The 2nd International Conference on Artificial Intelligence and Speech Technology (AIST2020) was organized by Indira Gandhi Delhi Technical University for Women, Delhi, India on November 19–20, 2020. AIST2020 is dedicated to cutting-edge research that addresses the scientific needs of academic researchers and industrial professionals to explore new horizons of knowledge related to Artificial Intelligence and Speech Technologies. AIST2020 includes high-quality paper presentation sessions revealing the latest research findings, and engaging participant discussions. The main focus is on novel contributions which would open new opportunities for providing better and low-cost solutions for the betterment of society. These include the use of new AI-based approaches like Deep Learning, CNN, RNN, GAN, and others in various Speech related issues like speech synthesis, speech recognition, etc.

eBook - ePub
Artificial Intelligence and Speech Technology
Proceedings of the 2nd International Conference on Artificial Intelligence and Speech Technology, (AIST2020), 19-20 November, 2020, Delhi, India
- 505 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Artificial Intelligence and Speech Technology
Proceedings of the 2nd International Conference on Artificial Intelligence and Speech Technology, (AIST2020), 19-20 November, 2020, Delhi, India
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
CHAPTER 1
Classification approaches for automatic speech recognition system
Amritpreet Kaura, Rohit Sachdevab, Amitoj Singhc
a,bM.M. Modi College, Patiala cMRS PTU, Bathinda
Abstract: Recognition of Speech is now becoming more widespread. Different applications that are knowledgeable of interactive expression are present on the market. For those devices in which handwriting is complicated, speaking recognition systems are sensible options. With growing specifications for embedded devices and modern embedded technologies, the Speech Recognition Systems (SRS) must also be available. Mainly the latest expressions use Hidden Markov Models (HMMs) methods to decide how well every condition of each HMM fit in with a picture or effective allocation of coefficient frames that reflect acoustical inputs, to interact with the spatial uncertainty of language and Gaussian Mixture Models (GMMs). Alternatively, the use of a neural feed method that uses many structures of coefficients as inputs and creates later chances as output in relation to HMM states. Deep Neural Networks (DNN) with many input layer which are equipped with modern techniques have already shown that GMMs are more successful on a range of voice recognition criteria, with many input nodes. DNNs have been equipped with new techniques to surpass GMMs on a number of speech recognition criteria, often by a significant margin. This study offers an analysis of development and reflects the common perspectives of four study groups who have recently found excellence in the use of deep neural networks in speech recognition for acoustic modeling.
Keywords: DNN, GMM, HMM, RASTA
1.1 Introduction
The only way in which humans can exchange their information with each other is speech (Allen, 1995). Speech processing is one of the methods to provide this interaction between human and machine. Speech Recognition (or) more popularly known as Automatic Speech Recognition (ASR) has gained lots of popularity since last few years (Abdel-Hamid et al., 2014; Amodei et al., 2016; O’Shaughnessy, 2008). Acknowledgment of expression is a part of deep learning with computers that aid human beings to interact more easily and closely to the machines. Speech Recognition has become an essential part of every application whether it’s your smartphone to a well-established web application. The voice search feature is now gaining great popularity nowadays. Voice recognition has been included by everyone as the important part of their lives. Speech has arisen as one of the simplest modes for man to machine and machine to man interaction thanks to recent research in technology (Cyran, Kozielski, Peters, Stanczyk, & Wakulicz-Deja, 2009).
1.2 Methods
There are different ways to perform the speech recognition functions. Notable research has been done to make a zero-loss information speech system.
- A leading encoding strategy was used in the mathematical context for HMM. This is an inter-related method, generated by two processes, a Markov chain which is rooted in a limited variety of states, and a particular function of probabilities is correlated with each of these states, to determine the odds of the acoustic properties. State probabilities can be modeled through continuous likelihood function, semi-continuous production of probability, or constant production of probability. Mixture distributions consisting of a linear combination of Gaussian or Laplacian density functions are the typical models for the constant probability distribution.
- ANN is a computer device driven by the arrangement of cell types in the living person’s mind. The most commonly used category of ANN in speech recognition (Masmoudi, Frikha, Chtourou & Hamida 2011) is Multi-Layer Perceptron (MLP). A potential substitute to substitute or assist HMM in classification style was digital NN & and more precisely MLP. Some ANN methods to develop state-of-the-art ASR structures were suggested (Fauziya & Nijhawan, 2014; Renjith & Manju, 2017).
