Hadoop is one of the most exciting technologies to ever emerge and is transforming the computer industry. Although Hadoop is designed to process MapReduce queries, it has evolved into accepting SQL, and then converts that SQL to MapReduce. This has opened the door for millions of customers who want to take advantage of their SQL knowledge to query Hadoop systems. Tera-Tom Genius Series - Hadoop Architecture and SQL, written by Tom Coffing and Jason Nolander, details the architecture of Hadoop and the SQL commands available. This book is perfect for anyone who wants to query Hadoop with SQL. It educates readers on how to create tables, how the data is distributed, and how the system processes the data. In addition, it includes hundreds of pages of SQL examples and explanations. The Authors Tera-Tom Coffing, who has written over 75 successful books on Data Warehousing, and Jason Nolander, who has over 20 years of financial industry experience, have written a book that is sure to be your "go to" book on Hadoop.

- 546 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Tera-Tom Genius Series - Hadoop Architecture and SQL
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
Almacenamiento de datosChapter 1 – The Concepts of Hadoop
“Let me once again explain the rules. Hadoop Rules!”
- Tera-Tom Coffing
What is Hadoop All About?
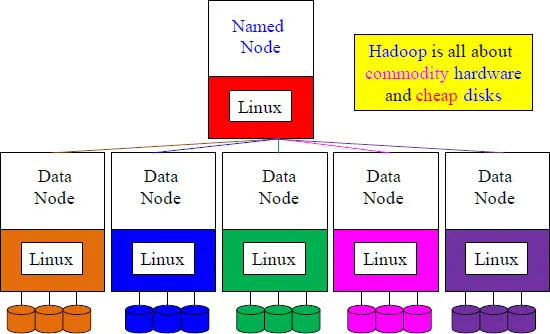
Hadoop is all about lower costs and better value! Hadoop leverages inexpensive commodity hardware servers and inexpensive disk storage. In all previous systems the servers were in the same location, but Hadoop allows for the servers to be scattered around the world. The disks are called JBOD (Just a Bunch of Disks) because they are just unsophisticated disks attached to the commodity hardware. This approach enables incredible capabilities while keeping costs down.
There is a Named Node and Up to 4000 Data Nodes
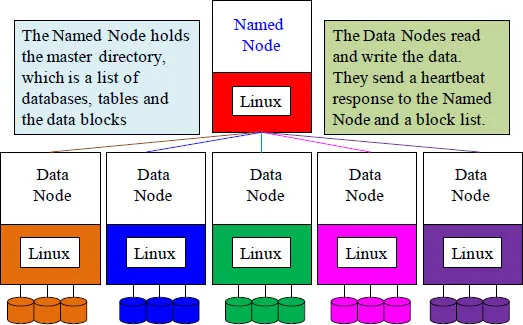
Hadoop is all about parallel processing, full table scans, unstructured data and commodity hardware. There is a single server that is called a “Named Node”. Its job is to keep track of all of the data files on the “Data Nodes”. The named node sends out a heartbeat each minute and the data nodes respond, or they are deemed dead. The Named Node holds a master directory of all databases created, delegates which tables reside on which data nodes, and directs where each data block of a table resides.
The Named Node's Directory Tree
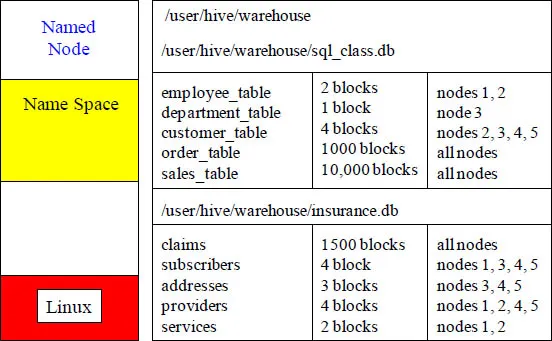
The named node keeps the directory tree (seen above) of all files in the Hadoop Distributed File System (HDFS), and tracks where across the cluster the file data is kept. It also sends out a heartbeat and keeps track of the health of the data nodes. It also helps client for reads/writes by receiving their requests and redirecting them to the appropriate data nodes. The named node acts as the host and the data nodes read and write the data as requested.
