Overcome advanced challenges in building end-to-end ML solutions by leveraging the capabilities of Amazon SageMaker for developing and integrating ML models into productionKey Features• Learn best practices for all phases of building machine learning solutions - from data preparation to monitoring models in production• Automate end-to-end machine learning workflows with Amazon SageMaker and related AWS• Design, architect, and operate machine learning workloads in the AWS CloudBook DescriptionAmazon SageMaker is a fully managed AWS service that provides the ability to build, train, deploy, and monitor machine learning models. The book begins with a high-level overview of Amazon SageMaker capabilities that map to the various phases of the machine learning process to help set the right foundation. You'll learn efficient tactics to address data science challenges such as processing data at scale, data preparation, connecting to big data pipelines, identifying data bias, running A/B tests, and model explainability using Amazon SageMaker. As you advance, you'll understand how you can tackle the challenge of training at scale, including how to use large data sets while saving costs, monitoring training resources to identify bottlenecks, speeding up long training jobs, and tracking multiple models trained for a common goal. Moving ahead, you'll find out how you can integrate Amazon SageMaker with other AWS to build reliable, cost-optimized, and automated machine learning applications. In addition to this, you'll build ML pipelines integrated with MLOps principles and apply best practices to build secure and performant solutions.By the end of the book, you'll confidently be able to apply Amazon SageMaker's wide range of capabilities to the full spectrum of machine learning workflows.What you will learn• Perform data bias detection with AWS Data Wrangler and SageMaker Clarify• Speed up data processing with SageMaker Feature Store• Overcome labeling bias with SageMaker Ground Truth• Improve training time with the monitoring and profiling capabilities of SageMaker Debugger• Address the challenge of model deployment automation with CI/CD using the SageMaker model registry• Explore SageMaker Neo for model optimization• Implement data and model quality monitoring with Amazon Model Monitor• Improve training time and reduce costs with SageMaker data and model parallelismWho this book is forThis book is for expert data scientists responsible for building machine learning applications using Amazon SageMaker. Working knowledge of Amazon SageMaker, machine learning, deep learning, and experience using Jupyter Notebooks and Python is expected. Basic knowledge of AWS related to data, security, and monitoring will help you make the most of the book.

- 348 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Amazon SageMaker Best Practices
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Section 1: Processing Data at Scale
This section sets the foundation for the rest of the book with an overview of Amazon SageMaker capabilities, a review of technical requirements, and insights on setting up the data science environment on AWS. This section then addresses the challenges involved in labeling and preparing large volumes of data. You will learn how to apply appropriate Amazon SageMaker capabilities and related services to derive features from raw data and persist features for reuse. Further, you will also learn how to persist features in a centralized repository to share across multiple ML projects.
This section comprises the following chapters:
- Chapter 1, Amazon SageMaker Overview
- Chapter 2, Data Science Environments
- Chapter 3, Data Labeling with Amazon SageMaker Ground Truth
- Chapter 4, Data Preparation at Scale Using Amazon SageMaker Data Wrangler and Processing
- Chapter 5, Centralized Feature Repository with Amazon SageMaker Feature Store
Chapter 1: Amazon SageMaker Overview
This chapter will provide a high-level overview of the Amazon SageMaker capabilities that map to the various phases of the machine learning (ML) process. This will set a foundation for the best practices discussion of using SageMaker capabilities in order to handle various data science challenges.
