Si desea crear aplicaciones con un sistema de orquestación de contenedores de la mano de auténticos expertos, ha dado con el libro indicado. Esta guía recoge las explicaciones y los consejos de cuatro profesionales que trabajan en el ámbito de Kubernetes y poseen un amplio manejo en sistemas distribuidos, desarrollo de aplicaciones empresariales y código abierto. Asimismo, muchos de los métodos que se presentan en el libro se fundamentan en experiencias de empresas que utilizan Kubernetes con éxito en la fase de producción y están respaldados con ejemplos concretos de código. Gracias a esta guía, esté o no familiarizado con los conceptos básicos de Kubernetes, aprenderá todo lo que necesita para crear las mejores aplicaciones.o Configurar y desarrollar aplicaciones con Kubernetes.o Aprender patrones para monitorizar, asegurar los sistemas, y administrar actualizaciones, implementaciones y procesos de vuelta atrás.o nComprender las políticas de red de Kubernetes y dónde encaja la red de servicios.o Integrar servicios y aplicaciones heredadas, y desarrollar plataformas del más alto nivel con Kubernetes.o Ejecutar tareas de aprendizaje automático en Kubernetes.Este libro es ideal para aquellas personas que están familiarizadas con los conceptos básicos de Kubernetes y que quieren aprender las mejores prácticas que se emplean habitualmente.Brendan Burns es un destacado ingeniero en Microsoft Azure y cofundador del proyecto de código abierto Kubernetes. Eddie Villalba es ingeniero de software en la división de Ingeniería de Software Comercial de Microsoft, y es experto en la nube de código abierto y en Kubernetes.Dave Strebel es arquitecto de la nube nativa global en Microsoft Azure, y es experto en la nube de código abierto y en Kubernetes. Lachlan Evenson es gerente principal del programa en el equipo de cómputo de contenedores en Microsoft Azure

eBook - ePub
Guía práctica de Kubernetes
Proyectos para crear aplicaciones de éxito con Kubernetes
- 316 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Guía práctica de Kubernetes
Proyectos para crear aplicaciones de éxito con Kubernetes
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
CAPÍTULO 1
Configuración de un servicio básico
En este capítulo se describen las prácticas para configurar una sencilla aplicación multinivel en Kubernetes. La aplicación consta de una aplicación web básica y de una base de datos. Aunque seguramente no se trata de la aplicación más complicada, es un buen ejemplo para comenzar a orientarnos en la administración de una aplicación en Kubernetes.
Visión general de la aplicación
La aplicación que usaremos para nuestro ejemplo no es particularmente compleja. Es un sencillo servicio de publicaciones que almacena sus datos en un backend de Redis. Tiene un servidor de archivos estáticos independiente que usa NGINX. Presenta dos rutas web en una sola URL. Una de ellas es para la interfaz de programación de aplicaciones (API) RESTful de la publicación, https://my-host.io/api, y la otra es un servidor de archivos en la URL principal, https://my-host.io. Utiliza el servicio Let’s Encrypt para administrar certificados de la capa de conexión segura (Secure Sockets Layer) (SSL). La Figura 1-1 presenta el diagrama de la aplicación. A lo largo de este capítulo vamos a ir creando esta aplicación, usando en primer lugar archivos de configuración YAML y después diagramas de Helm.
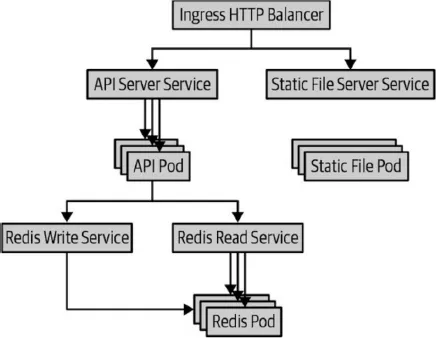
Figura 1-1 Diagrama de la aplicación.
