![]()
CHAPTER 1
Physical Disk Storage
FIGURE 1.1 The interior of a hard disk drive showing two platters, read/write heads on an actuator arm, and controller hardware
MASS STORAGE for computer systems originally used magnetic tape to record information. Remington Rand, manufacturer of the Remington typewriter and the UNIVAC mainframe computer (and originally part of the Remington Arms company), built the first tape drive, the UNISERVO, as part of a UNIVAC system sold to the U.S. Census Bureau in 1951. The original tapes were 1,200 feet long and held 224KB of data, equivalent to approximately 20,000 punch cards. Although popular until just a few years ago due to their high storage capacity, tape drives are inherently linear in how they transfer data, making them inefficient for anything other than reading or writing large blocks of sequential data.
Hard disk drives (HDDs) were proposed as a solution to the need for random access secondary storage in real-time accounting systems. The original hard disk drive, the Model 350, was manufactured by IBM in 1956 as part of their IBM RAMAC (Random Access Method of Accounting and Control) computer system. The first RAMAC was sold to Chrysler’s Motor Parts division in 1957. It held 5MB of data on fifty 24-inch disks.
HDDs have continued to increase their capacity and lower their cost. A modern hard drive can hold 3TB or more of data, at a cost of about $130, or $0.043/GB. In spite of the emergence of other storage technologies (e.g., solid state flash memory), HDDs are still a primary method of storage for most desktop computers and server installations. HDDs continue to hold an advantage in capacity and cost per GB of storage.
1.1 PHYSICAL HARD DISK
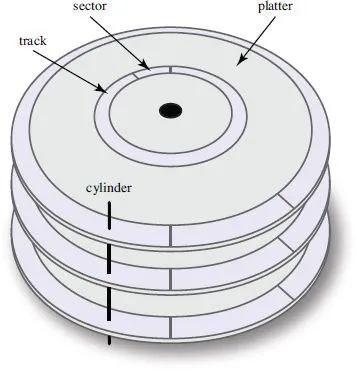
Physical hard disk drives use one or more circular platters to store information (Figure 1.1). Each platter is coated with a thin ferromagnetic film. The direction of magnetization is used to represent binary 0s and 1s. When the drive is powered, the platters are constantly rotating, allowing fixed-position heads to read or write information as it passes underneath. The heads are mounted on an actuator arm that allows them to move back and forth over the platter. In this way, an HDD is logically divided in a number of different regions (Figure 1.2).
• Platter. A non-magnetic, circular storage surface, coated with a ferromagnetic film to record information. Normally both the top and the bottom of the platter are used to record information.
• Track. A single circular “slice” of information on a platter’s surface.
• Sector. A uniform subsection of a track.
• Cylinder. A set of vertically overlapping tracks.
An HDD is normally built using a stack of platters. The tracks directly above and below one another on successive platters form a cylinder. Cylinders are important, because the data in a cylinder can be read in one rotation of the platters, without the need to “seek” (move) the read/write heads. Seeking is usually the most expensive operation on a hard drive, so reducing seeks will significant improve performance.
Sectors within a track are laid out using a similar strategy. If the time needed to process a sector allows n additional sectors to rotate underneath the disk’s read/write heads, the disk’s interleave factor is 1: n. Each logical sector is separated by n positions on the track, to allow consecutive sectors to be read one after another without any rotation delay. Most modern HDDs are fast enough to support a 1: 1 interleave factor.
1.2 CLUSTERS
An operating system (OS) file manager usually requires applications to bundle information into a single, indivisible collection of sectors called a cluster. A cluster is a contiguous group of sectors, allowing the data in a cluster to be read in a single seek. This is designed to improve efficiency.
FIGURE 1.2 A hard disk drive’s platters, tracks, sectors, and cylinders
An OS’s file allocation table (FAT) binds the sectors to their parent clusters, allowing a cluster to be decomposed by the OS into a set of physical sector locations on the disk. The choice of cluster size (in sectors) is a tradeoff: larger clusters produce fewer seeks for a fixed amount of data, but at the cost of more space wasted, on average, within each cluster.
1.2.1 Block Allocation
Rather than using sectors, some OSs allowed users to store data in variable-sized “blocks.” This meant users could avoid sector-spanning or sector fragmentation issues, where data either won’t fit in a single sector, or is too small to fill a single sector. Each block holds one or more logical records, called the blocking factor. Block allocation often requires each block to be preceded by a count defining the block’s size in bytes, and a key identifying the data it contains.
As with clusters, increasing the blocking factor can reduce overhead, but it can also dramatically increase track fragmentation. There are a number of disadvantages to block allocation.
• blocking requires an application and/or the OS to manage the data’s organization on disk, and
• blocking may preclude the use of synchronization techniques supported by generic sector allocation.
1.3 ACCESS COST
The cost of a disk access includes
1. Seek. The time to move the HDD’s heads to the proper track. On average, the head moves a distance equal to ⅓ of the total number of cylinders on the disk.
2. Rotation. The time to spin the track to the location where the data starts. On average, a track spins ½ a revolution.
3. Transfer. The time needed to read the data from the disk, equal to the number of bytes read divided by the number of bytes on a track times the time needed to rotate the disk once.
For example, suppose we have an 8,515,584 byte file divided into 16,632 sectors of size 512 bytes. Given a 4,608-byte cluster holding 9 sectors, we need a sequence of 1,848 clusters occupying at least 264 tracks, assuming a Barracuda HDD with sixty-three 512-byte sectors per track, or 7 clusters per track. Recall also the Barracuda has an 8 ms seek, 4 ms rotation delay, spins at 7200 rpm (120 revolutions per second), and holds 6 tracks per cylinder (Table 1.1).
In the best-case scenario, the data is stored contiguously on individual cylinders. If this is true, reading one track will load 63 sectors (9 sectors per cluster times 7 clusters per track). This involves a seek, a rotation delay, and a transfer of the entire track, which requires 20.3 ms (Table 1.2). We need to read 264 tracks total, but each cylinder holds 6 tracks, so the total transfer time is 20.3 ms per track times 264/6 cylinders, or about 0.9 seconds.
TABLE 1.1 Specifications for a Seagate Barracuda 3TB hard disk drive
Property | Measurement |
Platters | 3 |
Heads | 6 |
Rotation Speed | 7200 rpm |
Average Seek Delay | 8 ms |
Average Rotation Latency | 4 ms |
Bytes/Sector | 512 |
...