The Data Nodes
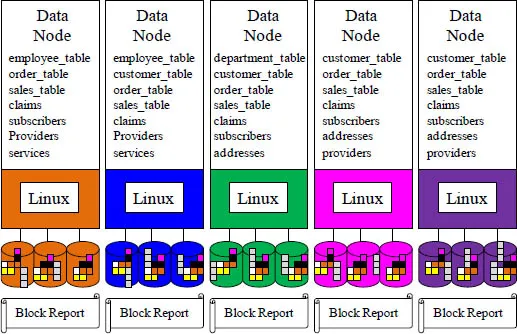
The named node sends out a heartbeat each minute and the data nodes respond, or they are deemed dead. The data nodes read and write the data that they are assigned. They also make a copy of each block of data they have and send it to two other nodes in the cluster as a backup in case they are deemed dead or they have a disk failure. There are three copies of every block in a Hadoop cluster as a failsafe mechanism. The data nodes also send a block report to the named node.
Hive MetaStore
Hadoop places data in files on commodity hardware that can be
structured or unstructured. Data stored does not have to be defined.
structured or unstructured. Data stored does not have to be defined.
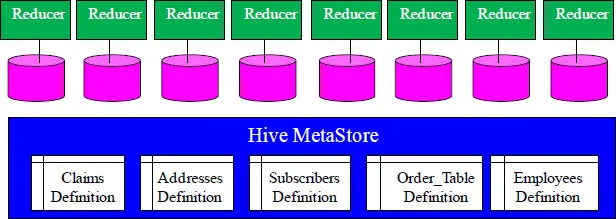
The Hive MetaStore stores table definitions and metadata.This allows
users to define table structures on data as applications need them.
users to define table structures on data as applications need them.
Hive has the Hive Metastore store for all table definitions and related metadata. Hive uses an Object Relational Mapper (ORM) to access relational databases, referred to as ORM. Valid Hive metastore database are growing and currently consist of MySQL, Oracle, PostgreSQL and Derby.
Data Layout and Protection – Step 1
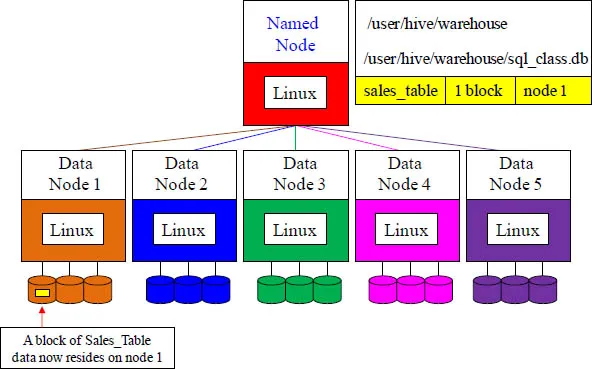
The Named Node holds a master directory of all databases created, delegates which tables reside on which data nodes, and directs where each data block of a table resides. Watch exactly what happens when the Sales_Table and others are built. The first step is that the named node has determined that the Sales_Table has one block of data and that it will be written to node 1. It is written.
Data Layout and Protection – Step 2
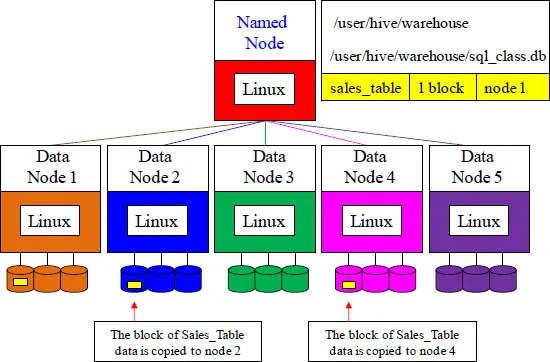
Data node 1 has written a block of the Sales_Table to its disk. Data node 1 will now communicate directly with two other data nodes in order to backup its Sales_Table block in case of a disaster. The block is copied to two other data nodes.
