Amazon Redshift: A Columnar Database SQL and Architecture illuminates the brilliance behind Amazon's Redshift technology. It is over 600 pages long, and it shows users how to set it up, tune it, load and go. This book also contains all of the SQL you need to query it with ease. After reading this book, you will know why more and more companies are using Redshift as part of their overall data warehouse strategy.

- 619 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Amazon Redshift: A Columnar Database SQL and Architecture
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
Data WarehousingIndex
Computer ScienceChapter 1 - What is Columnar?
“When you go into court you, are putting your fate into the hands of twelve people who weren’t smart enough to get out of jury duty.”
- Norm Crosby
What is Parallel Processing?
"After enlightenment, the laundry"
-Zen Proverb
"After parallel processing the laundry, enlightenment!"
-Redshift Zen Proverb
Two guys were having fun on a Saturday night when one said, “I’ve got to go and do my laundry.” The other said, "What!?" The first man explained that if he went to the laundry mat the next morning, he would be lucky to get one machine and be there all day. But if he went on Saturday night, he could get all the machines. Then, he could do all his wash and dry in two hours. Now that's parallel processing mixed in with a little dry humor!
The Basics of a Single Computer
“When you are courting a nice girl, an hour seems like a second. When you sit on a red-hot cinder, a second seems like an hour. That’s relativity.”
–Albert Einstein
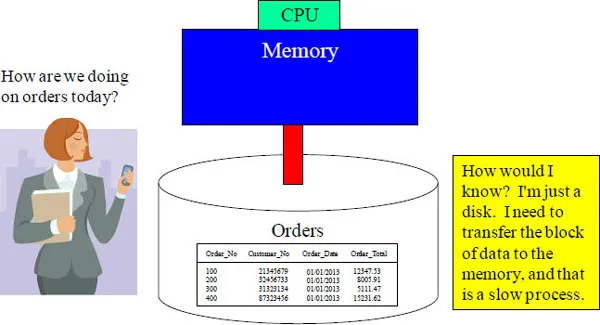
Data on disk does absolutely nothing. When data is requested, the computer moves the data one block at a time from disk into memory. Once the data is in memory, it is processed by the CPU at lightning speed. All computers work this way. The "Achilles Heel" of every computer is the slow process of moving data from disk to memory. The real theory of relativity is find out how to get blocks of data from the disk into memory faster!
Data in Memory is Fast as Lightning
“You can observe a lot by watching.”
–Yogi Berra
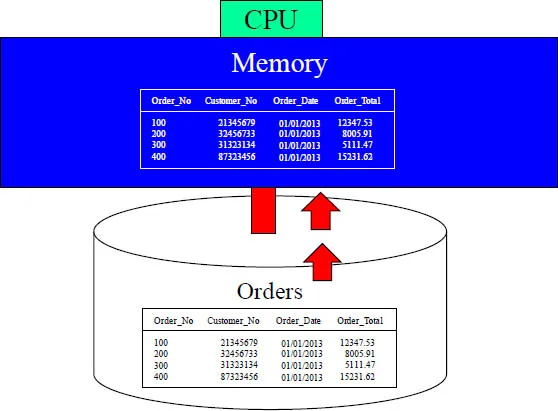
Once the data block is moved off of the disk and into memory, the processing of that block happens as fast as lightning. It is the movement of the block from disk into memory that slows down every computer. Data being processed in memory is so fast that even Yogi Berra couldn't catch it!
Parallel Processing Of Data
"If the facts don't fit the theory, change the facts."
-Albert Einstein
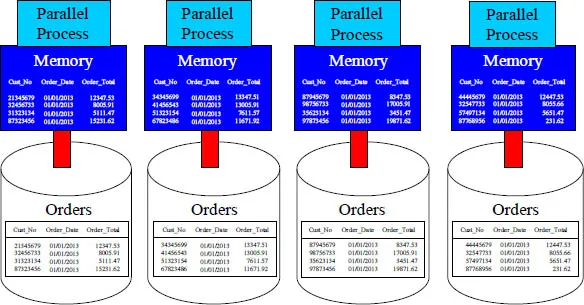
Big Data is all about parallel processing. Parallel processing is all about taking the rows of a table and spreading them among many parallel processing units. Above, we can see a table called Orders. There are 16 rows in the table. Each parallel processor holds four rows. Now they can process the data in parallel and be four times as fast. What Albert Einstein meant to say was, “If the theory doesn't fit the dimension table, change it to a fact."
