Computational Methods for Communication Science showcases the use of innovative computational methods in the study of communication.
This book discusses the validity of using big data in communication science and showcases a number of new methods and applications in the fields of text and network analysis. Computational methods have the potential to greatly enhance the scientific study of communication because they allow us to move towards collaborative large-N studies of actual behavior in its social context. This requires us to develop new skills and infrastructure and meet the challenges of open, valid, reliable, and ethical "big data" research. This volume brings together a number of leading scholars in this emerging field, contributing to the increasing development and adaptation of computational methods in communication science.
The chapters in this book were originally published as a special issue of the journal Communication Methods and Measures.
Trusted by 375,005 students
Access to over 1 million titles for a fair monthly price.
Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology
Daniel Maier, A. Waldherr, P. Miltner, G. Wiedemann, A. Niekler, A. Keinert, B. Pfetsch, G. Heyer, U. Reber, T. Häussler, H. Schmid-Petri, and S. Adam
Abstract
Latent Dirichlet allocation (LDA) topic models are increasingly being used in communication research. Yet, questions regarding reliability and validity of the approach have received little attention thus far. In applying LDA to textual data, researchers need to tackle at least four major challenges that affect these criteria: (a) appropriate pre-processing of the text collection; (b) adequate selection of model parameters, including the number of topics to be generated; (c) evaluation of the model’s reliability; and (d) the process of validly interpreting the resulting topics. We review the research literature dealing with these questions and propose a methodology that approaches these challenges. Our overall goal is to make LDA topic modeling more accessible to communication researchers and to ensure compliance with disciplinary standards. Consequently, we develop a brief hands-on user guide for applying LDA topic modeling. We demonstrate the value of our approach with empirical data from an ongoing research project.
Introduction
Topic modeling with latent Dirichlet allocation (LDA) is a computational content-analysis technique that can be used to investigate the “hidden” thematic structure of a given collection of texts. The data-driven and computational nature of LDA makes it attractive for communication research because it allows for quickly and efficiently deriving the thematic structure of large amounts of text documents. It combines an inductive approach with quantitative measurements, making it particularly suitable for exploratory and descriptive analyses (Elgesem, Steskal, & Diakopoulos, 2015; Koltsova & Shcherbak, 2015).
Consequently, LDA topic models are increasingly being used in communication research. However, communication scholars have not yet developed good-practice guidance for the many challenges a user faces when applying LDA topic modeling. Important methodological decisions must be made that are rarely explained at length in application-focused studies. These decisions relate to at least four challenging questions: (a) How does one pre-process unstructured text data appropriately? (b) How does one select algorithm parameters appropriately, e.g., the number of topics to be generated? (c) How can one evaluate and, if necessary, improve reliability and interpretability of the model solution? (d) How can one validate the resulting topics?
These challenges particularly affect the approach’s reliability and validity, both of which are core criteria for content analysis in communication research (Neuendorf, 2017), but they have, nevertheless, received little attention thus far. This article’s aim is to provide a thorough review and discussion of these challenges and to propose methods to ensure the validity and reliability of topic models. Such scrutiny is necessary to make LDA-based topic modeling more accessible and applicable for communication researchers.
This article is organized as follows. First, we briefly introduce the statistical background of LDA. Second, we review how the aforementioned questions are addressed in studies that have applied LDA in communication research. Third, drawing on knowledge from these studies and our experiences from an ongoing research project, we propose a good-practice approach that we apply to an empirical collection of 186,557 web documents. Our proposal comprises detailed explanations and novel solutions for the aforementioned questions, including a practical guide for users in communication research. In the concluding section, we briefly summarize how the core challenges of LDA topic modeling can be practically addressed by communication scholars in future research.
Statistical background of LDA topic modeling
LDA can be used to identify and describe latent thematic structures within collections of text documents (Blei, 2012). LDA is but one of several statistical algorithms that can be used for topic modeling; however, we are concentrating on LDA here as a general and widely used model. Blei, Ng, and Jordan (2003) introduced LDA as the first approach that allows for modeling of topic semantics entirely within the Bayesian statistical paradigm.
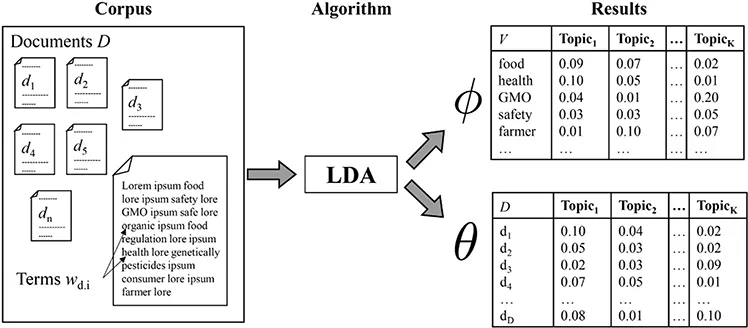
The application of LDA is based on three nested concepts: the text collection to be modelled is referred to as the corpus; one item within the corpus is a document, with words within a document called terms. Thus, documents are nested within the corpus, with terms nested within documents (see Figure 1, left side).
