Section 1: Introduction to Automated Machine Learning
This part provides a detailed introduction to the landscape of automated machine learning, its pros and cons, and how it can be applied using open source tools and libraries. In this section, you will come to understand, with the aid of hands-on coding examples, that automated machine learning techniques are diverse, and there are different approaches taken by different libraries to address similar problems.
This section comprises the following chapters:
- Chapter 1, A Lap around Automated Machine Learning
- Chapter 2, Automated Machine Learning, Algorithms, and Techniques
- Chapter 3, Automated Machine Learning with Open Source Tools and Libraries
Chapter 1: A Lap around Automated Machine Learning
"All models are wrong, but some are useful."
– George Edward Pelham Box FRS
"One of the holy grails of machine learning is to automate more and more of the feature engineering process."
– Pedro Domingos, A Few Useful Things to Know about Machine Learning
This chapter will provide an overview of the concepts, tools, and technologies surrounding automated Machine Learning (ML). This introduction hopes to provide both a solid overview for novices and serve as a reference for experienced ML practitioners. We will start by introducing the ML development life cycle while navigating through the product ecosystem and the data science problems it addresses, before looking at feature selection, neural architecture search, and hyperparameter optimization.
It's very plausible that you are reading this book on an e-reader that's connected to a website that recommended this manuscript based on your reading interests. We live in a world today where your digital breadcrumbs give telltale signs of not only your reading interests, but where you like to eat, which friend you like most, where you will shop next, whether you will show up to your next appointment, and who you would vote for. In this age of big data, this raw data becomes information that, in turn, helps build knowledge and insights into so-called wisdom.
Artificial Intelligence (AI) and its underlying implementations of ML and deep learning help us not only find the metaphorical needle in the haystack, but also to see the underlying trends, seasonality, and patterns in these large data streams to make better predictions. In this book, we will cover one of the key emerging technologies in AI and ML; that is, automated ML, or AutoML for short.
In this chapter, we will cover the following topics:
- The ML development life cycle
- Automated ML
- How automated ML works
- Democratization of data science
- Debunking automated ML myths
- Automated ML ecosystem (open source and commercial)
- Automated ML challenges and limitations
Let's get started!
The ML development life cycle
Before introducing you to automated ML, we should first define how we operationalize and scale ML experiments into production. To go beyond Hello-World apps and works-on-my-machine-in-my-Jupyter-notebook kinds of projects, enterprises need to adapt a robust, reliable, and repeatable model development and deployment process. Just as in a software development life cycle (SDLC), the ML or data science life cycle is also a multi-stage, iterative process.
The life cycle includes several steps – the process of problem definition and analysis, building the hypothesis (unless you are doing exploratory data analysis), selecting business outcome metrices, exploring and preparing data, building and creating ML models, training those ML models, evaluating and deploying them, and maintaining the feedback loop:
Figure 1.1 – Team data science process
A successful data science team has the discipline to prepare the problem statement and hypothesis, preprocess the data, select the appropriate features from the data based on the input of the Subject-Matter Expert (SME) and the right model family, optimize model hyperparameters, review outcomes and the resulting metrics, and finally fine-tune the models. If this sounds like a lot, remember that it is an iterative process where the data scientist also has to ensure that the data, model versioning, and drift are being addressed. They must also put guardrails in place to guarantee the model's performance is being monitored. Just to make this even more interesting, there are also frequent champion challenger and A/B experimentations happening in production – may the best model win.
In such an intricate and multifaceted environment, data scientists can use all the help they can get. Automated ML extends a helping hand with the promise to take care of the mundane, the repetitive, and the intellectually less efficient tasks so that the data scientists can focus on the important stuff.
Automated ML
"How many members of a certain demographic group does it take to perform a specified task?"
"A finite number: one to perform the task and the remainder to act in a manner stereotypical of the group in question." <insert your light bulb joke here>
This is meta humor – the finest type of humor for ensuing hilarity for those who are quantitatively inclined. Similarly, automated ML is a class of meta learning, also known as learning to learn – the idea that you can apply the automation principles to themselves to make the process of gaining insights even faster and more elegant.
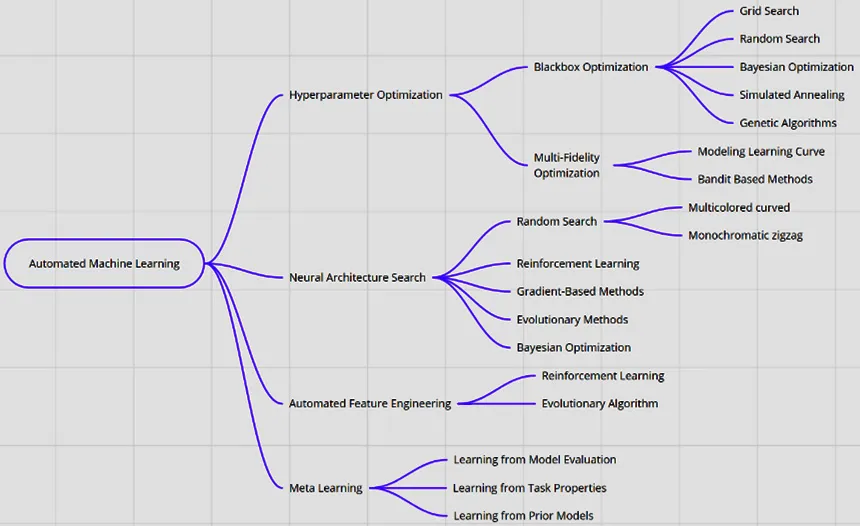
Automated ML is the approach and underlying technology of applying certain automation techniques to accelerate the model's development life cycle. Automated ML enables citizen data scientists and domain experts to train ML models, and helps them build optimal solutions to ML problems. It provides a higher level of abstraction for finding out what the best model is, or an ensemble of models suitable for a specific problem. It assists data scientists by automating the mundane and repetitive tasks of feature engineering, including architecture search and hyperparameter optimization. The following diagram represents the ecosystem of automated ML:
Figure 1.2 – Automated ML ecosystem
These three key areas – feature engineering, architecture search, and hyperparameter optimization – hold the most promise for the democratization of AI and ML. Some automated feature engineering techniques that are finding domain-specific usable features in datasets include expand/reduce, hierarchically organizing transformations, meta learning, and reinforcement learning. For architectural search (also known as neural architecture search), evolutionary algorithms, local search, meta learning, reinforcement learning, transfer learning, network morphism, and continuous optimization are employed.
Last, but not least, we have hyperparameter optimization, which is the art and science of finding the right type of parameters outside the model. A variety of techniques are used here, including Bayesian optimization, evolutionary algorithms, Lipchitz functions, local search, meta learning, particle swarm optimization, random search, and transfer learning, to name a few.
In the next section, we will provide a detailed overview of these three key areas of automated ML. You will see some examples of them, alongside code, in the upcoming chapters. Now, let's discuss how automated ML really works in detail by covering feature engineering, architecture search, and hyperparameter optimization.
How automated ML works
ML techniques work great when it comes to finding patterns in large datasets. Today, we use these techniques for anomaly detection, customer segmentation, customer churn analysis, demand forecasting, predictive maintenance, and pricing optimization, among hundreds of other use cases.
A typical ML life cycle is comprised of data collection, data wrangling, pipeline management, model retraining, an...