Solve business problems with data-driven techniques and easy-to-follow Python examples
Key Features
Essential coverage on statistics and data science techniques.
Exposure to Jupyter, PyCharm, and use of GitHub.
Real use-cases, best practices, and smart techniques on the use of data science for data applications.
Description This book begins with an introduction to Data Science followed by the Python concepts. The readers will understand how to interact with various database and Statistics concepts with their Python implementations. You will learn how to import various types of data in Python, which is the first step of the data analysis process. Once you become comfortable with data importing, you will clean the dataset and after that will gain an understanding about various visualization charts. This book focuses on how to apply feature engineering techniques to make your data more valuable to an algorithm. The readers will get to know various Machine Learning Algorithms, concepts, Time Series data, and a few real-world case studies. This book also presents some best practices that will help you to be industry-ready.This book focuses on how to practice data science techniques while learning their concepts using Python and Jupyter. This book is a complete answer to the most common question that how can you get started with Data Science instead of explaining Mathematics and Statistics behind the Machine Learning Algorithms.
What you will learn
Rapid understanding of Python concepts for data science applications.
Understand and practice how to run data analysis with data science techniques and algorithms.
Learn feature engineering, dealing with different datasets, and most trending machine learning algorithms.
Become self-sufficient to perform data science tasks with the best tools and techniques.
Who this book is for This book is for a beginner or an experienced professional who is thinking about a career or a career switch to Data Science. Each chapter contains easy-to-follow Python examples.
Table of Contents 1. Data Science Fundamentals 2. Installing Software and System Setup 3. Lists and Dictionaries 4. Package, Function, and Loop 5. NumPy Foundation 6. Pandas and DataFrame 7. Interacting with Databases 8. Thinking Statistically in Data Science 9. How to Import Data in Python? 10. Cleaning of Imported Data 11. Data Visualization 12. Data Pre-processing 13. Supervised Machine Learning 14. Unsupervised Machine Learning 15. Handling Time-Series Data 16. Time-Series Methods 17. Case Study-1 18. Case Study-2 19. Case Study-3 20. Case Study-4 21. Python Virtual Environment 22. Introduction to An Advanced Algorithm - CatBoost 23. Revision of All Chapters' Learning
About the Author Prateek Gupta is a Data Enthusiast and loves data-driven technologies. Prateek has completed his B.Tech in Computer Science & Engineering and he is currently working as a Data Scientist in an IT company. Prateek has a total 9 years of experience in the software industry, and currently, he is working in the computer vision area. Prateek has implemented various end-to-end Data Science projects for fishing, winery, and ecommerce clients. His implemented object detection and recognition models and product recommendation engines have solved many business problems of various clients. His keen area of interest is in natural language processing and computer vision. In his leisure time, he writes posts about artificial intelligence in his blog. Blog links: http://dsbyprateekg.blogspot.com/ LinkedIn Profile: https://www.linkedin.com/in/prateek-gupta-64203354/
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
“Learning from data is virtually universally useful. Master it and you will be welcomed anywhere.”
– John Elder, founder of the Elder Research
Elder Research is America’s largest and most experienced analytics consultancy. With his vision about data, John started his company in 1995, yet the importance of finding information from the data is a niche and the most demanding skill of the 21st century. Today data science is everywhere.
The explosive growth of the digital world requires professionals with not just strong skills, but also adaptability and a passion for staying on the forefront of technology. A recent study shows that demand for data scientists and analysts is projected to grow by 28 percent by 2021. This is on top of the current market need. According to the U.S. Bureau of Labor Statistics, growth for data science jobs skills will grow about 28% through 2026. Unless something changes, these skill-gaps will continue to widen. In this first chapter, you will learn how to be familiar with data, your role as an aspiring data scientist, and the importance of Python programming language in data science.
Structure
What is data?
What is data science?
What does a data scientist do?
Real-world use cases of data science
Why Python for data science?
Objective
After studying this chapter, you should be able to understand the data types, the amount of the data generated daily, and the need for data scientists with currently available real-world use cases.
What is data?
The best way to describe data is to understand the types of data. Data is divided into the following three categories.
Structured data
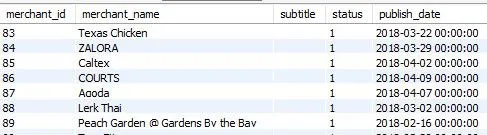
A well-organized data in the form of tables that can be easily be operated is known as structured data. Searching and accessing information from such type of data is very easy. For example, data stored in the relational database, i.e., SQL in the form of tables having multiple rows and columns. The spreadsheet is another good example of structured data. Structured data represent only 5% to 10% of all data present in the world. The following figure 1.1 is an example of SQL data, where an SQL table is holding the merchant related data:
Figure 1.1: Sample SQL Data
Unstructured data
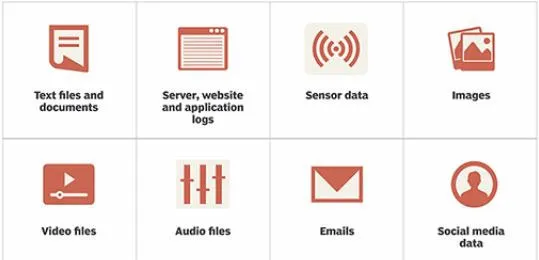
Unstructured data requires advanced tools and software’s to access information. For example, images and graphics, PDF files, word document, audio, video, emails, PowerPoint presentations, webpages and web contents, wikis, streaming data, location coordinates, etc., fall under the unstructured data category. Unstructured data represent around 80% of the data. The following figure 1.2 shows various unstructured data types:
Figure 1.2: Unstructured data types
Semi-structured data
Semi-structured data is structured data that is unorganized. Web data such as JSON (JavaScript Object Notation) files, BibTex files, CSV files, tab-delimited text files, XML, and other markup languages are examples of semi-structured data found on the web. Semi-structured data represent only 5% to 10% of all data present in the world. The following figure 1.3 shows an example of JSON data:
Figure 1.3: JSON data
What is data science?
