![]()
PART ONE
BASICS OF DNA, CHROMOSOMES, CELLS, DEVELOPMENT AND INHERITANCE
1 Basic principles of nucleic acid structure and gene expression
2 Fundamentals of cells and chromosomes
3 Fundamentals of cell–cell interactions and immune system biology
4 Aspects of early mammalian development, cell differentiation, and stem cells
5 Patterns of inheritance
![]()
1
Basic principles of nucleic acid structure and gene expression
Molecular genetics is largely defined by the interplay between three classes of macromolecule: the nucleic acid molecules, DNA (deoxyribonucleic acid) and RNA (ribonucleic acid), and proteins. In organisms and cells, DNA is the genetic (hereditary) material that is transmitted to daughter cells when cells replicate, and from one generation to the next when organisms reproduce. Viruses also have genetic material that is transmitted to viral progeny; according to the type of virus, the genetic material may be DNA or RNA. The term genome is the collective name for the set of different DNA molecules in an organism, cell, or DNA virus, or of RNA molecules in an RNA virus. All proteins have a polypeptide core that is synthesized using genetic information within DNA molecules (or within the hereditary RNA molecules of an RNA virus).
RNA may have been the hereditary material at a very early stage of evolution, but now, except in certain viruses, it no longer serves this role. Instead, the genetic information in cells came to be stored in DNA molecules (which are more chemically stable than RNA and can be copied accurately and transmitted to daughter cells, and from one generation to the next). In eukaryotes, DNA molecules are found mainly in the chromosomes of the nucleus, but the mitochondria of all eukaryotic cells also have small DNA molecules, as do the chloroplasts of plant cells.
Genes are segments of hereditary DNA or RNA molecules that are used to make one or both of two types of functional end product: a polypeptide or a mature functional RNA. Both types of product are then subject to processing reactions to make a working molecule. For example, a polypeptide may be subject to cleavage and/or to minor chemical changes to its constituent components, and may often also be complexed with other molecules including carbohydrates, lipids, or other polypeptides in order to make a working protein.
In simple organisms, the DNA is packed with genes (bacteria typically have from several hundred up to a few thousand different genes packed within 1–10 Mb [megabases] of DNA). In the more complex cells of eukaryotes, the genes are usually much more sparsely distributed within the DNA, and in complex multicellular eukaroytes much of the DNA consists of highly-repetitive sequences (whose functions are often not so readily easily identified).
There are many different types of RNA molecule, but according to their function they can be divided into two broad classes. A coding RNA sequence, popularly called a messenger RNA (mRNA), carries genetic information from DNA to the protein synthesis machinery. Messenger RNA made in the nucleus needs to be exported to the cytoplasm to make proteins, but the messenger RNA synthesized in mitochondria and chloroplasts is used to make certain proteins within these organelles.
Mature noncoding RNA sequences are the second broad class of RNA. They are not used as a template to make polypeptides. Instead, they often assist the expression of other genes, sometimes acting in a fairly general way and sometimes by regulating the expression of a small set of target genes. Because most gene expression is ultimately dedicated to making polypeptides, either directly or by regulating how they are produced, proteins represent the major functional endpoint of the information stored in DNA.
The central dogma of molecular biology
Genetic information generally flows in a one-way direction: DNA is decoded to make RNA, and then coding RNA (messenger RNA) is used to make polypeptides that subsequently form proteins. Because of its universality, this flow of genetic information has been described as the central dogma of molecular biology. Two sequential processes are essential in all cellular organisms:
- Transcription, by which a sequence of bases on a DNA strand is used as a template by an RNA polymerase to synthesize an RNA; the RNA product is processed to make a messenger RNA (coding RNA) or noncoding RNA;
- Translation, by which a messenger RNA is decoded to make polypeptides at ribosomes, large RNA–protein complexes found in the cytoplasm and also in mitochondria and chloroplasts.
Genetic information is encoded in the linear sequence of nucleotides in DNA. That information is copied during transcription to specify a linear sequence of nucleotides in the RNA product. In the case of a coding RNA, groups of three nucleotides at a time (codons) are read in a linear sequence to specify a linear sequence of amino acids in the polypeptide product.
The central dogma is now recognized to be not strictly valid. A class of RNA virus known as retroviruses provided the first evidence. These viruses have an RNA genome with a gene that makes a reverse transcriptase, a DNA polymerase that uses an RNA template to make a DNA sequence copy. Thereafter, it became clear that cellular reverse transcriptases also exist. We now know that many DNA sequences in our cells specify reverse transcriptases to allow DNA copies to be made from different RNAs. This reverse flow of genetic information from RNA to DNA has been important in the evolution of our genome (as described in Chapter 13), and in replicating the DNA sequences at the very ends of linear chromosomes (described in Chapter 2).
1.1 COMPOSITION OF NUCLEIC ACIDS AND POLYPEPTIDES
We describe below the structure of nucleic acids and proteins. All proteins have a linear polypeptide backbone (encoded by a gene) to which carbohydrate, lipid, and small chemical groups may be added at the post-translational level. Here we describe the component units of nucleic acids and polypeptides, and the different types of chemical bonding within these macromolecules.
Nucleic acids and polypeptides are linear sequences of simple repeat units
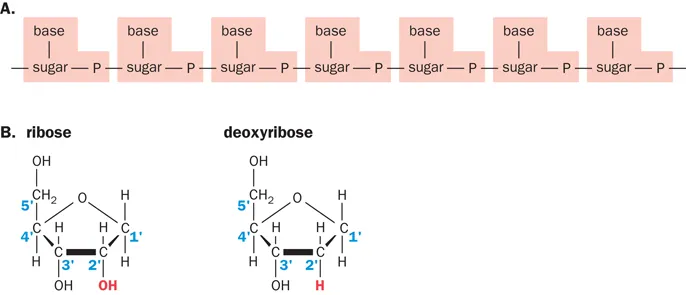
DNA and RNA strands are large polymers that have very similar structures. Each has a linear sugar–phosphate backbone that has alternating residues of a five-carbon sugar and a phosphate, with a nitrogenous base attached to each sugar residue (Figure 1.1A). The sugars are ribose in RNA and deoxyribose in DNA, and they differ in either lacking or possessing an –OH group at their 2′-carbon positions (Figure 1.1B).
