What Is a Data Lake?
Ask a friend this question: “What’s a lake?” Your friend thinks for a moment, and then gives you this answer: “Well, it’s a big hole in the ground that’s filled with water.”
Technically, your friend is correct, but that answer also is far from detailed enough to really tell you what a lake actually is. You need more specifics, such as:
- How big, dimension-wise (how long and how wide)
- How deep that “big hole in the ground” goes
- How much variability there is from one lake to another in terms of those length, width, and depth dimensions (the Great Lakes, anyone?)
- How much water you’ll find in the lake and how much that amount of water may vary among different lakes
- Whether a lake contains freshwater or saltwater
Some follow-up questions may pop into your mind as well:
- A pond is also a big hole in the ground that’s filled with water, so is a lake the same as a pond?
- What distinguishes a lake from an ocean or a sea?
- Can a lake be physically connected to another lake?
- Can the dividing line between two states or two countries be in the middle of a lake?
- If a lake is empty, is it still considered a lake?
- If one lake leaves Chicago, heading east and travels at 100 miles per hour, and another lake heads west from New York … oh wait, wrong kind of word problem, never mind… .
So many missing pieces of the puzzle, all arising from one simple question!
You’ll find the exact same situation if you ask someone this question: “What’s a data lake?” In fact, go ahead and ask your favorite search engine that question. You’ll find dozens of high-level definitions that will almost certainly spur plenty of follow-up questions as you try to get your arms around the idea of a data lake.
Here’s a better idea: Instead of filtering through all that varying — and even conflicting — terminology and then trying to consolidate all of it into a single comprehensive definition, just think of a data lake as the following:
A solidly architected, logically centralized, highly scalable environment filled with different types of analytic data that are sourced from both inside and outside your enterprise with varying latency, and which will be the primary go-to destination for your organization’s data-driven insights
Wow, that’s a mouthful! No worries: Just as if you were eating a gourmet fireside meal while camping at your favorite lake, you can break up that definition into bite-size pieces.
Rock-solid water
A data lake should remain viable and useful for a long time after it becomes operational. Also, you’ll be continually expanding and enhancing your data lake with new types and forms of data, new underlying technologies, and support for new analytical uses.
Building a data lake is more than just loading massive amounts of data into some storage location.
To support this near-constant expansion and growth, you need to ensure that your data lake is well architected and solidly engineered, which means that the data lake
- Enforces standards and best practices for data ingestion, data storage, data transmission, and interchange among its components and data delivery to end users
- Minimizes workarounds and temporary interfaces that have a tendency to stick around longer than planned and weaken your overall environment
- Continues to meet your predetermined metrics and thresholds for overall technical performance, such as data loading and interchange, as well as user response time
Think about a resort that builds docks, a couple of lakeside restaurants, and other structures at various locations alongside a large lake. You wouldn’t just hand out lumber, hammers, and nails to a bunch of visitors and tell them to start building without detailed blueprints and engineering diagrams. The same is true with a data lake. From the first piece of data that arrives, you need as solid a foundation as possible to help keep your data lake viable for a long time.
A really great lake
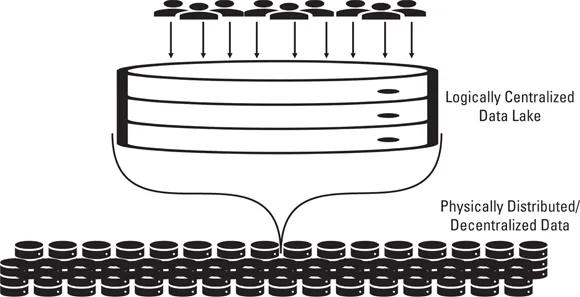
You’ll come across definitions and descriptions that tell you a data lake is a centralized store of data, but that definition is only partially correct.
A data lake is logically centralized. You can certainly think of a data lake as a single place for your data, instead of having your data scattered among different databases. But in reality, even though your data lake is logically centralized, its data is physically decentralized and distributed among many different underlying servers.
The data services that you use for your data lake, such as the Amazon Simple Storage Service (S3), the Microsoft Azure Data Lake Storage (ADLS), or the Hadoop Distributed File System (HDFS) manage the distribution of data among potentially numerous servers where your data is actually stored. These services hide the physical distribution from almost everyone other than those who need to manage the data at the server storage level. Instead, they present the data as being logically part of a single data lake.
Figure 1-1 illustrates how logical centralization accompanies physical decentralization.
Expanding the data lake
How big can your data lake get? To quote the old saying (and to answer a question with a question), how many angels can dance on the head of a pin?
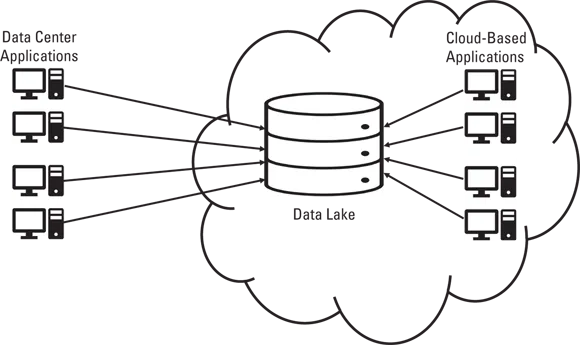
Scalability is best thought of as “the ability to expand capacity, workload, and missions without having to go back to the drawing board and start all over.” Your data lake will almost always be a cloud-based solution (see Figure 1-2). Cloud-based platforms give you, in theory, infinite scalability for your data lake. New servers and storage devices (discs, solid state devices, and so on) can be incorporated into your data lake on demand, and the software services manage and control these new resources along with those that you’re already using. Your data lake contents can then expand from hundreds of terabytes to petabytes, and then to exabytes, and then zettabytes, and even into the ginormousbyte range. (Just kidding about that last one.)
Cloud providers give you pricing for data storage and access that increases as your needs grow or decreases if you cut back on your functionality. Basically, your data lake will be priced on a pay-as-you-go basis.
Some of the very first data lakes that were built in the Hadoop environment may reside in your corporate data center and be categorized as on-prem (short for on-premises, meaning “on your premises”) solutions. But most of today’s data lakes are built in the Amazon Web Services (AWS) or Microsoft Azure cloud environments. Given the ever-increasing popularity of cloud computing, it’s highly unlikely that this trend of cloud-based data lakes will reverse for a long time, if ever.
As long as Amazon, Microsoft, and other cloud platform providers can keep expanding their existing data centers and building new ones, as well as enhancing the capabilities of their data management services, then your data lake should be able to...