Section 1: Introduction to Machine Learning
This section provides details about the AWS Machine Learning Specialty Exam. It also introduces machine learning fundamentals and covers the most important AWS application services for artificial intelligence.
This section contains the following chapters:
- Chapter 1, Machine Learning Fundamentals
- Chapter 2, AWS Application Services for AI/ML
Chapter 1: Machine Learning Fundamentals
For many decades, researchers have been trying to simulate human brain activity through the field known as artificial intelligence, AI for short. In 1956, a group of people met at the Dartmouth Summer Research Project on Artificial Intelligence, an event that is widely accepted as the first group discussion about AI as we know it today. Researchers were trying to prove that many aspects of the learning process could be precisely described and, therefore, automated and replicated by a machine. Today, we know they were right!
Many other terms appeared in this field, such as machine learning (ML) and deep learning (DL). These sub-areas of AI have also been evolving for many decades (granted, nothing here is new to the science). However, with the natural advance of the information society and, more recently, the advent of big data platforms, AI applications have been reborn with much more power and applicability. Power, because now we have more computational resources to simulate and implement them; applicability, because now information is everywhere.
Even more recently, cloud services providers have put AI in the cloud. This is helping all sizes of companies to either reduce their operational costs or even letting them sample AI applications (considering that it could be too costly for a small company to maintain its own data center).
That brings us to the goal of this chapter: being able to describe what the terms AI, ML, and DL mean, as well as understanding all the nuances of an ML pipeline. Avoiding confusion on these terms and knowing what exactly an ML pipeline is will allow you to properly select your services, develop your applications, and master the AWS Machine Learning Specialty exam.
The main topics of this chapter are as follows:
- Comparing AI, ML, and DL
- Classifying supervised, unsupervised, and reinforcement learning
- The CRISP-DM modeling life cycle
- Data splitting
- Modeling expectations
- Introducing ML frameworks
- ML in the cloud
Comparing AI, ML, and DL
AI is a broad field that studies different ways to create systems and machines that will solve problems by simulating human intelligence. There are different levels of sophistication to create these programs and machines, which go from simple, rule-based engines to complex, self-learning systems. AI covers, but is not limited to, the following sub-areas:
- Robotics
- Natural language processing
- Rule-based systems
- ML
The area we are particularly interested in now is ML.
Examining ML
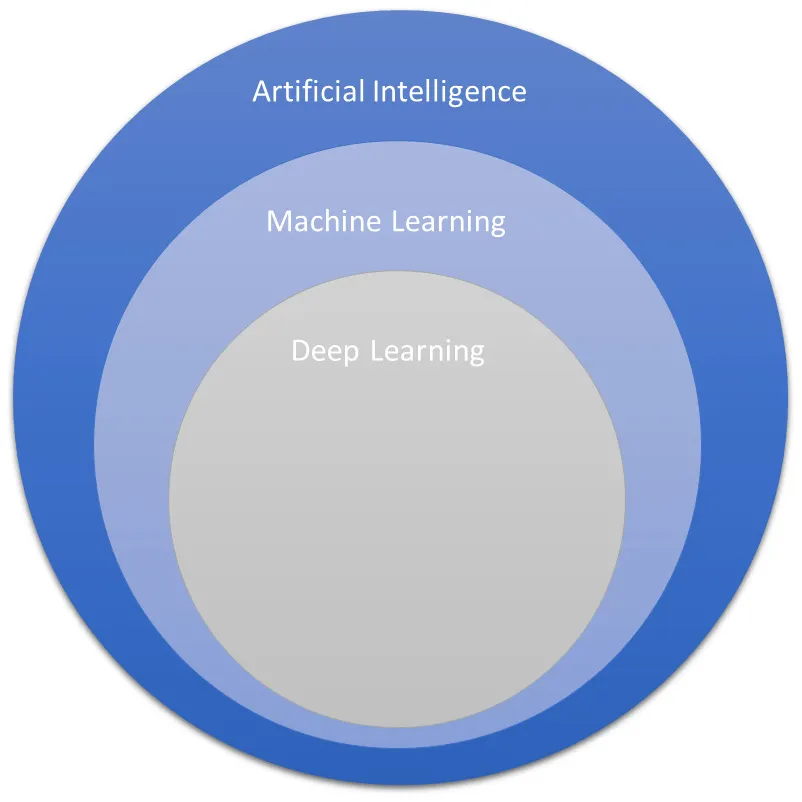
ML is a sub-area of AI that aims to create systems and machines that are able to learn from experience, without being explicitly programmed. As the name suggests, the system is able to observe its running environment, learn, and adapt itself without human intervention. Algorithms behind ML systems usually extract and improve knowledge from the data that is available to them, as well as conditions (such as hyperparameters), and feed back after trying different approaches to solve a particular problem:
Figure 1.1 – Heirarchy of AI, ML, DL
There are different types of ML algorithms; for instance, we can list decision tree-based, probabilistic-based, and neural networks. Each of these classes might have dozens of specific algorithms. Most of them will be covered in later sections of this book.
