Data-intensive systems are software applications that process and generate Big Data. Data-intensive systems support the use of large amounts of data strategically and efficiently to provide intelligence. For example, examining industrial sensor data or business process data can enhance production, guide proactive improvements of development processes, or optimize supply chain systems. Designing data-intensive software systems is difficult because distribution of knowledge across stakeholders creates a symmetry of ignorance, because a shared vision of the future requires the development of new knowledge that extends and synthesizes existing knowledge.
Knowledge Management in the Development of Data-Intensive Systems addresses new challenges arising from knowledge management in the development of data-intensive software systems. These challenges concern requirements, architectural design, detailed design, implementation and maintenance. The book covers the current state and future directions of knowledge management in development of data-intensive software systems. The book features both academic and industrial contributions which discuss the role software engineering can play for addressing challenges that confront developing, maintaining and evolving systems;data-intensive software systems of cloud and mobile services; and the scalability requirements they imply. The book features software engineering approaches that can efficiently deal with data-intensive systems as well as applications and use cases benefiting from data-intensive systems.
Providing a comprehensive reference on the notion of data-intensive systems from a technical and non-technical perspective, the book focuses uniquely on software engineering and knowledge management in the design and maintenance of data-intensive systems. The book covers constructing, deploying, and maintaining high quality software products and software engineering in and for dynamic and flexible environments. This book provides a holistic guide for those who need to understand the impact of variability on all aspects of the software life cycle. It leverages practical experience and evidence to look ahead at the challenges faced by organizations in a fast-moving world with increasingly fast-changing customer requirements and expectations.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Data-Intensive Systems, Knowledge Management, and Software Engineering
Bruce R. Maxim
University of Michigan
Matthias Galster
University of Canterbury
Ivan Mistrik
Independent Researcher
Bedir Tekinerdogan
Wageningen University & Research
Contents
1.1 Introduction
1.1.1 Big Data – What It Is and What It Is Not?
1.1.2 Data Science
1.1.3 Data Mining
1.1.4 Machine Learning and Artificial Intelligence
1.2 Data-Intensive Systems
1.2.1 What Makes a System Data-Intensive?
1.2.2 Cloud Computing
1.2.3 Big Data Architecture
1.3 Knowledge Management
1.3.1 Knowledge Identification
1.3.2 Knowledge Creation
1.3.3 Knowledge Acquisition
1.3.4 Knowledge Organization
1.3.5 Knowledge Distribution
1.3.6 Knowledge Application
1.3.7 Knowledge Adaption
1.4 Relating Data-Intensive Systems, Knowledge Management, and Software Engineering
1.4.1 Relating Knowledge Life Cycle to Software Development Life Cycle
1.4.2 Artificial Intelligence and Software Engineering
1.4.3 Knowledge Repositories
1.5 Management of Software Engineering Knowledge
1.5.1 Software Engineering Challenges in a Data-Intensive World
1.5.2 Communication Practices
1.5.3 Engineering Practices
1.6 Knowledge Management in Software Engineering Processes
1.6.1 Requirements Engineering
1.6.2 Architectural Design
1.6.3 Design Implementation
1.6.4 Verification and Validation
1.6.5 Maintenance and Support
1.6.6 Software Evolution
1.7 Development of Data-Intensive Systems
1.7.1 Software Engineering Challenges
1.7.2 Building and Maintaining Data-Intensive Systems
1.7.2.1 Requirements Engineering
1.7.2.2 Architecture and Design
1.7.2.3 Debugging, Evolution, and Deployment
1.7.2.4 Organizational Aspects and Training
1.7.3 Ensuring Software Quality in Data-Intensive Systems
1.7.4 Software Design Principles for Data-Intensive Systems
1.7.5 Data-Intensive System Development Environments
1.8 Outlook and Future Directions
References
1.1 Introduction
Data-intensive computing is a class of parallel computing applications which use a data-parallel approach to process large volumes of data (terabytes or petabytes in size). The advent of big data and data-intensive software systems (DISSs) presents tremendous opportunities (e.g., in science, medicine, health care, finance) for businesses and society. Researchers, practitioners, and entrepreneurs are trying to make the most of the data available to them. However, building data-intensive systems is challenging. Software engineering techniques for building data-intensive systems are emerging. Focusing on knowledge management during software development is one way of enhancing traditional software engineering work practices. Software developers need to be aware that creation of organizational knowledge requires the social construction and sharing of knowledge by individual stakeholders. In this chapter, we explore the application of established software engineering process models and standard practices, enhanced with knowledge management techniques, to develop data-intensive systems.