- Deep learning methods are proposed as an advancement of ANN in order to get significant improvement in the performance of the acoustic models. Restricted Boltzmann machine, Deep Belief Networks (DBN) (A.-R. Mohamed, Dahl, & Hinton, 2009; A. R. Mohamed, Dahl, & Hinton, 2012), Deep Neural Networks (DNN) (Hinton et al., 2012; Senior, Heigold, Bacchiani, & Liao, 2014), Convolutional Neural Networks (CNN) (Abdel-Hamid et al., 2014; Passricha & Aggarwal, 2019a), Capsule Network are popular variants of deep learning technique that is successfully adopted speech recognition tasks. Evolutionary Techniques search approaches focused on the theory of natural evolution are adaptive methods such as Genetic Algorithms (GAs), Particle Swarm Optimization (PSO), etc. These strategies have the potential to produce a simple community of potential responses and a really strong capacity to identify the best approaches of all those reasonable solutions (Dua, Aggarwal, & Biswas, 2018; Passricha & Aggarwal, 2019b).
1.3 Architecture of Speech Recognition
The architecture of ASR system which has two main components is broadly divided into 5 components as shown in Figure 1.1.
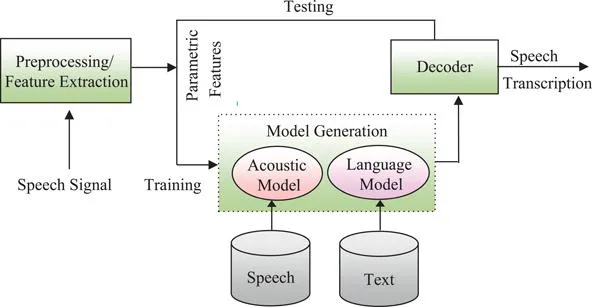
1.3.1 Preprocessing and Feature Extraction
The key aim of extraction is to project the speech signal in a compact parameter space by merely extracting data associated with spoken language. Certain standard techniques of extraction are:
1.3.1.1 LPC: A sufficient number of past samples will estimate the speaking sample. LPC is determined to reduce predictive error. The human pronunciation vessels are represented by signal detection techniques during this procedure.
1.3.1.2 MFCC: The voice signal first is evaluated in the form of STFT and then the DFT principles are integrated into essential groups and weighed by triangular measurement method. This approach is based on the auditory function of humans. PLP: In PLP, the LPC and MFCC characteristics are combined to achieve improved performance. Instead of trapezoidal filters, the triangular philter has been used here (Hermansky, 1990).
Along with above mentioned techniques number of the other techniques like RASTA, PLDA, LPCC etc. are modeled by signal processing techniques (Hermansky & Morgan, 1994; Makhoul, 1975).
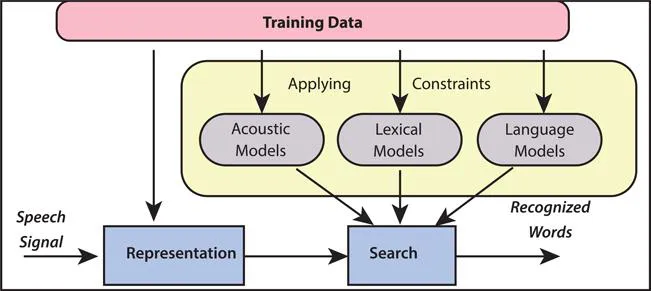
1.4 Models of Speech Recognition
There are different types of models that are needed for Automatic Speech Recognition. Figure 1.2 shows the major speech recognition components. The models are mentioned as below:
1.4.1 Acoustic Modeling: To recognize an unknown utterance, the extracted features have to be compared with some reference models. This reference model is called acoustic model. The acoustic model processes the feature vectors either directly or by using a phoneme-based model are the two categories of the acoustic model (Hinton et al., 2012).
1.4.2 Pronunciation Modeling: The pronunciation model or lexicon model grants the explanation of lexicons in phrase of basic sub-lexicon components (phoneme) that are present in system vocabulary. It is developed to impart the accent of each word available in the vocabulary. A pronunciation model in an ASR system is used to provide the mapping between the vocabulary and the training model. Different phone combinations are used to represent the word in the lexicon model. The Lexicon model typically uses normal expression in a normal dictionary (Liu & Fung, 2004).
1.4.3 Language Modeling: The importance of the language model for ASR systems can be understood from the fact that many of the state-of-the-art speech recognition applications would have been impossible to implement without an effective language model and constrained grammars (Chen, Liu, Gales, & Woodland, 2015; Jozefowicz, Vinyals, Schuster, Shazeer, & Wu, 2016).