Figure 1. Application of LDA to a Corpus. Note. LDA = latent Dirichlet allocation.
The aim of the LDA algorithm is to model a comprehensive representation of the corpus by inferring latent content variables, called topics. Regarding the level of analysis, topics are heuristically located on an intermediate level between the corpus and the documents and can be imagined as content-related categories, or clusters. A major advantage is that topics are inferred from a given collection without input from any prior knowledge. Since topics are hidden in the first place, no information about them is directly observable in the data. The LDA algorithm solves this problem by inferring topics from recurring patterns of word occurrence in documents.
In their seminal paper, Blei et al. (2003, p. 996) propose that documents can be “represented as random mixtures over latent topics, where each topic is characterized by a distribution over words.” Speaking in statistical terms, the document collection (corpus) can equally be described as a distribution over the latent topics, in which each topic is a distribution over words. In linguistic theories, topics can be seen as factors that consist of sets of words, and documents incorporate such factors with different weights (Lötscher, 1987). Topic models draw on the notion of distributional semantics (Turney & Pantel, 2010) and particularly make use of the so-called bag of words assumption, i.e., the ordering of words within each document is ignored. To grasp the thematic structure of a document, it is sufficient to describe its distribution of words (Grimmer & Stewart, 2013).
Although it appears fairly obvious what a topic is at first glance, there exists no clear-cut established definition of topics in communication research (Günther & Domahidi, 2017, p. 3057). Following Brown and Yule (1983, p. 73), Günther and Domahidi (2017, p. 3057) conclude that a “topic” can only vaguely be described as “what is being talked/written about”. In the context of LDA topic modeling, the concept of a topic also takes on an intuitive and rather “abstract notion” of a topic (Blei et al., 2003, p. 995). However, what topic actually means in theoretical terms remains unclear. The meaning of a topic in an LDA topic model must be assessed empirically instead (Jacobi, Van Atteveldt, & Welbers, 2015, p. 91) and defined against the background of substantive theoretical concepts, such as “political issues” or “frames” (Maier, Waldherr, Miltner, Jähnichen, & Pfetsch, 2017).
LDA’s core: the data-generating process
LDA relies on two matrices to define the latent topical structure: the word-topic assignment matrix ϕ and the document-topic assignment matrix θ (see Figure 1, right side). The word-topic assignment matrix ϕ has two dimensions, K and V, in which K is a numerical value defining the number of proposed topics in the model (which must be determined by the researcher), and V is the total number of words in the vocabulary of the corpus. Thus, any value of ϕw,k signifies the conditional probability with which the word w = 1, …, V is likely to occur in topic k = 1, …, K. Analogously, θ has two dimensions, K and D, in which K, again, describes the number of proposed topics, and D is the number of documents in the corpus. Each value of θd,k discloses the conditional probability with which a topic k is likely to occur in a given document d = 1, …, D (see Figure 1, right side). In practice, the two resulting matrices are guiding the research process and enabling interpretation regarding content. For instance, from ϕ, researchers can identify the most salient, and thereby most characteristic, terms defining a topic, which facilitates the labeling and interpretation of topics. From θ, researchers can read the probability of the topics’ appearance in specific documents; thus, documents may be coded for the presenceby Blei et al. (2003) of salient topics.
The computational core challenge is to estimate the two matrices, ϕ and θ. To master this challenge, Blei et al. (2003) designed a hypothetical statistical generative process within the Bayesian framework that tells us how documents are created and how words from unobserved topics find their way into certain places within a document.
Before we explicate this process, it is important to know that in Bayesian statistics, theoretically rea...
Table of contents
Cover
Half Title
Title Page
Copyright Page
Table of Contents
Citation Information
Notes on Contributors
Introduction: When Communication Meets Computation: Opportunities, Challenges, and Pitfalls in Computational Communication Science
1 Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology
2 Extracting Latent Moral Information from Text Narratives: Relevance, Challenges, and Solutions
3 More than Bags of Words: Sentiment Analysis with Word Embeddings
4 Scaling up Content Analysis
5 How Team Interlock Ecosystems Shape the Assembly of Scientific Teams: A Hypergraph Approach
6 Methods and Approaches to Using Web Archives in Computational Communication Research
7 Disentangling User Samples: A Supervised Machine Learning Approach to Proxy-population Mismatch in Twitter Research
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Computational Methods for Communication Science by Wouter van Atteveldt, Tai-Quan Peng, Wouter van Atteveldt,Tai-Quan Peng in PDF and/or ePUB format, as well as other popular books in Languages & Linguistics & Communication Studies. We have over one million books available in our catalogue for you to explore.