Data Layout and Protection – Step 3
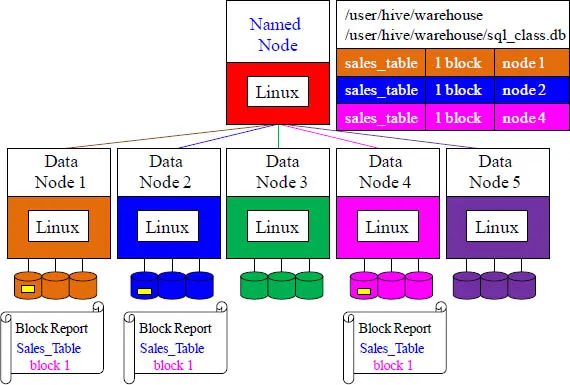
At a timed interval, all of the data nodes will provide a current block report to the named node. The named node will place this in its directory tree. The Sales_Table block is now stored in triplicate, just in case there is a disaster or a disk failure.
Data Layout and Protection – Step 4
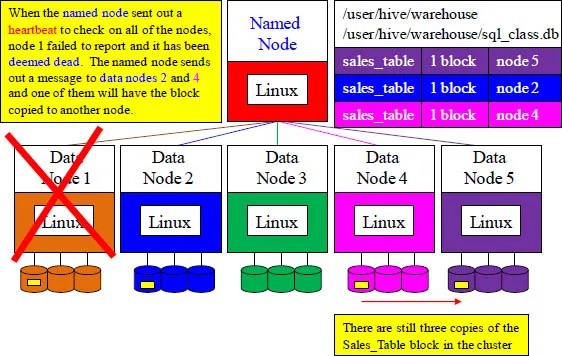
When the named node sent out a heartbeat to check on all of the nodes, node 1 failed to report and it was deemed dead. The named node sends out a message to data nodes 2 and 4 and one of them will have the block copied to another node. The block reports are sent back to the named node and the named node updates its system tree.
How are Blocks Distributed Amongst the Cluster?
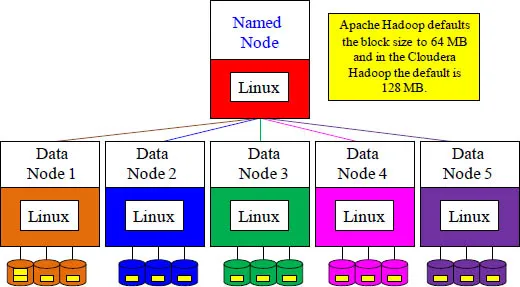
The table above is 1 GB. By default, the system put 16
(64 MB) blocks across the cluster, which equals 1 GB
(64 MB) blocks across the cluster, which equals 1 GB
Size of data matters. If you have a table with less than 64 MB of data, then it will only be stored in one block (replicated twice for disaster recovery). If the default block size was set to less than 64, there would be a huge number of blocks throughout the cluster, which causes the named node to manage an enormous amount of metadata. That is why Apache Hadoop defaults the block size to 64 MB and in the Cloudera Hadoop the default is 128 MB. Large blocks are distributed a...
Table of contents
- Cover
- The Tera-Tom Video Series
- The Tera-Tom Genius Series
- The Best Query Tool Works on all Systems
- Trademarks and Copyrights
- About Tom Coffing
- About Jason Nolander
- Contents
- Introduction
- Chapter 1 – The Concepts of Hadoop
- Chapter 2 – The Basics of SQL
- Chapter 3 – The WHERE Clause
- Chapter 4 – Distinct, Group By, Limit and Sample
- Chapter 5 – Aggregation
- Chapter 6 – Join Functions
- Chapter 7 – Sub-query Functions
- Chapter 8 – Date Functions
- Chapter 9 – OLAP Functions
- Chapter 10 – Temporary Tables
- Chapter 11 – Strings
- Chapter 12 – Interrogating the Data
- Chapter 13 – View Functions
- Chapter 14 – Creating Databases and Tables
- Chapter 15 – Data Manipulation Language (DML)
- Chapter 16 – Statistical Aggregate Functions
- Chapter 17 – Hadoop EXPLAIN
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Tera-Tom Genius Series - Hadoop Architecture and SQL by Tom Coffing,Jason Nolander in PDF and/or ePUB format, as well as other popular books in Ciencia de la computación & Almacenamiento de datos. We have over 1.5 million books available in our catalogue for you to explore.