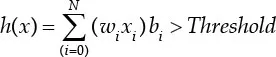Learn how to redesign NLP applications from scratch. Key Features
Get familiar with the basics of any Machine Learning or Deep Learning application.
Understand how does preprocessing work in NLP pipeline.
Use simple PyTorch snippets to create basic building blocks of the network commonly used in NLP.
Get familiar with the advanced embedding technique, Generative network, and Audio signal processing techniques.
Description Natural language processing (NLP) is one of the areas where many Machine Learning and Deep Learning techniques are applied. This book covers wide areas, including the fundamentals of Machine Learning, Understanding and optimizing Hyperparameters, Convolution Neural Networks (CNN), and Recurrent Neural Networks (RNN). This book not only covers the classical concept of text processing but also shares the recent advancements. This book will empower users in designing networks with the least computational and time complexity. This book not only covers basics of Natural Language Processing but also helps in deciphering the logic behind advanced concepts/architecture such as Batch Normalization, Position Embedding, DenseNet, Attention Mechanism, Highway Networks, Transformer models and Siamese Networks. This book also covers recent advancements such as ELMo-BiLM, SkipThought, and Bert. This book also covers practical implementation with step by step explanation of deep learning techniques in Topic Modelling, Text Generation, Named Entity Recognition, Text Summarization, and Language Translation. In addition to this, very advanced and open to research topics such as Generative Adversarial Network and Speech Processing are also covered. What you will learn
Learn how to leveraging GPU for Deep Learning
Learn how to use complex embedding models such as BERT
Get familiar with the common NLP applications
Learn how to use GANs in NLP
Learn how to process Speech data and implementing it in Speech applications
Who this book is for This book is a must-read to everyone who wishes to start the career with Machine learning and Deep Learning. This book is also for those who want to use GPU for developing Deep Learning applications. Table of Contents 1. Understanding the basics of learning Process 2. Text Processing Techniques 3. Representing Language Mathematically 4. Using RNN for NLP 5. Applying CNN In NLP Tasks 6. Accelerating NLP with Advanced Embeddings 7. Applying Deep Learning to NLP tasks 8. Application of Complex Architectures in NLP 9. Understanding Generative Networks 10. Techniques of Speech Processing 11. The Road Ahead About the Authors Sunil Patel has completed his master's in Information Technology from the Indian Institute of Information technology-Allahabad with a thesis focused on investigating 3D protein-protein interactions with deep learning. Sunil has worked with TCS Innovation Labs, Excelra, and Innoplexus before joining to Nvidia. The main areas of research were using Deep Learning, Natural language processing in Banking, and healthcare domain. Sunil started experimenting with deep learning by implanting the basic layer used in pipelines and then developing complex pipelines for a real-life problem. Apart from this, Sunil has also participated in CASP-2014 in collaboration with SCFBIO-IIT Delhi to efficiently predict possible Protein multimer formation and its impact on diseases using Deep Learning. Currently, Sunil works with Nvidia as Data Scientist – III. LinkedIn Profile: https://www.linkedin.com/in/linus1/
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
This chapter covers the most basic aspects of machine learning. It will help you in understanding the basic mathematical representation of learning algorithm and teach you how to design a machine learning model from scratch. After constructing this model, we will understand the methods used to gauge the model’s prediction accuracy using different accuracy metrics. Going further, we will coer the bias-variance problem and diagnose such a problem with a technique called learning curves. Once we get our model correct, we need it to generalize well on unknown datasets that can be understood through a chapter on regularization. After perfecting such a model, it must be efficiently deployed to help improve speed and accuracy.
Structure
In this chapter, we will cover the following topics:
Learning from data
Error/noise reduction
Bias-variance reduction
Learning curves
Regularization
Training and inference
The three learning principles
Objective
Building a simple model for efficient training and gauging the model’s accuracy will be covered in this chapter. It will help you understand the usage of popular software and hardware acceleration for faster training and inference. We’ll end this chapter with three learning principles that are extremely important to machine learning.
Pre-requisites
I have provided some of the examples through code, and the code for this chapter are present in ch1 folder at GitHub repository (https://github.com/bpbpublications/Getting-started-with-Deep-Learning-for-Natural-Language-Processing). Basic know-ledge of the following Python packages is required to understand this chapter:
NumPy
Scikit-Learn
Matplotlib
Pandas
This chapter has one example that uses PyTorch for demonstration. If you don’t know PyTorch, we will cover it in detail in Chapter 2, Text Pre-Processing Techniques in NLP.
