Amazon SageMaker Best Practices
Sireesha Muppala, Randy DeFauw, Shelbee Eigenbrode
- 348 Seiten
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
Amazon SageMaker Best Practices
Sireesha Muppala, Randy DeFauw, Shelbee Eigenbrode
Über dieses Buch
Overcome advanced challenges in building end-to-end ML solutions by leveraging the capabilities of Amazon SageMaker for developing and integrating ML models into productionKey Features• Learn best practices for all phases of building machine learning solutions - from data preparation to monitoring models in production• Automate end-to-end machine learning workflows with Amazon SageMaker and related AWS• Design, architect, and operate machine learning workloads in the AWS CloudBook DescriptionAmazon SageMaker is a fully managed AWS service that provides the ability to build, train, deploy, and monitor machine learning models. The book begins with a high-level overview of Amazon SageMaker capabilities that map to the various phases of the machine learning process to help set the right foundation. You'll learn efficient tactics to address data science challenges such as processing data at scale, data preparation, connecting to big data pipelines, identifying data bias, running A/B tests, and model explainability using Amazon SageMaker. As you advance, you'll understand how you can tackle the challenge of training at scale, including how to use large data sets while saving costs, monitoring training resources to identify bottlenecks, speeding up long training jobs, and tracking multiple models trained for a common goal. Moving ahead, you'll find out how you can integrate Amazon SageMaker with other AWS to build reliable, cost-optimized, and automated machine learning applications. In addition to this, you'll build ML pipelines integrated with MLOps principles and apply best practices to build secure and performant solutions.By the end of the book, you'll confidently be able to apply Amazon SageMaker's wide range of capabilities to the full spectrum of machine learning workflows.What you will learn• Perform data bias detection with AWS Data Wrangler and SageMaker Clarify• Speed up data processing with SageMaker Feature Store• Overcome labeling bias with SageMaker Ground Truth• Improve training time with the monitoring and profiling capabilities of SageMaker Debugger• Address the challenge of model deployment automation with CI/CD using the SageMaker model registry• Explore SageMaker Neo for model optimization• Implement data and model quality monitoring with Amazon Model Monitor• Improve training time and reduce costs with SageMaker data and model parallelismWho this book is forThis book is for expert data scientists responsible for building machine learning applications using Amazon SageMaker. Working knowledge of Amazon SageMaker, machine learning, deep learning, and experience using Jupyter Notebooks and Python is expected. Basic knowledge of AWS related to data, security, and monitoring will help you make the most of the book.
Häufig gestellte Fragen
Information
Section 1: Processing Data at Scale
- Chapter 1, Amazon SageMaker Overview
- Chapter 2, Data Science Environments
- Chapter 3, Data Labeling with Amazon SageMaker Ground Truth
- Chapter 4, Data Preparation at Scale Using Amazon SageMaker Data Wrangler and Processing
- Chapter 5, Centralized Feature Repository with Amazon SageMaker Feature Store
Chapter 1: Amazon SageMaker Overview
- Preparing, building, training and tuning, deploying, and managing ML models
- Discussion of data preparation capabilities
- Feature tour of model-building capabilities
- Feature tour of training and tuning capabilities
- Feature tour of model management and deployment capabilities
Technical requirements
Preparing, building, training and tuning, deploying, and managing ML models
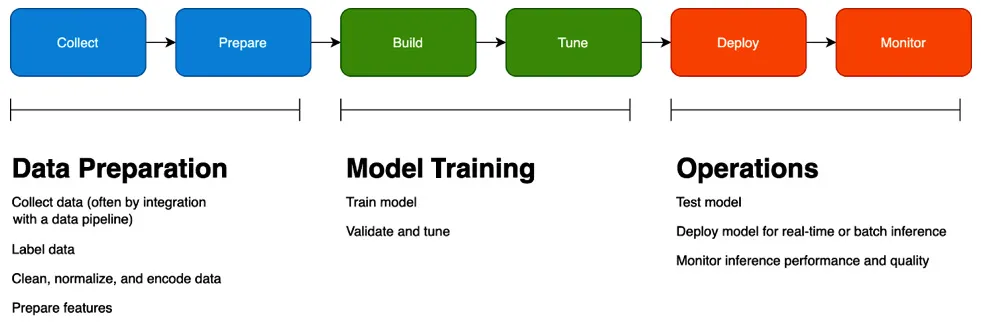
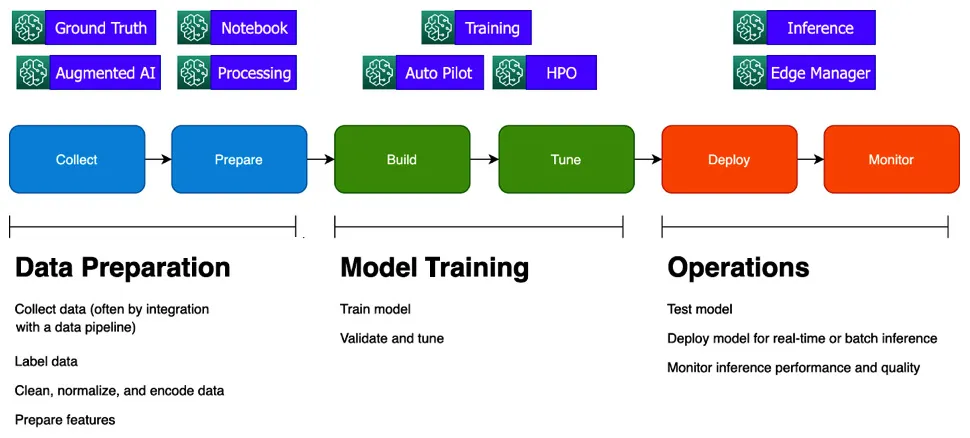
- In the Data Preparation phase, you collect and explore data, label a ground truth dataset, and prepare your features. Feature engineering, in turn, has several steps, including data normalization, encoding, and calculating embeddings, depending on the ML algorithm you choose.
- In the Model Training phase, you build your model and tune it until you achieve a reasonable validation score that aligns with your business objective.
- In the Operations phase, you test how well your model performs against real-world data, deploy it, and monitor how well it performs. We will cover model monitoring in more detail in Chapter 11, Monitoring Production Models with Amazon SageMaker Model Monitor and Clarify.