The need to enhance speech signals arises in many situations in which the speech signal originates from a noisy location or is affected by noise over a communication channel. There are a wide variety of scenarios in which it is desired to enhance speech. Voice communication, for instance, over cellular telephone systems typically suffers from background noise present in the car, restaurant, etc. at the transmitting end. Speech enhancement algorithms can therefore be used to improve the quality of speech at the receiving end. That is, they can be used as a preprocessor in speech coding systems employed in cellular phone standards (e.g., [1]). If the cellular phone is equipped with a speech recognition system for voice dialing, then recognition accuracy will likely suffer in the presence of noise. In this case, the noisy speech signal can be preprocessed by a speech enhancement algorithm before being fed to the speech recognizer. In an air–ground communication scenario, speech enhancement techniques are needed to improve quality, and preferably intelligibility, of the pilot’s speech that has been corrupted by extremely high levels of cockpit noise. In this, as well as in similar communication systems used by the military, it is more desirable to enhance the intelligibility rather than the quality of speech. In a teleconferencing system, noise sources present in one location will be broadcast to all other locations. The situation is further worsened if the room is reverberant. Enhancing the noisy signal prior to broadcasting it will no doubt improve the performance of the teleconferencing system. Finally, hearing impaired listeners wearing hearing aids (or cochlear implant devices) experience extreme difficulty communicating in noisy conditions, and speech enhancement algorithms can be used to somehow preprocess or “clean” the noisy signal before amplification.
The foregoing examples illustrate that the goal of speech enhancement varies depending on the application at hand. Ideally, we would like speech enhancement algorithms to improve both quality and intelligibility. It is possible to reduce the background noise, but at the expense of introducing speech distortion, which in turn may impair speech intelligibility. Hence, the main challenge in designing effective speech enhancement algorithms is to suppress noise without introducing any perceptible distortion in the signal. Thus far, most speech enhancement algorithms have been found to improve only the quality of speech. The last chapter included in the second edition provides future steps that can be taken to develop algorithms that can improve speech intelligibility.
The solution to the general problem of speech enhancement depends largely on the application at hand, the characteristics of the noise source or interference, the relationship (if any) of the noise to the clean signal, and the number of microphones or sensors available. The interference could be noise-like (e.g., fan noise) or speech-like such as an environment (e.g., restaurant) with competing speakers. Acoustic noise could be additive to the clean signal or convolutive if it originates from a highly reverberant room. Furthermore, the noise may be statistically correlated or uncorrelated with the clean speech signal. The number of microphones available can influence the performance of speech enhancement algorithms. Typically, the larger the number of microphones, the easier the speech enhancement task becomes. Adaptive cancellation techniques can be used when at least one microphone is placed near the noise source.
This book focuses on enhancement of speech signals degraded by statistically uncorrelated (and independent) additive noise. The enhancement algorithms described in this book are not restricted to any particular type of noise, but can be generally applied to a wide variety of noise sources (more on this later). Furthermore, it is assumed that only the noisy signal, containing both the clean speech and additive noise, is available from a single microphone for speech enhancement. This situation constitutes one of the most challenging problems in speech enhancement since it assumes no access to a reference microphone that picks up the noise signal.
1.1 UNDERSTANDING THE ENEMY: NOISE
Prior to designing algorithms to combat additive noise, it is crucial to understand the behavior of various types of noise, the differences between the noise sources in terms of temporal and spectral characteristics, and the range of noise levels that may be encountered in real life.
We are surrounded by noise wherever we go. Noise is present, for instance, in the street (e.g., cars passing by, street construction work), in the car (e.g., engine noise, wind), the office (e.g., PC fan noise, air ducts), the restaurant (e.g., people talking in nearby tables), and the department stores (e.g., telephone ringing, sales representatives talking). As these examples illustrate, noise appears in different shapes and forms in daily life.
Noise can be stationary, that is, does not change over time, such as the fan noise coming from PCs. Noise can also be nonstationary, such as the restaurant noise, that is, multiple people speaking in the background mixed in some cases with noise emanating from the kitchen. The spectral (and temporal) characteristics of the restaurant noise are constantly changing as people carry on conversations in neighboring tables and as the waiters keep interact and converse with people. Clearly, the task of suppressing noise that is constantly changing (nonstationary) is more difficult than the task of suppressing stationary noise.