In this chapter, we're going to cover the following main topics:
- Preparing, building, training and tuning, deploying, and managing ML models
- Discussion of data preparation capabilities
- Feature tour of model-building capabilities
- Feature tour of training and tuning capabilities
- Feature tour of model management and deployment capabilities
Technical requirements
All notebooks with coding exercises will be available at the following GitHub link:
https://github.com/PacktPublishing/Amazon-SageMaker-Best-Practices
Preparing, building, training and tuning, deploying, and managing ML models
First, let's review the ML life cycle. By the end of this section, you should understand how SageMaker's capabilities map to the key phases of the ML life cycle. The following diagram shows you what the ML life cycle looks like:
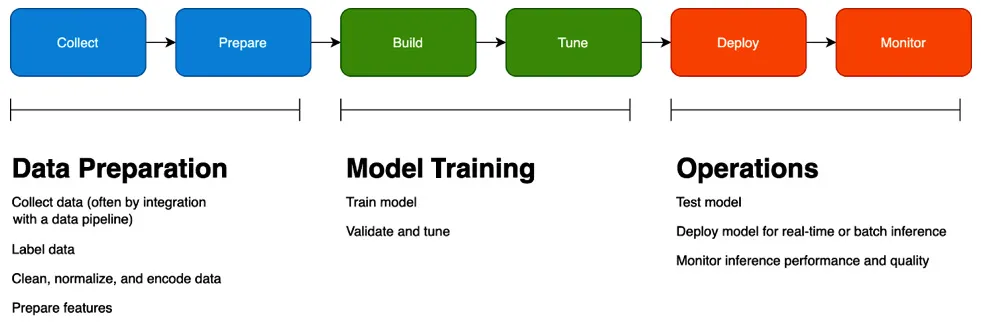
Figure 1.1 – Machine learning life cycle
As you can see, there are three phases of the ML life cycle at a high level:
- In the Data Preparation phase, you collect and explore data, label a ground truth dataset, and prepare your features. Feature engineering, in turn, has several steps, including data normalization, encoding, and calculating embeddings, depending on the ML algorithm you choose.
- In the Model Training phase, you build your model and tune it until you achieve a reasonable validation score that aligns with your business objective.
- In the Operations phase, you test how well your model performs against real-world data, deploy it, and monitor how well it performs. We will cover model monitoring in more detail in Chapter 11, Monitoring Production Models with Amazon SageMaker Model Monitor and Clarify.
This diagram is purposely simplified; in reality, each phase may have multiple smaller steps, and the whole life cycle is iterative. You're never really done with ML; as you gather data on how your model performs in production, you'll likely try to improve it by collecting more data, changing your features, or tuning the model.
So how do SageMaker capabilities map to the ML life cycle? Before we answer that question, let's take a look at the SageMaker console (Figure 1.2):
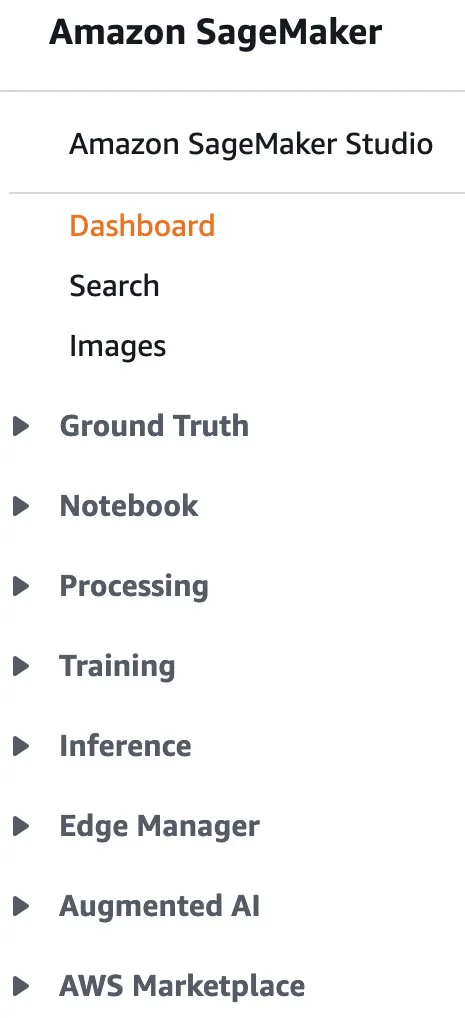
Figure 1.2 – Navigation pane in the SageMaker console
The appearance of the console changes frequently and the preceding screenshot shows the current appearance of the console at the time of writing.