A Table has Columns and Rows
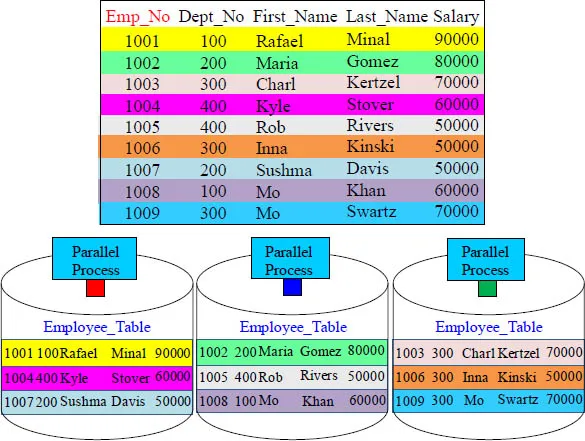
The table above has 9 rows. Our small system above has three parallel processing units. Each unit holds three rows.
Each Parallel Process Organizes the Rows inside a Data Block
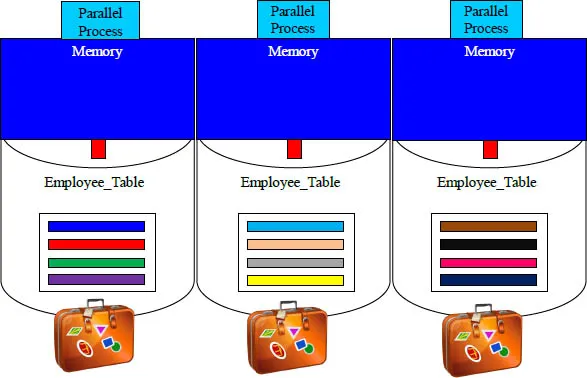
The rows of a table are stored on disk in a data block. Above, you can see we have four rows in each data block. Think of the data block as a suitcase you might take to the airport (without the $50 fee).
Moving Data Blocks is Like Checking In Luggage
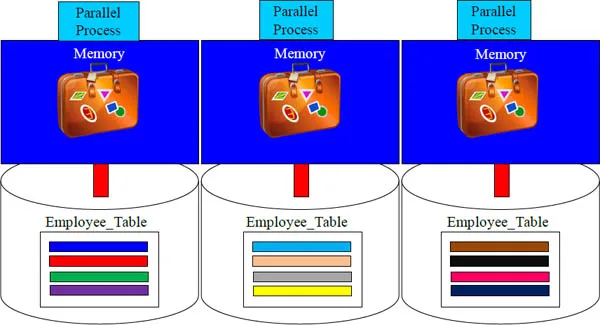
Please put your data block on the scale (inside memory)
To a computer, the data block on disk is as heavy as a large suitcase. It is difficult and cumbersome to lift.
Facts That Are Disturbing
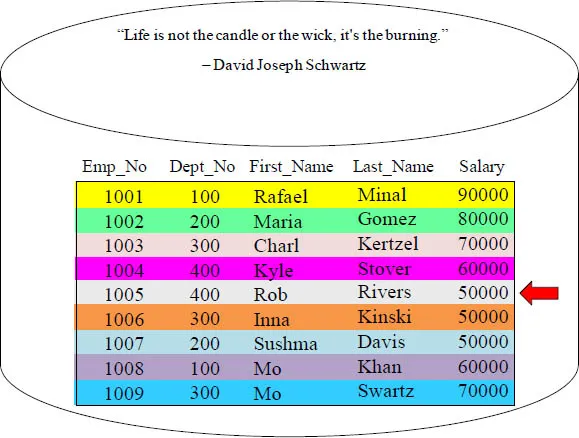
The data block above has 9 rows and five columns. If someone requested to see Rob Rivers’ salary, the entire data block would still have to move into memory. Then, a salary of 50000 would be returned. That is a lot of heavy lifting just to analyze one row and return one column. It is just like burning an entire candle just because you need a flicker of light!
Why Columnar?