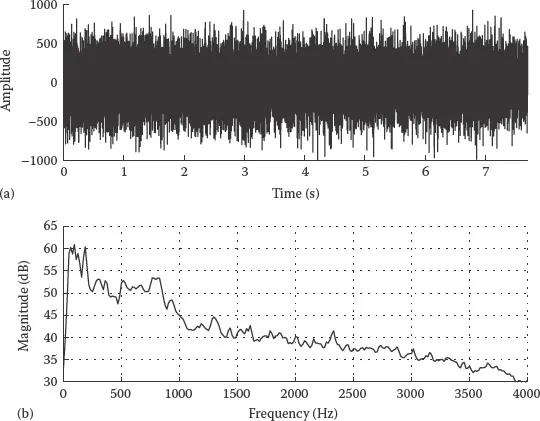
FIGURE 1.1 (a) Example noise from a car and (b) its long-term average spectrum.
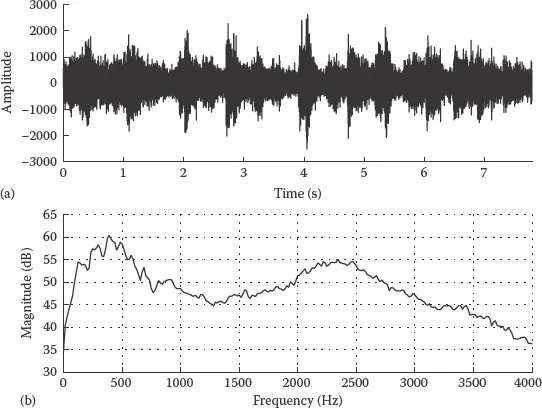
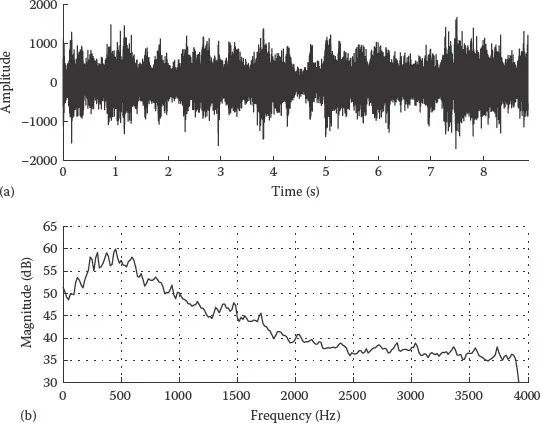
Another distinctive feature of the various types of noise is the shape of their spectrum, particularly as it relates to the distribution of noise energy in the frequency domain. For instance, the main energy of wind noise is concentrated in the low frequencies, typically below 500 Hz. Restaurant noise, on the other hand, occupies a wider frequency range. Figures 1.1 through 1.3 show example time waveforms of car noise, train noise, and restaurant noise (noise sources were taken from the NOIZEUS corpus [2], which is included in the DVD of this book). The corresponding long-term average spectra of these noise sources are also shown. In these three example noise sources, the car noise (Figure 1.1) is relatively stationary but the train and restaurant noises are not. It is clear from Figures 1.1 through 1.3 that the differences between these three types of noise sources are more evident in the frequency domain rather than the time domain. Most of energy of the car noise is concentrated in the low frequencies, that is, it is low-pass in nature. The train noise, on the other hand, is more broadband as it occupies a wider frequency range.
1.1.2 NOISE AND SPEECH LEVELS IN VARIOUS ENVIRONMENTS
Critical to the design of speech enhancement algorithms is knowledge of the range of speech and noise intensity levels in real-world scenarios. From that, we can estimate the range of signal-to-noise ratio (SNR) levels encountered in realistic environments. This is important since speech enhancement algorithms need to be effective in suppressing the noise and improving speech quality within that range of SNR levels.
FIGURE 1.2 (a) Example noise from a train and (b) its long-term average spectrum.
FIGURE 1.3 (a) Example noise from a restaurant and (b) its long-term average spectrum.
