Understand the complexities of modern-day data engineering platforms and explore strategies to deal with them with the help of use case scenarios led by an industry expert in big dataKey Features• Become well-versed with the core concepts of Apache Spark and Delta Lake for building data platforms• Learn how to ingest, process, and analyze data that can be later used for training machine learning models• Understand how to operationalize data models in production using curated dataBook DescriptionIn the world of ever-changing data and schemas, it is important to build data pipelines that can auto-adjust to changes. This book will help you build scalable data platforms that managers, data scientists, and data analysts can rely on.Starting with an introduction to data engineering, along with its key concepts and architectures, this book will show you how to use Microsoft Azure Cloud services effectively for data engineering. You'll cover data lake design patterns and the different stages through which the data needs to flow in a typical data lake. Once you've explored the main features of Delta Lake to build data lakes with fast performance and governance in mind, you'll advance to implementing the lambda architecture using Delta Lake. Packed with practical examples and code snippets, this book takes you through real-world examples based on production scenarios faced by the author in his 10 years of experience working with big data. Finally, you'll cover data lake deployment strategies that play an important role in provisioning the cloud resources and deploying the data pipelines in a repeatable and continuous way.By the end of this data engineering book, you'll know how to effectively deal with ever-changing data and create scalable data pipelines to streamline data science, ML, and artificial intelligence (AI) tasks.What you will learn• Discover the challenges you may face in the data engineering world• Add ACID transactions to Apache Spark using Delta Lake• Understand effective design strategies to build enterprise-grade data lakes• Explore architectural and design patterns for building efficient data ingestion pipelines• Orchestrate a data pipeline for preprocessing data using Apache Spark and Delta Lake APIs• Automate deployment and monitoring of data pipelines in production• Get to grips with securing, monitoring, and managing data pipelines models efficientlyWho this book is forThis book is for aspiring data engineers and data analysts who are new to the world of data engineering and are looking for a practical guide to building scalable data platforms. If you already work with PySpark and want to use Delta Lake for data engineering, you'll find this book useful. Basic knowledge of Python, Spark, and SQL is expected.

eBook - ePub
Data Engineering with Apache Spark, Delta Lake, and Lakehouse
- 480 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Data Engineering with Apache Spark, Delta Lake, and Lakehouse
About this book
Trusted by 375,005 students
Access to over 1 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
InformatikSubtopic
Datenmodellierung- & designSection 1: Modern Data Engineering and Tools
This section introduces you to the world of data engineering. It gives you an understanding of data engineering concepts and architectures. Furthermore, it educates you on how to effectively utilize the Microsoft Azure cloud services for data engineering.
This section contains the following chapters:
- Chapter 1, The Story of Data Engineering and Analytics
- Chapter 2, Discovering Storage and Compute Data Lake Architectures
- Chapter 3, Data Engineering on Microsoft Azure
Chapter 1: The Story of Data Engineering and Analytics
Every byte of data has a story to tell. The real question is whether the story is being narrated accurately, securely, and efficiently. In the modern world, data makes a journey of its own—from the point it gets created to the point a user consumes it for their analytical requirements.
But what makes the journey of data today so special and different compared to before? After all, Extract, Transform, Load (ETL) is not something that recently got invented. In fact, I remember collecting and transforming data since the time I joined the world of information technology (IT) just over 25 years ago.
In this chapter, we will discuss some reasons why an effective data engineering practice has a profound impact on data analytics.
In this chapter, we will cover the following topics:
- The journey of data
- Exploring the evolution of data analytics
- The monetary power of dataRemember:the road to effective data analytics leads through effective data engineering.
The journey of data
Data engineering is the vehicle that makes the journey of data possible, secure, durable, and timely. A data engineer is the driver of this vehicle who safely maneuvers the vehicle around various roadblocks along the way without compromising the safety of its passengers. Waiting at the end of the road are data analysts, data scientists, and business intelligence (BI) engineers who are eager to receive this data and start narrating the story of data. You can see this reflected in the following screenshot:

Figure 1.1 – Data's journey to effective data analysis
Traditionally, the journey of data revolved around the typical ETL process. Unfortunately, the traditional ETL process is simply not enough in the modern era anymore. Due to the immense human dependency on data, there is a greater need than ever to streamline the journey of data by using cutting-edge architectures, frameworks, and tools.