Gestión de archivos de configuración
Antes de exponer en detalle cómo crear esta aplicación en Kubernetes, vale la pena discutir cómo vamos a gestionar las propias configuraciones. Con Kubernetes, todo se representa de forma declarativa. Esto significa que escribimos los estados deseados de la aplicación en el clúster (generalmente en archivos YAML o JSON) y estos estados deseados que se han declarado definen todas las partes de la aplicación. Este enfoque declarativo es mucho más conveniente que un enfoque imperativo, en el que el estado del clúster es la suma de una serie de cambios en el mismo. Si un clúster está configurado de forma imperativa, es muy complicado replicar y entender cómo el clúster ha llegado a estar en ese estado. Esto hace que sea muy difícil comprender la aplicación o recuperarse de los problemas que esta pueda tener.
Cuando se declara el estado de la aplicación, los programadores suelen preferir YAML a JSON, aunque Kubernetes soporta ambos tipos de archivo. Esto se debe a que YAML es algo menos prolijo y más editable que JSON. Sin embargo, vale la pena señalar que YAML es sensible al sangrado. A menudo, los errores en las configuraciones de Kubernetes se deben a un sangrado incorrecto en YAML. Si algo no se comporta como se espera, es aconsejable comprobar el sangrado.
Debido a que el estado declarativo contenido en estos archivos YAML sirve como fuente de verdad para la aplicación, la gestión correcta de este estado es fundamental para lograr nuestros objetivos. Cuando modifiquemos la aplicación para llevarla al estado deseado, nos interesará poder gestionar los cambios, validar que sean correctos, auditar quién realizó esos cambios y, posiblemente, si las cosas fallan poder volver al punto de partida. Afortunadamente, en el contexto de la ingeniería de software, ya hemos desarrollado las herramientas necesarias para gestionar tanto los cambios en el estado declarativo como la auditoría y el proceso de reversión. Es decir, las mejores prácticas se aplican directamente a la tarea de administrar el estado declarativo de la aplicación, en relación tanto con el control de versiones como con la revisión de código.
En la actualidad, la mayoría de los desarrolladores almacenan sus configuraciones de Kubernetes en Git. Aunque los detalles específicos del sistema de control de versiones no son importantes, en el ecosistema de Kubernetes muchas herramientas esperan archivos en un repositorio Git. Para la revisión de código hay mucha más heterogeneidad; aunque claramente GitHub es bastante popular, otros usan herramientas o servicios locales de revisión de código. Independientemente de cómo implementemos la revisión del código para la configuración de la aplicación, debemos tratarla con la misma diligencia y atención que aplicamos al control del código fuente.
Cuando se trata de diseñar el sistema de archivos de la aplicación para organizar los componentes, generalmente vale la pena usar la organización de carpetas que viene con el sistema de archivos. Por lo general, se utiliza un único directorio para incluir Application Service (servicio de la aplicación), cualquiera que sea la definición de Application Service que sea útil para el equipo de trabajo. Dentro de ese directorio, los subdirectorios se utilizan para los subcomponentes de la aplicación.
Para nuestra aplicación, presentamos los archivos de la siguiente manera:
journal/ frontend/ redis/ fileserver/
Dentro de cada directorio se encuentran los archivos YAML específicos que se necesitan para definir el servicio. Como veremos más adelante, a medida que vayamos desplegando nuestra aplicación en varias regiones o clústeres diferentes, la disposición de archivos se irá complicando.
Creación de un servicio replicado mediante Deployments
Para describir nuestra aplicación, comenzaremos por el frontend y trabajaremos hacia abajo. La aplicación frontend para la publicación es una aplicación Node.js implementada en TypeScript. La aplicación completa ocupa demasiado espacio para incluirla en el libro. Presenta un servicio HTTP en el puerto 8080 que atiende peticiones de la ruta / api / * y usa el backend de Redis para añadir, eliminar o devolver las entradas habituales de la publicación. Esta aplicación se puede compilar en una imagen de contenedor utilizando el Dockerfile incluido y se puede enviar a nuestro repositorio de imágenes. Después, sustituimos el nombre de esta imagen en los ejemplos de YAML que vendrán a continuación.