A comprehensive analysis and measurement of speech and noise levels in real- world environments was done by Pearsons et al. [3]. They considered a variety of environments encountered in daily life, which included classrooms, urban and suburban houses (inside and outside), hospitals (nursing stations and patient rooms), department stores, trains, and airplanes. The speech and noise levels were measured using sound level meters. The measurements were reported in dB sound pressure level (SPL) (dB SPL is the relative pressure of sound in reference to 0.0002 dynes/cm2, corresponding to the barely audible sound pressure). As the distance between the speaker and the listener can affect the sound intensity levels, measurements were made with the microphone placed at different distances. Typical distance in face-to-face communication is one meter, and for every doubling of that distance, the sound level is reduced by 6 dB [4]. In certain scenarios (e.g., in transportation vehicles such as trains and airplanes), the distance in face-to-face communication may be reduced to 0.4 m [3].
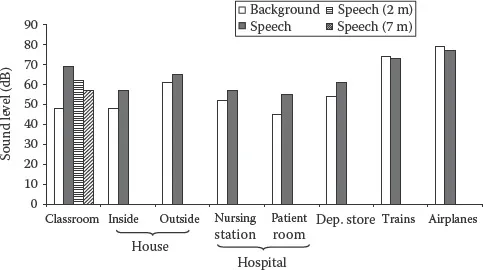
Figure 1.4 summarizes the average speech and noise levels measured in various environments. Noise levels are the lowest in the classroom, hospital, inside the house, and in the department stores. In these environments, noise levels range between 50 and 55 dB SPL. The corresponding speech levels range between 60 and 70 dB SPL. This suggests that the effective SNR levels in these environments range between 5 and 15 dB. Noise levels are particularly high in trains and airplanes, averaging about 70–75 dB SPL. The corresponding speech levels are roughly the same, suggesting that the effective SNR levels in these two environments are near 0 dB. In classrooms, the effective SNR for students closest to the teacher are most favorable (Figure 1.4), but for those sitting in the back of the classroom it is quite unfavorable as the SNR may approach 0 dB. Noise levels are also high in restaurants and in most cases exceed 65 dB SPL [4]. Generally, it is rare to find a quiet restaurant, as the architectural design of restaurants focuses more on the aesthetics rather than on the acoustics of the interior walls [4]. The study in [5] measured the noise levels in 27 San Francisco Bay Area restaurants and found a median noise level of 72 dBA SPL. The range in noise levels varied across different types of restaurants from a low of 59 dBA SPL (family restaurant) to a high of 80 dBA SPL (bistro). In food courts of shopping malls, the range of noise levels varied from 76 to 80 dBA SPL [6].
FIGURE 1.4 Average noise and speech levels (measured in dB SPL) in various environments.
Note that the speech levels increase in extremely high background noise levels (Figure 1.4). Generally, when the noise level goes beyond 45 dB SPL, people tend to raise their voice levels, a phenomenon known as Lombard effect [7]. The speech level tends to increase with the background level by about 0.5 dB for every 1 dB increase in background level [3]. People stop raising their voice when the ambient noise level goes beyond 70 dB SPL (Figure 1.4). The raising of the voice level is a simple, and efficient, technique that most people use to improve their “listening SNR” whenever in extremely noisy environments.
In brief, for the speech enhancement algorithm to be employed in a practical application it needs to operate, depending on the vocal effort (e.g., normal, raised), within a range of signal-to-noise levels (−5 to 15 dB).
1.2 CLASSES OF SPEECH ENHANCEMENT ALGORITHMS
A number of algorithms have been proposed in the literature for speech enhancement (for an old review of enhancement algorithms, see [8]) with the primary goal of improving speech quality. These algorithms can be divided into three main classes:
1. Spectral subtractive algorithms: These are, by far, the simplest enhancement algorithms to implement. They are based on the basic principle that as the noise is additive, one can estimate/update the noise spectrum when speech is not present and subtract it from the noisy signal. Spectral subtractive algorithms were initially proposed by Weiss et al. [9] in the correlation domain and later by Boll [10] in the Fourier transform domain.
2. Statistical-model-based algorithms: The speech enhancement problem is posed in a statistical estimation framework. Given a set of measurements, corresponding say to the Fourier transform coefficients of the noisy signal, we wish to find a linear (or nonlinear) estimator of the parameter of interest, namely, the transform coefficients of the clean signal. The Wiener algorithm and minimum mean square error (MMSE) algorithms, among others, fall in this category. Work in this area was initiated by McAulay and Malpass [11] who proposed a maximum-likelihood approach for estimating the Fourier transform coefficients (spectrum) of the clean signal, followed by the work by Ephraim and Malah [12] who proposed an MMSE estimator of the magnitude spectrum. Much of the work with the Wiener algorithm was initiate...