1.5 Comparative Analysis of SR Models
After going through the vast literature available till yet in the field of speech recognition different techniques were studied. The table given below highlights these techniques along with their advantages and disadvantages.
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- Organisation
- Preface
- 1 Classification approaches for automatic speech recognition system
- 2 Early detection of PCOD using machine learning techniques
- 3 Application of real-time object detection techniques for bird detection
- 4 Machine learning algorithms used for detection of prostate cancer
- 5 How training of sigmoidal FFANN affected by weight initialization
- 6 Machine learning for web development: A fusion
- 7 Bot attack detection using various machine learning algorithms
- 8 Present scenario of emotionally intelligent voice-based Conversational Agents in India
- 9 Blockchain-based secured data transmission of IoT sensors using thingspeak
- 10 Impact of energy storage device on the performance of AGC using ALO tuned PID controller
- 11 The instrument to measure happiness at workplace
- 12 IoT based smart cyber sealing system
- 13 A novel approach for summarizing legal judgements using graph
- 14 Deep CNN architectures for learning image classification: A systematic review, taxonomy and open challenges
- 15 The quest for crop improvement in the era of artificial intelligence, machine learning, and other cognitive sciences
- 16 A run-through: Text independent speaker identification using deep learning
- 17 Summarization of video lectures
- 18 Artificial intelligence approach in video summarization
- 19 Extractive summarization of recorded Odia spoken feedback
- 20 Frame change detection in videos – challenges and research directions
- 21 Speech impairment recognition using XGBoost classifier
- 22 Research insight of Indian tonal languages: A review
- 23 Advances in speech vocoding for text-to-speech with continuous parameters
- 24 Applying entity recognition and verb role labelling for information extraction of Tamil biomedicine
- 25 Identification of two tribal languages of India: An experimental study
- 26 Mental illness diagnosis from social network data using effective machine learning technique
- 27 Hybrid classifier for brain tumor detection and classification
- 28 Parametric study of through transmission laser welding with teaching learning based optimization
- 29 Research landscape of artificial intelligence in human resource management: A bibliometric overview
- 30 An efficient Class-F PA with SSL/SIL based matching network for body centric wireless transceiver
- 31 Envisaging the future homes with ‘human-building interaction’
- 32 Comparative analysis of first-order optimization algorithms
- 33 A review on application of artificial intelligence techniques in control of industrial processes
- 34 Crop monitoring system for effective prediction of agricultural analytics in Indian agriculture using WSN
- 35 Trend analysis of meteorological index SPI using statistical and machine learning models over the region of Marathwada
- 36 An insight into reconfigurable antenna design
- 37 Optimized XGBoost algorithm using agglomerative clustering for effective user context identification
- 38 1D CNN based approach for speech emotion recognition using MFCC features
- 39 Review on text detection and recognition in images
- 40 Comparative analysis of machine learning algorithms on gender classification using Hindi speech data
- 41 COVID-19 detection through Mamdani-based fuzzy inference system
- 42 Assistive technology is a boon or bane: A case of persons with disabilities
- 43 Sensor data fusion using machine learning techniques in indoor occupancy detection
- 44 Covid’19 virus life progress span by using machine learning algorithms and time series methods
- 45 Sustainable development through adoption of digitization towards functioning of self help groups
- 46 Security and vulnerability issues in NoSQL
- 47 Artificial intelligence applications and techniques in interactive and adaptive smart learning environments
- 48 SIM-BERT: Speech intelligence model using NLP-BERT with improved accuracy
- 49 A literature review on virtual assistant for visually impaired
- 50 Congestion control mechanisms to avoid congestion in VANET: A comparative review
- 51 Comparative Study of various Stable and Unstable sorting Algorithms
- 52 Prediction analysis of forecasting applications with concept drifting distributions
- 53 A hybrid cardiovascular disease prediction system using machine learning algorithms
- 54 Financial inclusion via Fintech: A conceptual framework for digitalizing the banking landscape of rural India
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Artificial Intelligence and Speech Technology by Amita Dev, Arun Sharma, S.S. Agrawal, Amita Dev,Arun Sharma,S.S. Agarwal,S.S. Agrawal, Amita Dev, Arun Sharma, S.S. Agarwal in PDF and/or ePUB format, as well as other popular books in Computer Science & Artificial Intelligence (AI) & Semantics. We have over 1.5 million books available in our catalogue for you to explore.