Mejores prácticas para la gestión de imágenes
Aunque, en general, la creación y el mantenimiento de imágenes de contenedores van más allá del alcance de este libro, vale la pena identificar algunas de las mejores prácticas para crear y dar nombre a las imágenes. El proceso de creación de imágenes puede ser vulnerable a «ataques en la cadena de suministro». En tales ataques, un usuario malintencionado inyecta código o dígitos binarios en alguna dependencia desde una fuente confiable que luego se incorpora a la aplicación. Debido al riesgo de tales ataques, es fundamental que cuando procedamos a crear las imágenes confiemos solo en proveedores de imágenes conocidos y confiables. Opcionalmente, podemos crear todas las imágenes desde cero. La creación a partir de cero es fácil para algunos lenguajes (por ejemplo, Go) que pueden crear binarios estáticos, pero es considerablemente más complicada para lenguajes interpretados como Python, JavaScript o Ruby.
Otras buenas prácticas para las imágenes se relacionan con los nombres. Aunque la versión de una imagen de contenedor en un archivo de imágenes es teóricamente mutable, debemos tratar la etiqueta de la versión como inmutable. En particular, alguna combinación de la versión semántica y el hash SHA del commit (confirmación) donde se ha creado la imagen es una buena práctica para nombrar imágenes (por ejemplo, v1.0.1-bfeda01f). Si no especificamos una versión de imagen, se usa la última por defecto. Aunque esto puede ser conveniente en la fase de desarrollo, no es una buena idea para su uso en la fase de producción porque la última cambia cada vez que se crea una nueva imagen.
Creación de una aplicación replicada
Nuestra aplicación de frontend es apátrida. Para su estado depende totalmente del backend de Redis. Como consecuencia, podemos replicarla arbitrariamente sin afectar al tráfico. Aunque es poco probable que la aplicación soporte un uso a gran escala, es una buena idea que se ejecute en al menos dos réplicas para poder resolver una caída inesperada o poner en marcha una nueva versión de la aplicación sin paradas.
Aunque en Kubernetes ReplicaSet es el recurso que gestiona la replicación de una aplicación contenida en un contenedor, no es una buena práctica utilizarlo directamente. En su lugar, se utiliza el recurso Deployment (implementación). Deployment combina las capacidades de replicación de ReplicaSet con el versionado y la capacidad de realizar un despliegue por etapas. Mediante el uso de Deployment podemos utilizar las herramientas incorporadas en Kubernetes para pasar de una versión de la aplicación a la siguiente.
El recurso Deployment para nuestra aplicación tiene el siguiente aspecto:
apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: frontend name: frontend namespace: default spec: replicas: 2 selector: matchLabels: app: frontend template: metadata: labels: app: frontend spec: containers: - image: my-repo/journal-server:v1-abcde imagePullPolicy: IfNotPresent name: frontend resources: request: cpu: "1.0" memory: "1G" limits: cpu: "1.0" memory: "1G"
Hay varias cosas a tener en cuenta en este Deployment. La primera es que utilizamos Labels (etiquetas) para identificar el Deployment, así como los ReplicaSets y las pods (cápsulas) que crea Deployment. Hemos añadido la etiqueta layer: frontend a todos estos recursos para que podamos examinar todos los recursos de una capa en particular en una sola petición. Esto lo veremos a medida que añadamos otros recursos, donde seguiremos el mismo procedimiento.
Además, hemos añadido comentarios en varias partes de YAML, aunque estos comentarios no se convierten en un recurso de Kubernetes almacenado en el servidor. Como ocurre con los comentarios en el código, sirven de ayuda para orientar a los desarrolladores que analizan la configuración por primera vez.
También debemos tener en cuenta que para los contenedores en Deployment hemos especificado tanto las peticiones de recursos de Request (solicitud) como las de Limit (límite), y hemos establecido que Request es igual a Limit. Cuando se ejecuta una aplicación, Request es la reserva de recursos que se garantiza en la máquina host (anfitriona) en la que se ejecuta. Limit indica la cantidad máxima de recursos que se le permitirá usar al contenedor. Cuando empezamos, al establecer Request igual a Limit (solicitud igual a límite) se consigue el comportamiento más previsible de la aplicación. Esta previsibilidad se produce a expensas de la utilización de recursos. Dado que la configuración en la que Request es igual a Limit evita que las aplicaciones se sobreprogramen o consuman recursos inútiles, no podremos impulsar la utilización óptima a menos que ajustemos Request y Limit muy cuidadosamente. A medida que avancemos en la comprensión del modelo de recursos de Kubernetes, podremos considerar modificar Request y Limit en la aplicación de forma independiente. Pero, en general, la mayor parte de los usuarios cree que merece la pena la estabilidad de la previsibilidad frente a lo que se reduce su utilización.
