
- 188 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Disk-Based Algorithms for Big Data
About this book
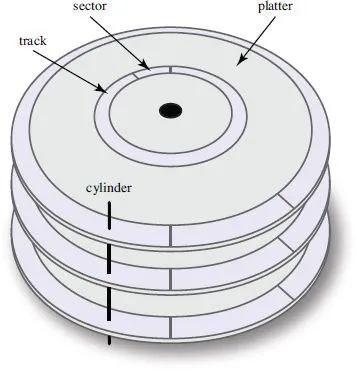
Disk-Based Algorithms for Big Data is a product of recent advances in the areas of big data, data analytics, and the underlying file systems and data management algorithms used to support the storage and analysis of massive data collections. The book discusses hard disks and their impact on data management, since Hard Disk Drives continue to be common in large data clusters. It also explores ways to store and retrieve data though primary and secondary indices. This includes a review of different in-memory sorting and searching algorithms that build a foundation for more sophisticated on-disk approaches like mergesort, B-trees, and extendible hashing.
Following this introduction, the book transitions to more recent topics, including advanced storage technologies like solid-state drives and holographic storage; peer-to-peer (P2P) communication; large file systems and query languages like Hadoop/HDFS, Hive, Cassandra, and Presto; and NoSQL databases like Neo4j for graph structures and MongoDB for unstructured document data.
Designed for senior undergraduate and graduate students, as well as professionals, this book is useful for anyone interested in understanding the foundations and advances in big data storage and management, and big data analytics.
About the Author
Dr. Christopher G. Healey is a tenured Professor in the Department of Computer Science and the Goodnight Distinguished Professor of Analytics in the Institute for Advanced Analytics, both at North Carolina State University in Raleigh, North Carolina. He has published over 50 articles in major journals and conferences in the areas of visualization, visual and data analytics, computer graphics, and artificial intelligence. He is a recipient of the National Science Foundation's CAREER Early Faculty Development Award and the North Carolina State University Outstanding Instructor Award. He is a Senior Member of the Association for Computing Machinery (ACM) and the Institute of Electrical and Electronics Engineers (IEEE), and an Associate Editor of ACM Transaction on Applied Perception, the leading worldwide journal on the application of human perception to issues in computer science.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information

Property | Measurement |
Platters | 3 |
Heads | 6 |
Rotation Speed | 7200 rpm |
Average Seek Delay | 8 ms |
Average Rotation Latency | 4 ms |
Bytes/Sector | 512 |
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Dedication
- Table of Contents
- List of Tables
- List of Figures
- Preface
- CHAPTER 1 ■ Physical Disk Storage
- CHAPTER 2 ■ File Management
- CHAPTER 3 ■ Sorting
- CHAPTER 4 ■ Searching
- CHAPTER 5 ■ Disk-Based Sorting
- CHAPTER 6 ■ Disk-Based Searching
- CHAPTER 7 ■ Storage Technology
- CHAPTER 8 ■ Distributed Hash Tables
- CHAPTER 9 ■ Large File Systems
- CHAPTER 10 ■ NoSQL Storage
- APPENDIX A ■ Order Notation
- APPENDIX B ■ Assignment 1: Search
- APPENDIX C ■ Assignment 2: Indices
- APPENDIX D ■ Assignment 3: Mergesort
- APPENDIX E ■ Assignment 4: B-Trees
- Index
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app