Figure 1.1 Repeat units in nucleic acids. (A) The linear backbone of nucleic acids consists of alternating phosphate (P) and sugar residues. Attached to each sugar is a base. The basic repeat unit (pale peach shading) consists of a base + sugar + phosphate = a nucleotide. (B) Ribose, the sugar in RNA, and deoxyribose, the sugar in DNA, both have five carbon atoms numbered 1′ to 5′. Deoxyribose lacks the hydroxyl (OH) group attached to carbon 2 of ribose (the proper name is 2′-deoxyribose).
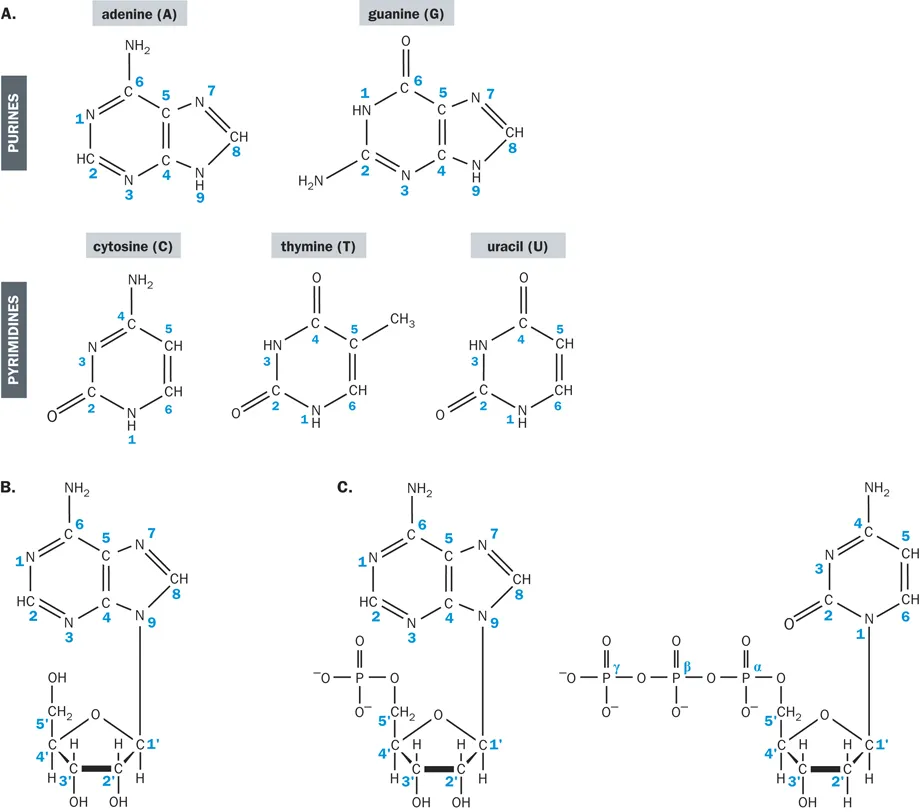
Unlike the sugar and phosphate residues, the bases of a nucleic acid molecule vary, and it is the sequence of bases that identifies the nucleic acid and determines its function. The bases of a nucleic acid each consist of heterocyclic rings of carbon and nitrogen atoms and can be divided into two structural classes: purines, which have two interlocked rings, and pyrimidines, which have a single ring. In both DNA and RNA there are four principal types of base, two purines and two pyrimidines. Three types of base adenine (A), cytosine (C), and guanine (G) are common to both DNA and RNA. The fourth base is thymine (T) in DNA and the closely related uracil (U) in RNA. Uracil lacks the 5-methyl group found in thymine (Figure 1.2A).
Figure 1.2 Purines, pyrimidines, nucleosides, and nucleotides. (A) The common bases in nucleic acids. The bases A, C, and G occur in both DNA and RNA, but T is found in DNA while U is a closely related analog found in RNA. (B and C) Examples of nucleosides and nucleotides. A nucleoside is a base + sugar residue, as shown by the example in (B), which is adenosine. A nucleotide is a nucleoside + phosphate group attached to the 3′ or 5′ carbon of the sugar. The two examples shown in (C) are adenosine 5′-monophosphate (AMP; left) and 2′-deoxycytidine 5′-triphosphate (dCTP; at the right). The bold lines at the bottom of the ribose and deoxyribose rings mean that the plane of the sugar ring is at an angle of 90° with respect to the plane of the chemical groups that are linked to the 1′ to 4′ carbon atoms within the ring. If the plane of the base is represented as lying on the surface of the page, the 2′ and 3′ carbons of the sugar could be viewed as projecting upward out of the page, while the oxygen atom of the sugar ring projects downward below the surface of the page. Phosphate groups are numbered sequentially (α, β, γ, etc.), according to their distance from the sugar ring.
In nucleic acids, each base is covalently attached to the sugar by an N-glycosidic bond that joins a nitrogen atom (nitrogen 1 of a pyrimidine or nitrogen 9 of a purine) to the carbon 1′ (one prime) of the sugar. A sugar with an attached base is called a nucleoside (Figure 1.2B). A nucleoside with a phosphate group attached at the 5′ or 3′ carbon of the sugar is the basic repeat unit of a DNA strand, and is called a nucleotide (Figure 1.2C...