Ahora que tenemos definido el recurso Deployment, lo comprobaremos en el control de versiones y lo desplegaremos en Kubernetes:
git add frontend/deployment.yaml git commit -m "Added deployment" frontend/deployment.yaml kubectl apply -f frontend/deployment.yaml
También es una buena práctica comprobar que el contenido del clúster coincide exactamente con el contenido del control del código fuente. La mejor forma de comprobarlo es adoptar una aproximación GitOps y hacer el despliegue en producción solo desde una rama específica del control del código fuente, utilizando la automatización de Continuous Integration (integración continua) (CI)/Continuous Delivery (entrega continua) (CD). De esta manera, se garantiza que los contenidos del control del código fuente y producción coinciden. Aunque una pipeline (canalización) CI/CD completa puede parecer excesiva para una aplicación sencilla, la automatización en sí misma —independientemente de la fiabilidad que proporciona— normalmente merece la pena, a pesar del tiempo que conlleva montarla. Y CI/CD es extremadamente difícil de reequipar en una aplicación existente e implementada con un enfoque imperativo.
Hay algunas partes de esta descripción de la aplicación YAML (por ejemplo, ConfigMap y los volúmenes secret), así como la Quality of Service (calidad de servicio) de las cápsulas, que examinamos en secciones posteriores.
Configuración de Ingress externa para tráfico HTTP
Los contenedores de nuestra aplicación ya están implementados, pero en este momento no es posible acceder a la aplicación. Por defecto, los recursos del clúster solo están disponibles dentro del mismo clúster. Para presentar nuestra aplicación al mundo, necesitamos crear un Service (servicio) y un balanceador de carga para proporcionar una dirección IP externa y traer tráfico a nuestros contenedores. Para la presentación externa vamos a usar dos recursos de Kubernetes. El primero es un Service que equilibra la carga de tráfico de Transmission Control Protocol (protocolo de control de transmisión) (TCP) o de User Datagram Protocol (protocolo de datagrama de usuario) (UDP). En nuestro caso, usamos el protocolo TCP. Y el segundo es un recurso Ingress (acceso), que proporciona balanceo de carga HTTP(S) con enrutamiento inteligente de peticiones basado en rutas y hosts HTTP. Con una aplicación tan sencilla como esta, te preguntarás por qué elegimos usar la Ingress más compleja. Pero, como verás en secciones posteriores, incluso esta sencilla aplicación servirá peticiones HTTP desde dos servicios diferentes. Además, al disponer de Ingress tenemos la ventaja de contar con cierta flexibilidad en caso de una futura expansión de nuestro servicio.
Antes de que se pueda definir el recurso Ingress, es necesario que exista un Service de Kubernetes al que Ingress apunte. Usaremos Labels (etiquetas) para dirigir el Service a las cápsulas que hemos creado en la sección anterior. Service es considerablemente más sencillo de definir que Deployment, y se ve de la siguiente ...
Table of contents
- Cubierta
- Título
- Créditos
- Contenidos
- Prefacio
- Reconocimientos
- 1. Configuración de un servicio básico
- 2. Flujos de trabajo para desarrolladores
- 3. Monitorización y recopilación de registros en Kubernetes
- 4. Configuración, Secrets y RBAC
- 5. Integración continua, pruebas y despliegue
- 6. Versionado, versiones de lanzamiento y puesta en marcha
- 7. Distribución y preproducción de aplicaciones a nivel mundial
- 8. Administración de recursos
- 10. Seguridad de cápsulas y contenedores
- 11. Política y gobierno del clúster
- 12. Administración de varios clústeres
- 13. Integración de servicios externos y Kubernetes
- 14. Ejecución de aprendizaje automático en Kubernetes
- 15. Creación de patrones de aplicaciones de alto nivel sobre Kubernetes
- 16. Gestión de aplicaciones con estado y apátridas
- 17. Control de admisión y autorización
- 18. Conclusión
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Guía práctica de Kubernetes by Brendan Burns, Eddie Villalba, Dave Strebel, Lachlan Evenson in PDF and/or ePUB format, as well as other popular books in Computer Science & Programming. We have over 1.5 million books available in our catalogue for you to explore.