It’s become a universal truth that modern businesses are awash with data. Last year, McKinsey estimated that Big Data initiatives in the US healthcare system could account for $300 billion to $450 billion in reduced healthcare spending or 12-17 percent of the $2.6 trillion baselines in US healthcare costs. On the other hand though, bad or unstructured data is estimated to be costing the US roughly $3.1 trillion a year.
Data-driven decision making is increasing in popularity. Accessing and finding information from the unstructured data is complex and cannot be done easily with some BI tools; here data science comes into the picture.
Data science is a field that extracts the knowledge and insights from the raw data. To do so, it uses mathematics, statistics, computer science, and programming language knowledge. A person who has all these skills is known as a data scientist. A data scientist is all about being curious, self-driven, and passionate about finding answers. The following figure 1.4 shows the skills that a modern data scientist should have:
Figure 1.4: Skills of a modern data scientist
What does a data scientist do?
Most data scientists in the industry have advanced training in statistics, math, and computer science. Their experience is a vast horizon that also extends to data visualization, data mining, and information management. The primary job of a data scientist is to ask the right question. It’s about surfacing hidden insight that can help enable companies to make smarter business decisions.
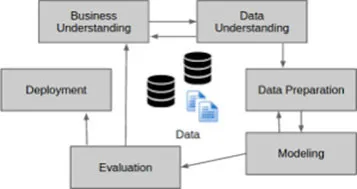
The job of a data scientist is not bound to a particular domain. Apart from scientific research, they are working in various domains including shipping, healthcare, e-commerce, aviation, finance, education, etc. They start their work by understanding the business problem and then they proceed with data collection, reading the data, transforming the data in the required format, visualizing, modeling, and evaluating the model and then deployment. You can imagine their work cycle as mentioned in the following figure 1.5:
Figure 1.5: Work cycle of a data scientist
Eighty percent of a data scientist’s time is spent in simply finding, cleansing, and organizing data, leaving only 20 percent to perform analysis. These processes can be time-consuming and tedious. But it’s crucial to get them right since a model is only as good as the data that is used to build it. And because models generally improve as they are exposed to increasing amounts of data, it’s in the data scientists’ interests to include as much data as they can in their analysis.
In the later chapters of this book, you will learn all the above-required skills to be a data scientist.
Real-world use cases of data science
Information is the oil of the 21st century, and analytics is the combustion engine. Whether you are uploading a picture on Facebook, posting a tweet, emailing anybody, or shopping in an e-commerce site, the role of data science is everywhere. In the modern workplace, data science is applied to many problems to predict and calculate outcomes that would have taken several times more human hours to process. Following are some list of real-world examples where data scientists are playing a key role:
Google’s AI research arm is taking the help of data scientists to build the best performing algorithm for automatically detecting objects.
Amazon has built a product recommendation system to personalize their product.
Santander Group of Bank has built a model with the help of data scientists to identify the value of transactions for each potential customer.
Airbus in the maritime industry is taking the help of data scientists to build a model that detects all ships in satellite images as quickly as possible to increase knowledge, anticipate threats, trigger alerts, and improve efficiency at sea.
YouTube is using an automated video classification model in limited memory.
Data scientists at the Chinese internet giant Baidu Inc. released details of a new deep learning algorithm that they claim can help pathologists identify tumors more accurately.
The Radiological Society of North America (RSNA®) is using an algorithm to detect a visual signal for pneumonia in medical images which automatically locate lung opacities on chest radiographs.
The Inter-American Development Bank is using an algorithm that considers a family’s observable household attributes like the material of their walls and ceiling, or the assets found in the home to classify them and predict their level of need.
Netflix data uses data science skills on the movie viewing patterns to understand what drives user interest and uses that to make decisions on which Netflix original series to produce.
Why Python for data science?
Python is very beginner friendly. The syntax (words and structure) is extremely simple to read and follow, most of which can be understood even if you do not know any programming. Python is a multi-paradigm programming language – a sort of Swiss Army knife for the coding world. It supports object-oriented programming, structured programming, and functional programming patterns, among others. There’s a joke in the Python community that Python is generally the second-best language for everything.
Python is a free, open-source software, and consequently, anyone can write a library package to extend its functionality. Data science has been an early beneficiary of these extensions, particularly Pandas, the big daddy of them all.
Python’s inherent readability and simplicity makes it relatively easy to pick up, and the number of dedicated analytical libraries available today means that data scientists in almost every sector will find packages already tailored...
Table of contents
Cover Page
Title Page
Copyright Page
Dedication Page
About the Author
Acknowledgement
Preface
Errata
Table of Contents
1. Data Science Fundamentals
2. Installing Software and System Setup
3. Lists and Dictionaries
4. Package, Function, and Loop
5. NumPy Foundation
6. Pandas and DataFrame
7. Interacting with Databases
8. Thinking Statistically in Data Science
9. How to Import Data in Python?
10. Cleaning of Imported Data
11. Data Visualization
12. Data Pre-processing
13. Supervised Machine Learning
14. Unsupervised Machine Learning
15. Handling Time-Series Data
16. Time-Series Methods
17. Case Study-1
18. Case Study-2
19. Case Study-3
20. Case Study-4
21. Python Virtual Environment
22. Introduction to An Advanced Algorithm - CatBoost
23. Revision of All Chapters’ Learning
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Practical Data Science with Jupyter by Prateek Gupta in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Processing. We have over 1.5 million books available in our catalogue for you to explore.