This volume is a collation of articles on counter forensics practices and digital investigative methods from the perspective of crime science. The book also shares alternative dialogue on information security techniques used to protect data from unauthorised access and manipulation.
Scandals such as those at OPCW and Gatwick Airport have reinforced the importance of crime science and the need to take proactive measures rather than a wait and see approach currently used by many organisations. This book proposes a new approach in dealing with cybercrime and unsociable behavior involving remote technologies using a combination of evidence-based disciplines in order to enhance cybersecurity and authorised controls. It starts by providing a rationale for combining selected disciplines to enhance cybersecurity by discussing relevant theories and highlighting the features that strengthen privacy when mixed. The essence of a holistic model is brought about by the challenge facing digital forensic professionals within environments where tested investigative practices are unable to provide satisfactory evidence and security. This book will be of interest to students, digital forensic and cyber security practitioners and policy makers. It marks a new route in the study of combined disciplines to tackle cybercrime using digital investigations and crime science.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Through our devices, we are able to record and share content, fomenting the generation of information about what happens around us. An example is a massive blaze that struck Notre Dame Cathedral, in April 2019, during which millions of images and videos were recorded and shared on the Internet by the media at large and everyday citizens. All content is potentially important to document our history and also as a source of information for investigations. However, in this vast pool of information, we do not promptly know how the different items connect to each other to unravel the whole story. This chapter presents how to achieve the X-coherence for an event, i.e., sort an unstructured collection of images and videos, in space and time, allowing the analysis of the corresponding event as a whole. To this end, we present machine learning techniques to automatically position each media piece in space and time, considering the Notre Dame fire as the backdrop. We employ convolutional neural networks to capture visual clues in the Cathedral’s structure and its surroundings and how the scene’s appearance alters as time progresses. Finally, this chapter also presents a comprehensive way of visualizing and exploring the organized data.
1. Introduction
We live in a connected world, where events taking place across the globe often have the power to impact our daily lives. Such events reach us and are broadcasted by us in the form of visual and textual content, generating a massive unstructured pool of data. A paramount example is a recent blaze that struck the Notre-Dame Cathedral, an ancient Parisian architectural and religious symbol. In April 2019, a fire tore through the cathedral, devastating large parts of its structure and spire (Figure 1). People worldwide followed the tragic event through millions of images and videos that were shared by the media and everyday citizens, at the same time that part of the structure turned to dust.
The content generated from unprecedented events, such as the Notre-Dame fire, is potentially important to document our history and also as a source of information for investigations. This content, however, naturally comes from heterogeneous sources, often times lacking proper structure, as to where and when it was captured and how it is connected with other pieces of information. An effective way of understanding an event is to create a structure for this type of data by constructing a unified space where all pieces of related information can be coherently organized.
Figure 1: Notre-Dame Cathedral during a massive blaze that destroyed part of its structure and spire, in April 2019. Credit: Milliped [CC BY-SA 4.0] and Francois Guillot/AFP/Getty.
The process of synchronizing data by positioning its items in a common consistent system is called X-coherence (Ferreira et al. 2019). The idea is that by properly organizing an event’s data, it is possible to navigate through it, understand how it unravels in time and space, and even observe the timeline for a specific person or object within the same context. X-Coherence could aid, for instance, fact-checking and the mining of suspects in forensic investigations.
Although achieving X-coherence for an event is beneficial, performing it manually might be an unfeasible task, given the large volume of data to be processed within a reasonable timeframe. Even worse is the possibility of a person interfering with the process by introducing unconscious bias, consequently invalidating the constructed space and any conclusions drawn from it. One such example is an unprecedented manhunt that followed the Boston Marathon Bombings, in April 2013. After two bombs exploded near the marathon finish line, several people tried to find the bombers by analyzing thousands of images and videos captured at the event, which turned into a major failure (Surowiecki 2013).
A way to overcome these problems is to automate the X-coherence process as much as possible, allowing the effective organization of all data generated from an event, while also mitigating possible biases. To this end, in this chapter, we show how state-of-the-art machine learning techniques can be used to achieve the X-coherence, by automatically sorting an unstructured collection of images, in space and time, while also providing a joint visualization system to understand the event as a whole.
We consider the Notre-Dame fire as the backdrop of our research and, for this, we gathered images and videos of the tragic event from social and mainstream media. For a given subset of annotated imagery from the same event, we train convolution neural networks (CNNs) to capture important visual clues to place each data item in space and time. The trained models can then be used to organize new images as well as placing them in a common coherent space for visualization.
Works in the literature focus on different tasks related to X-coherence. Considering the spatial ordering of images, Snavely et al. 2008 presented an interface to explore unstructured collections of photographs, by computing the viewpoint of each photograph as well as a sparse 3D model of the scene.
For temporal ordering, Schindler et al. 2007 described how to sort a collection of photos spanning many years, by extracting time-varying 3D models. Volokitin et al. 2016 studied the effectiveness of CNN features to predict the time of the year in an outdoor scene. For video sequences, Lameri et al. 2014 proposed a method to splice together sets of near-duplicate shots, thus aligning them temporally, in order to reconstruct a complete video sequence for an event.