1.1.1 Big Data – What It Is and What It Is Not?
Big data is concerned with extracting information from several data spanning areas such as science, medicine, health care, engineering, and finance. These data often come from a various sources (Variety) such as social media, sensors, medical records, surveillance, video archives, image libraries, and scientific experiments. Often these data are unstructured and quite large in size (Volume) and require speedy data input/output (Velocity). Big data is often considered to be of high importance (Value), and there is a need to establish trust for its use in decision-making (Veracity). This implies the need for high data quality (Mistrik et al., 2017).
Big data work involves more than simply managing a data set. Indeed, the data sets are often so complex that traditional data processing applications may be inadequate. Reports generated from traditional data warehouses can provide insight to answering questions about what happened in the past. Big data tries to make use of advanced data analytics and a variety of data sources to understand what can happen in the future. An organization may use big data to enrich its understanding of its customers, competitors, and industrial trends. Data alone cannot predict the future. A combination of well-understood data and well-designed analytical models can allow reasonable predictions with carefully defined assumptions. There are many software products, deployment patterns, and alternative solutions that should be considered to ensure a successful outcome for organizations attempting to implement big data solutions (Lopes et al., 2017).
1.1.2 Data Science
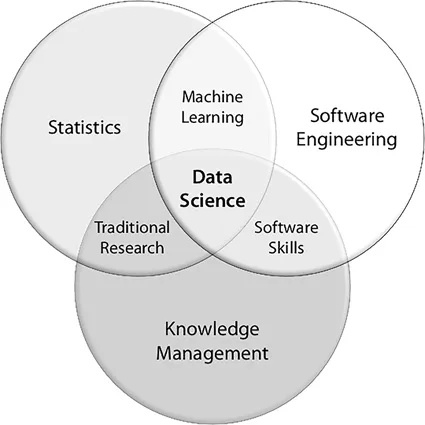
Data science might be thought of as an umbrella term for any data-driven approaches for finding heuristic solutions to difficult problems. Data science incorporates tools from several disciplines to transform data into information, information into knowledge, and knowledge into wisdom. Figure 1.1 shows that data science might be considered as the intersection of three major areas: software engineering, statistics, and knowledge management (Conway, 2010). A data scientist must be interested in more than just the data. Using knowledge of statistics along with domain-specific knowledge helps the data scientist determine whether the particular data and proposed experiments are properly designed for a particular problem. Good software engineering skills are needed to apply these capabilities to other application scenarios (Grosky and Ruas, 2020).
Figure 1.1 Data science Venn diagram.
Many data science projects involve statistical regression techniques or machine learning approaches. A data science project focused on data analytics would consist of the following steps (Grosky and Ruas, 2020):
Data collection: identifying data needed to satisfy the goals of the project
Data cleaning: identifying and repairing problem data elements (e.g., missing or corrupt data)
Data transformation: standardizing data formats to make them suitable for downstream analytic tasks
Data analysis: examining the data to determine the best analytic approach for predictive or inferential purposes
Training set fabrication: generating a good training set that will allow the creation of prediction models capable of generalizing data beyond those used to build the model
These steps would typically be used to establish the training set in a machine learning project or a regression-type study.
1.1.3 Data Mining
Data mining is a form of search that might be defined as the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems (ACM SIGKDD, 2006). Many activities in software engineering can be stated as optimization problems which apply metaheuristic search techniques to software engineering problems. Search-based software engineering is devised on the premise that it is often easier to check a candidate solution that solves a problem than to construct an engineering solution from scratch (Kulkarni, 2013). Lionel Briand (2009) believes that evolutionary and other heuristic search techniques can be easily scaled to industrial-size problems.
Search-based software engineering techniques can be used as the basis for genetic improvement of an existing software product line by grafting on new functional and nonfunctional features (Harman et al., 2014). Successful software products need to evolve continually. However, this evolution must be managed to avoid weakening software quality.