Learning from Data
In this data-centric world, a little improvement in the existing application can potentially help earn millions. We all remember a big prize (the $1,000,000) that Netflix gave to the winner for improving the algorithm’s accuracy by 10.06%. A similar opportunity exists in financial planning, be it Forex forecasting or trade market analysis. Minute improvements in such use cases can provide beneficial results. One must explore the entire logic behind the process to improve something; this is what we call learning from data. Machine learning is an interesting area where one can use historical data to make a system capable of identifying observed patterns in the new data. However, machine learning cannot be applied to all problems; a rule of thumb is considered to decide whether machine learning should be applied to a given problem:
There must exist a hidden pattern
We cannot find such a pattern by applying simple mathematical approaches
There must be historical/relevant data about the task concerned
In this chapter, I will start with a basic perceptron model to give you a taste of the learning model. After building the perceptron model, I will discuss Error/Noise and its detection using bias-variance and learning curves. In the learning curve, we will look at how the complexity of the algorithm helps mitigate a high-bias problem. Then, we will cover regularization techniques to achieve better generalization. All these techniques help get a better model, and then it’s time to deploy such a model efficiently. Later in the chapter, we will cover techniques for faster and better inferencing and then look at the three learning principles that are not directly related to machine learning but help in giving state-of-the-art performance. Before going further, we will briefly discuss the mathematical formalization of any supervised learning problem.
Let’s assume that we are talking about supervised learning paradigm. Supervised learning takes finite pairs of X and Y for learning. X and Y can be of the different types according to learning the goals. In the following table, we can see some examples with the nature of X and Y described for different learning problems:
Data
X
Y
Credit card approval
Vector of numerical, categorical, or ordinal values
Two classes: Accept or Reject
Humpback whale identification
Different images
Two or more classes
Sentiment analysis
Text classification
Two or more classes
Wake word identification
Speech classification
Two or more classes
Producing an abstract representation
Detailed text
Summarized text
Producing an abstract representation
Full-length video
Summarized video
Text translation
Text in one language
Translated text in another language
Speech translation
Speech in one language
Translated speech in another language
High-resolution images
Low-resolution image
High-resolution image
Table 1.1
Here, Y is the label for X. Each X and Y is paired, as shown in the following equation:
(X, Y) = ((xi, yi),…,(xn, yn))
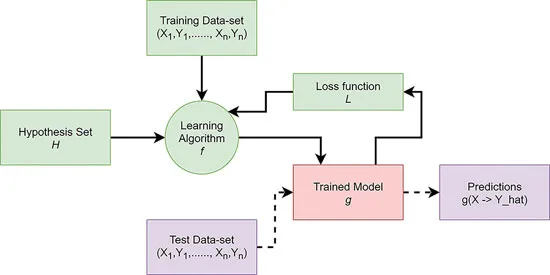
Where xi,…..,xn are individual data points in X, and yi,…..,yn are individual data points in Y. The main task of our hypothesis function f is to apply it over xi to predict ŷi = f(xi). The goal is to predict (ŷi) so that it is the same as or near the original label (yi) and the Error (E) between the predicted label and the original one(|Ŷ – Y|) tends to become 0. The function is (X, Y) = (xi, yi, …, xn, xn). The overall procedure to learn any function can be summarized as in the following flow diagram:
Figure 1.1: Supervise learning paradigm with all major components involved in training and evaluation.
As shown in the preceding figure, any of the hypotheses h is used for making predictions. Here, hypothesis can be anything like Linear, Logistic, Polynomial, SVM, RF, or Neural Network. Hypothesis h is also called function f in general terms.
There are also other types of learning techniques, like unsupervised learning and reinforcement learning. An unsupervised learning paradigm has no label attached to the data; it only has xi,…..,xn ∈ X, and there is no Y label. In fact, unsupervised methodologies are gaining popularity nowadays and are responsible for pushing the state-of-the-art model in the field of vision and NLP even higher. Popular models like Bert and Megatron are examples of unsupervised models. On the other hand, reinforcement learning is a technique where an agent tries to maximize the immediate or cumulative reward by learning/adapting to a given environment. We will learn and apply unsupervised learning to NLP problems in the upcoming chapters.
Implementing the Perceptron Model
Well, this chapter is a little out of sync, but we will discuss the perceptron model. Perceptron with no activation function is a linear model. The perceptron algorithm was invented by Frank Rosenblatt in 1957 at the Cornell Aeronautical Laboratory. To date, this is the most important and widely used model in the course of the machine learning.
Let’s take all the features, that is, xi,…..,xn, and try to derive a hypothesis h that maps y ⇒ ŷ., where ŷ is the predicted label and y is the original label. Our hypothesis h can be one of the simplest possible perceptron models with a linear activation function. The preliminary hypothesis can be thought of as in the following equation:
Where wi are learnable weights, wi changes as per the feedback sign...
Table of contents
Cover Page
Title Page
Copyright Page
Dedication Page
About the Author
About the Reviewer
Acknowledgements
Preface
Errata
Table of Contents
1. Understanding the Basics of Learning Process
2. Text Processing Techniques
3. Representing Language Mathematically
4. Using RNN for NLP
5. Applying CNN in NLP Tasks
6. Accelerating NLP with Transfer Learning
7. Applying Deep Learning to NLP Tasks
8. Application of Complex Architectures in NLP
9. Understanding Generative Networks
10. Techniques of Speech Processing
11. The Road Ahead
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Getting started with Deep Learning for Natural Language Processing by Sunil Patel in PDF and/or ePUB format, as well as other popular books in Computer Science & Cyber Security. We have over 1.5 million books available in our catalogue for you to explore.