As you might have noticed in Figure 1.1, we can be even more specific and break the ML field down into another very important topic for the Machine Learning Specialty exam: DL.
Examining DL
DL is a subset of ML that aims to propose algorithms that connect multiple layers to solve a particular problem. The knowledge is then passed through layer by layer until the optimal solution is found. The most common type of DL algorithm is deep neural networks.
At the time of writing this book, DL is a very hot topic in the field of ML. Most of the current state-of-the-art algorithms for machine translation, image captioning, and computer vision were proposed in the past few years and are a part of DL.
Now that we have an overview of types of AI, let's look at some of the ways we can classify ML.
Classifying supervised, unsupervised, and reinforcement learning
ML is a very extensive field of study; that's why it is very important to have a clear definition of its sub-divisions. From a very broad perspective, we can split ML algorithms into two main classes: supervised learning and unsupervised learning.
Introducing supervised learning
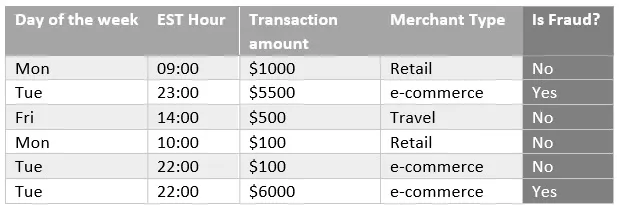
Supervised algorithms use a class or label (from the input data) as support to find and validate the optimal solution. In Figure 1.2, there is a dataset that aims to classify fraudulent transactions from a bank:
Figure 1.2 – Sample dataset for supervised learning
The first four columns are known as features, or independent variables, and they can be used by a supervised algorithm to find fraudulent patterns. For example, by combining those four features (day of the week, EST hour, transaction amount, and merchant type) and six observations (each row is technically one observation), you can infer that e-commerce transactions with a value greater than $5,000 and processed at night are potentially fraudulent cases.
Important note
In a real scenario, we should have more observations in order to have statistical support to make this type of inference.
The key point is that we were able to infer a potential fraudulent pattern just because we knew, a priori, what is fraud and what is not fraud. This information is present in the last column of Figure 1.2 and is commonly referred to as a target variable, label, response variable, or dependent variable. If the input dataset has a target variable, you should be able to apply supervised learning.
In supervised learning, the target variable might store different types of data. For instance, it could be a binary column (yes or no), a multi-class column (class A, B, or C), or even a numerical column (any real number, such as a transaction amount). According to the data type of the target variable, you will find which type of supervised learning your problem refers to. Figure 1.3 shows how to classify supervised learning into two main groups: classification and regression algorithms:
Figure 1.3 – Choosing the right type of supervised learning given the target variable
While classification algorithms predict a class (either binary or multiple classes), regression algorithms predict a real number (either continuous or discrete).
Understanding data types is important to make the right decisions on ML projects. We can split data types into two main categories: numerical and categorical data. Numerical data can then be split into continuous or discrete subclasses, while categorical data might refer to ordinal or nominal data:
- Numerical/discrete data refers to individual and countable items (for example, the number of students in a classroom or the number of items in an online shopping cart).
- Numerical/continuous data refers to an infinite number of possible measurements and they often carry decimal points (for example, temperature).
- Categorical/nominal data refers to labeled variables with no quantitative value (for example, name or gender).
- Categorical/ordinal data adds the sense of order to a labeled variable (for example, education level or employee title level).
In other words, when choosing an algorithm for your project, you should ask yourself:...