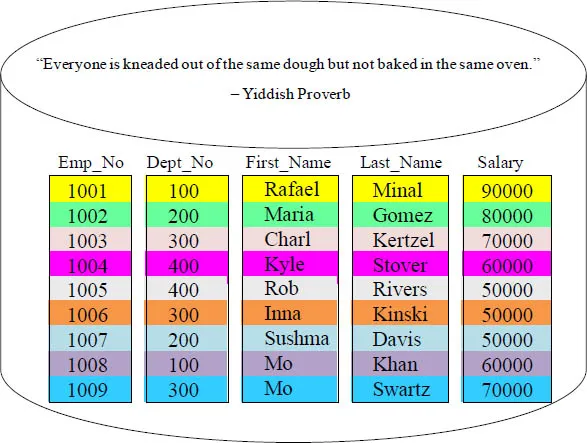
Each data block holds a single column. The row can be rebuilt because everything is aligned perfectly. If someone runs a query that would return the average salary, then only one small data block is moved into memory. The salary block moves into memory where it is processed as fast as lightning. We just cut down on moving large blocks by 80%! Why columnar? Because like our Yiddish Proverb says, "All data is not kneaded on every query, so that is why it costs so much dough."
Row Based Blocks vs. Columnar Based Blocks

Both designs have the same amount of data. Both take up just as much space. In this example, both have 9 rows and five columns. If a query needs to analyze all of the rows or return most of the columns, then the row based design is faster and more efficient. However, if the query only needs to analyze a few rows or merely a few columns, then the columnar design is much lighter because not all of the data is moved into memory. Just one or two columns move. Take the road less traveled.
As Row-Based Tables Get Bigger, the Blocks Split
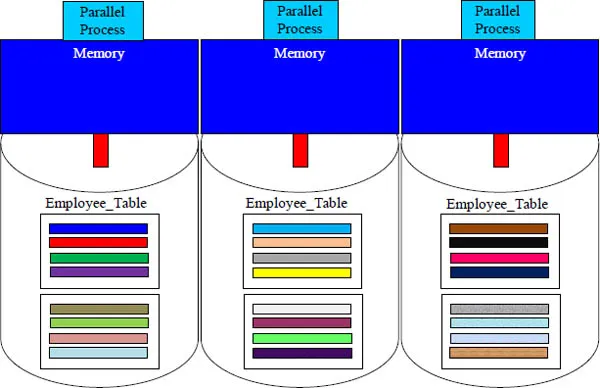
When you go on vacation for two-weeks, you might pack a lot of clothes. It is then that you take two suitcases. A data block can only get so big before it is forced to split, otherwise it might not fit into memory.
Data Blocks Are Processed One at a Time Per Unit
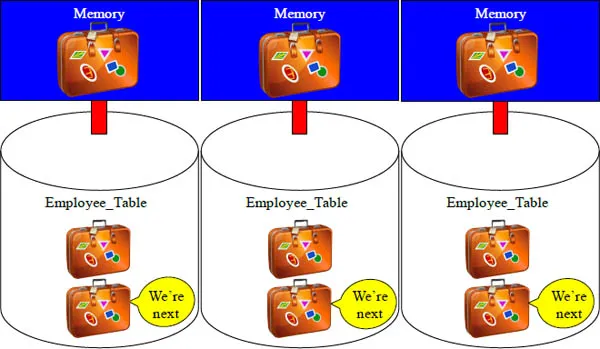
At th...
Table of contents
- Cover
- The Tera-Tom Genius Series
- Tera-Tom- Author of over 50 Books
- The Best Query Tool Works on all Systems
- Copyright
- About Tom Coffing
- About Dave Cook
- Contents
- Chapter 1 - What is Columnar?
- Chapter 2 - Best Practices For Table Design
- Chapter 3 – System Tables
- Chapter 4 - Compression
- Chapter 5 – Temporary Tables
- Chapter 6 - Explain
- Chapter 7 – Basic SQL Functions
- Chapter 8 - The WHERE Clause
- Chapter 9 - Distinct Vs Group By AND TOP
- Chapter 10 - Aggregation
- Chapter 11 - Join Functions
- Chapter 12 - Date Functions
- Chapter 13 - OLAP Functions
- Chapter 14 - Temporary Tables
- Chapter 15 - Sub-query Functions
- Chapter 16 - Substrings and Positioning Functions
- Chapter 17 – Interrogating the Data
- Chapter 18 - View Functions
- Chapter 19 - Set Operators Functions
- Chapter 20 – Statistical Aggregate Functions
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Amazon Redshift: A Columnar Database SQL and Architecture by Tom Coffing,David Cook in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Warehousing. We have over 1.5 million books available in our catalogue for you to explore.