Some works focus specifically on how to visualize data from events (Chung et al. 2005; Deligiannidis et al. 2008; Reinders et al. 2001), avoiding information overload and failure to indicate overall trends when analyzing events.
Different from these works, our goal is to explicitly and thoroughly tackle the problem of achieving the X-coherence for an event. For this, our main contributions are:
A method for positioning images of an event in space, assigning them to different cardinal directions in relation to the event center;
A method for placing images of an event to specific timeframes determined by important sub-events;
A visualization approach to coherently represent images of an event in space and time.
Although we demonstrate these contributions on a specific event—the Notre-Dame Cathedral fire, we emphasize that the proposed methods and methodology can be applied to similar events, in which images are captured in different positions and angles around and throughout an event.
2. Proposed Solution
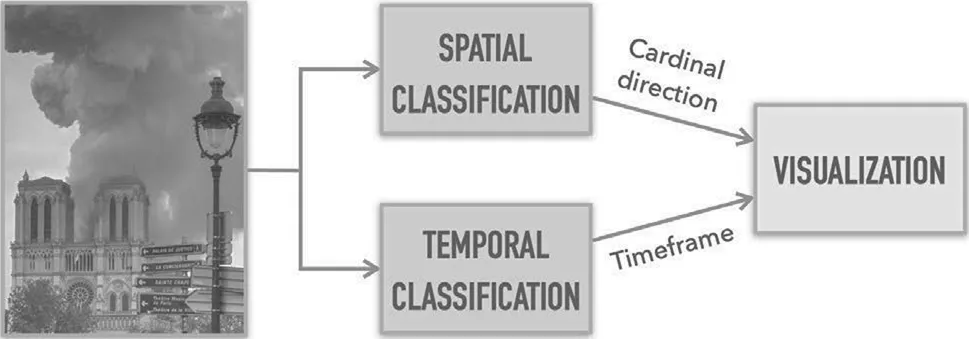
To solve the X-coherence for the Notre-Dame fire event, we divide the process into three steps: spatial classification, temporal classification, and visualization (Figure 2).
In the spatial and temporal classification steps, which can occur simultaneously, the input image is positioned in space and time by the analysis of its content. For spatial classification, a cardinal direction is assigned to the image depending on the location where the image was captured in relation to the cathedral. During temporal classification, our method detects when the image was taken in relation to important sub-events, such as the spire collapsing and the fire being extinguished.
Figure 2:X-coherence solution for the Notre-Dame Fire event. For each available image, the method classifies it regarding its spatial position and temporal order. The spatial classification step assigns a cardinal direction to the image, depending on its position in relation to the cathedral. In temporal classification, the method defines a timeframe for the image with respect to important sub-events.
Finally, the visualization step gathers the previously inferred information for all available images and represents them in a coherent space, allowing a better understanding of the event.
2.1 Spatial Classification
During a critical event, such as the fire that devastated the Notre-Dame Cathedral, people tend to capture images and videos from all possible locations overlooking the event. When this content is uploaded to social media or is made available by the press, metadata (such as time of capture and GPS coordinates) is generally lost. The only way to have this information is by inferring it from the content of the images.
In the spatial classification step, we aim at determining the cardinal direction of the cathedral’s facade—south, southwest, west, northwest, north, northeast, east, or southeast—which was captured in an input image. Depending on the parts of the cathedral that appear on the image, it may not be possible to reliably infer spatial information due to the lack of spatial clues. In order to circumvent this problem, we train our method to classify this kind of input as having an “unknown” direction.
Figure 3a shows, on a map of the event’s location, the possible positions from where an image could have been taken during the event and to which cathedral’s facade each position is associated. Figure 3b depicts some examples of images capturing different facades of the cathedral during the event.
Our solution for this step consists in training a convolutional neural network (CNN) to associate image content (the cathedral’s facade) to a cardinal direction, among the nine possibilities (including the “unknown” class). We rely upon the Inception-ResNetv2 architecture (Szegedy et al. 2017) and its pre-trained weights on the ImageNet dataset. This architecture mixes two state-of-the-art ideas—inception modules and residual connections, which allows a faster training process of much deeper networks, resulting in better results for classification tasks.
Figure 3: Cardinal directions for the spatial classification step: south, southwest, west, northwest, north, northeast, east, or southeast.
To adapt the network to our task, we add a dropout layer to the network output, with a rate of 0.7, in order to regularize the training process, and modify its fully-connected layer to the number of classes of this task. Then, we train the last convolutional layer and the modified fully-connected layer with the training data. It is known that the initial layers of networks optimized for distinct visual tasks learn to i...
Table of contents
Cover
Half Title
Copyright Page
Preface
Acknowledgements
Table of Contents
Part 1: Crime Science
Part 2: Digital Forensics
Part 3: Cyber Security
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Crime Science and Digital Forensics by Anthony C. Ijeh, Kevin Curran, Anthony C. Ijeh,Kevin Curran, Anthony Chukwuemeka Ijeh, Kevin Curran in PDF and/or ePUB format, as well as other popular books in Computer Science & Cyber Security. We have over 1.5 million books available in our catalogue for you to explore.