Search-based software engineering techniques (including the use of genetic algorithms) have been used to generate and repair sequences of refactoring recommendations. A dynamic, interactive approach can be used to generate refactoring recommendations to improve software quality while minimizing deviations from the original design (Alizadeh, 2018). Search-based techniques have been used to design test cases in regression testing.
1.1.4 Machine Learning and Artificial Intelligence
Machine learning, like data mining, is an integral part of data science. Creating a data set, as described in Section 1.2, is necessary to drive the machine learning process. In supervised machine learning, the user interacts with the training process either by providing training criteria used as a target or by providing feedback on the quality of the learning exhibited. Unsupervised machine learning is purely data-driven and typically processes the training data until the learning model reaches an equilibrium state, if one exists (Grosky and Ruas, 2020).
Classification problems and regression problems are two broad classes of supervised machine learning tasks addressed by data scientists. In classification problems, the goal is to determine ways to partition the data into two or more categories (e.g., valid vs invalid refactoring operations) and assign numeric values to the likelihood that an unknown data value would be assigned the correct classification by the trained system. In regression problems, the goal is to predict the value of an output variable given the values of several input variables (e.g., trying to predict useful lifetime of a software system based on static quality attributes of its source code). Popular techniques used for supervised learning include linear regression, logistic regression, discriminant analysis, decision trees, and neural networks. Neural networks may also be used for unsupervised learning, along with clustering and dimensional reduction (Grosky and Ruas, 2020).
Neural networks embody the connectionist philosophy of artificial intelligence (AI) developers who believe that an architecture formed by connecting multiple simple processors in a massive parallel environment is one way to duplicate the type of learning that takes place in human being. This view argues that learning takes place by forming connections among related brain cells (processors). Good connections are reinforced during learning and become stronger. Bad connections will become weaker over time, but not completely forgotten.
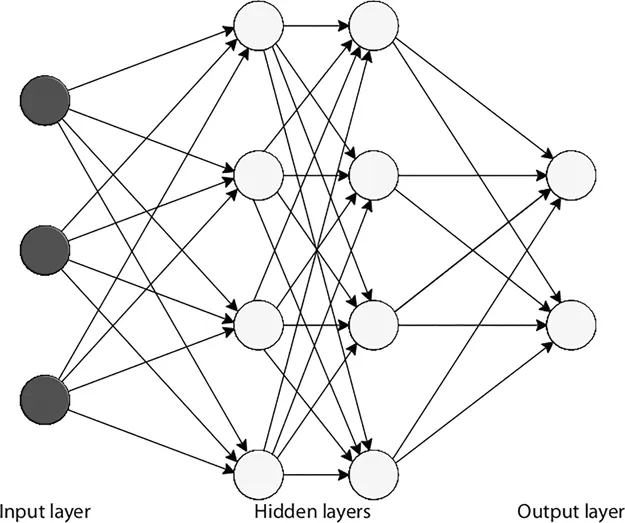
The power of neural networks is that the same network can be used to solve many different problems. The neural network might be thought of as a way of modeling one or more output variables as a nonlinear function; it includes its input variables and may in some cases also include values from hidden layer variables (see Figure 1.2). Specifying a neural network involves using soft links to specify the connectivity among the nodes. The strength of each connection is specified as a numeric value, which is to grow and shrink as the system processes each member of the training set one at a time. In supervised learning, feedback will be provided to help the network adjust its connection values.
Figure 1.2 Neural network with two hidden layers diagram.
The weakness of neural networks is that they cannot explain how or why the connections caused them to make their predictions for the output variable...
Table of contents
Cover
Half Title
Title Page
Copyright Page
Table of Contents
Foreword
Preface
Acknowledgments
Editors
Contributors
1 Data-Intensive Systems, Knowledge Management, and Software Engineering
PART I CONCEPTS AND MODELS
PART II KNOWLEDGE DISCOVERY AND MANAGEMENT
PART III CLOUD SERVICES FOR DATA-INTENSIVE SYSTEMS
PART IV CASE STUDIES
Glossary
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Knowledge Management in the Development of Data-Intensive Systems by Ivan Mistrik, Matthias Galster, Bruce R. Maxim, Bedir Tekinerdogan, Ivan Mistrik,Matthias Galster,Bruce R. Maxim,Bedir Tekinerdogan in PDF and/or ePUB format, as well as other popular books in Computer Science & Information Management. We have over 1.5 million books available in our catalogue for you to explore.