intervalo y escala de razones.
La escala nominal es la más débil de las cuatro. En esta no se puede intentar medir las diferencias dentro de una categoría o bien determinar quién posee más la propiedad que se está midiendo. Tampoco se puede especificar un orden o dirección de las categorías.
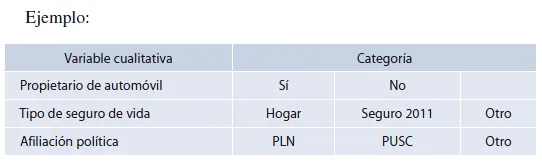
La escala ordinal es más fuerte de medición que la nominal, porque se establece que un valor observado de la variable aleatoria en una categoría posee más o posee menos la propiedad que se está midiendo que algún valor observado que se clasifica en otra categoría. Sin embargo, al igual que en la escala nominal, no se intentan medir las diferencias dentro de una categoría determinada.
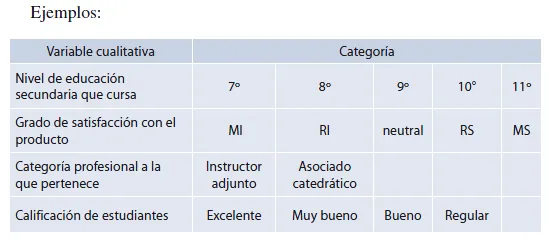
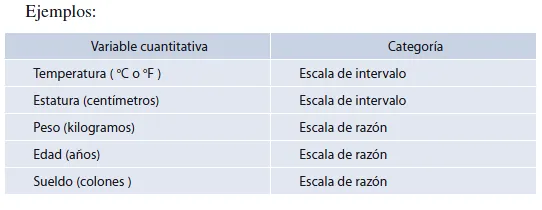
La escala por intervalo es una escala ordenada en la cual se hace diferencia entre las mediciones en una cantidad significativa. Si además de que las diferencias son significativas e iguales en todos los puntos de la escala existe un cero real que permita considerar cocientes de mediciones, entonces se trata de una escala de razones.
Definiciones básicas
Experimento aleatorio
Imagínese una situación en la que un médico investigador está estudiando la efectividad de una nueva droga que ha sido administrada a un grupo de pacientes para curar una cierta enfermedad.
Obtener información relacionada co...