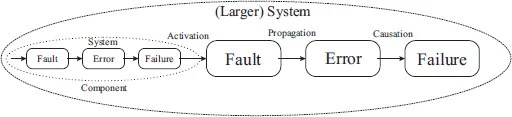
This book covers the most essential techniques for designing and building dependable distributed systems, from traditional fault tolerance to the blockchain technology. Topics include checkpointing and logging, recovery-orientated computing, replication, distributed consensus, Byzantine fault tolerance, as well as blockchain.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.