These capability groups align to the ML life cycle, shown as follows:
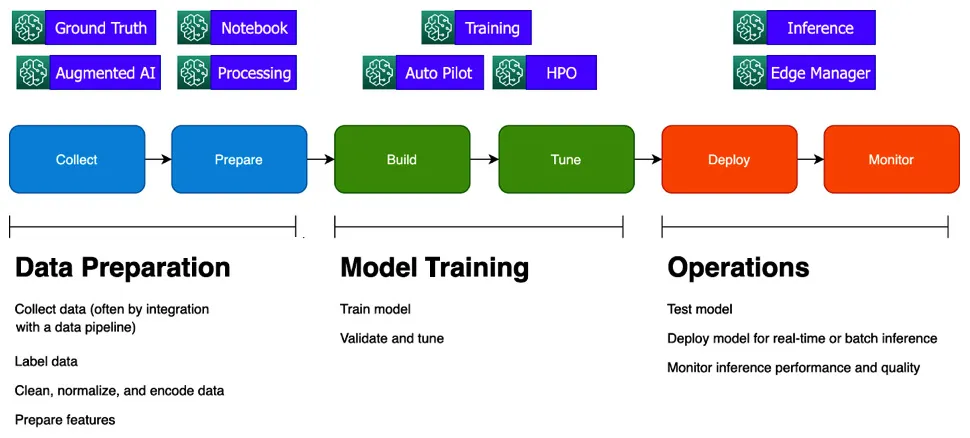
Figure 1.3 – Mapping of SageMaker capabilities to the ML life cycle
SageMaker Studio is not shown here, as it is an integrated workbench that provides a user interface for many SageMaker capabilities. The marketplace provides both data and algorithms that can be used across the life cycle.
Now that we have had a look at the console, let's dive deeper into the individual capabilities of SageMaker in each life cycle phase.
Discussion of data preparation capabilities
In this section, we'll dive into SageMaker's data preparation and feature engineering capabilities. By the end of this section, you should understand when to use SageMaker Ground Truth, Data Wrangler, Processing, Feature Store, and Clarify.
SageMaker Ground Truth
Obtaining labeled data for classification, regression, and other tasks is often the biggest barrier to ML projects, as many companies have a lot of data but have not explicitly labeled it according to business properties such as anomalous and high lifetime value. SageMaker Ground Truth helps you systematically label data by defining a labeling workflow and assigning labeling tasks to a human workforce.
Over time, Ground Truth can learn how to label data automatica...
Table of contents
- Amazon SageMaker Best Practices
- Contributors
- Preface
- Section 1: Processing Data at Scale
- Chapter 1: Amazon SageMaker Overview
- Chapter 2: Data Science Environments
- Chapter 3: Data Labeling with Amazon SageMaker Ground Truth
- Chapter 4: Data Preparation at Scale Using Amazon SageMaker Data Wrangler and Processing
- Chapter 5: Centralized Feature Repository with Amazon SageMaker Feature Store
- Section 2: Model Training Challenges
- Chapter 6: Training and Tuning at Scale
- Chapter 7: Profile Training Jobs with Amazon SageMaker Debugger
- Section 3: Manage and Monitor Models
- Chapter 8: Managing Models at Scale Using a Model Registry
- Chapter 9: Updating Production Models Using Amazon SageMaker Endpoint Production Variants
- Chapter 10: Optimizing Model Hosting and Inference Costs
- Chapter 11: Monitoring Production Models with Amazon SageMaker Model Monitor and Clarify
- Section 4: Automate and Operationalize Machine Learning
- Chapter 12: Machine Learning Automated Workflows
- Chapter 13:Well-Architected Machine Learning with Amazon SageMaker
- Chapter 14: Managing SageMaker Features across Accounts
- Other Books You May Enjoy
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Amazon SageMaker Best Practices by Sireesha Muppala,Randy DeFauw,Shelbee Eigenbrode in PDF and/or ePUB format, as well as other popular books in Computer Science & Artificial Intelligence (AI) & Semantics. We have over 1.5 million books available in our catalogue for you to explore.