You may also be wondering why the journey of data is even required. Gone are the days where datasets were limited, computing power was scarce, and the scope of data analytics was very limited. We now live in a fast-paced world where decision-making needs to be done at lightning speeds using data that is changing by the second. Let's look at how the evolution of data analytics has impacted data engineering.
Exploring the evolution of data analytics
Data analytics has evolved over time, enabling us to do bigger and better. For many years, the focus of data analytics was limited to descriptive analysis, where the focus was to gain useful business insights from data, in the form of a report. This type of analysis was useful to answer question such as "What happened?". A hypothetical scenario would be that the sales of a company sharply declined within the last quarter.
Very quickly, everyone started to realize that there were several other indicators available for finding out what happened, but it was the why it happened that everyone was after. The core analytics now shifted toward diagnostic analysis, where the focus is to identify anomalies in data to ascertain the reasons for certain outcomes. An example scenario would be that the sales of a company sharply declined in the last quarter because there was a serious drop in inventory levels, arising due to floods in the manufacturing units of the suppliers. This form of analysis further enhances the decision support mechanisms for users, as illustrated in the following diagram:
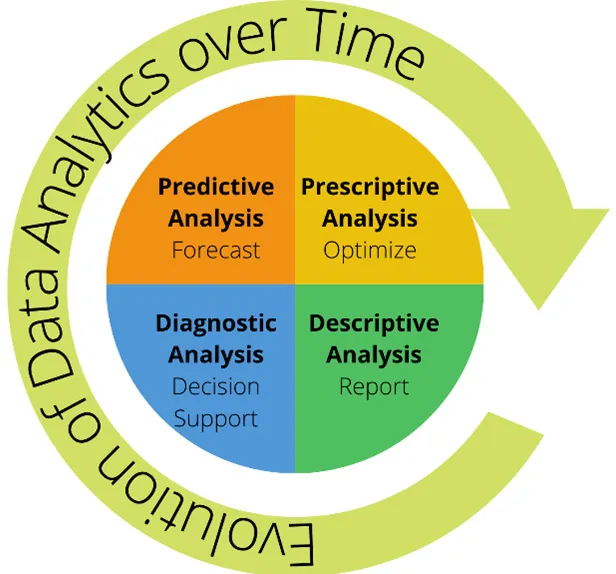
Figure 1.2 – The evolution of data analytics
Important note
Both descriptive analysis and diagnostic analysis try to impact the decision-making process using factual data only.
Since the advent of time, it has always been a core human desire to look beyond the present and try to forecast the future. If we can predict future outcomes, we can surely make a lot of better decisions, and so the era of predictive analysis dawned, where the focus revolves around "What will happen in the future?". Predictive analysis can be performed using machine learning (ML) algorithms—let the machine learn from existing and future data in a repeated fashion so that it can identify a pattern that enables it to predict future trends accurately.
Now that we are well set up to forecast future outcomes, we must use and optimize the outcomes of this predictive analysis. Based on the results of predictive analysis, the aim of prescriptive analysis is to provide a set of prescribed actions that can help meet business goals.
Important note
Unlike descriptive and diagnostic analysis, predictive and prescriptive analysis try to impact the decision-making process, using both factual and statistical data.
But how can the dreams of modern-day analysis be effectively realized? After all, data analysts and data scientists are not adequately skilled to collect, clean, and transform the vast amount of ever-increasing and changing datasets.
The data engineering practice is commonly referred to as the primary support for modern-day data analytics' needs.
The following are some major reasons as to why a strong data engineering practice is becoming an absolutely unignorable necessity for today's businesses:
- Core capabilities of compute and storage resources
- Availability of varying datasets
- The paradigm shift to distributed computing
- Adoption of cloud computing
- Data storytelling
We'll explore each of these in the following subsections.
Important note
Having a strong data engineering practice ensures the needs of modern analytics are met in terms of durability, performance, and scalability.
Core capabilities of storage and compute resources
25 years ago, I had an opportunity to buy a Sun Solaris server—128 megabytes (MB) random-access memory (RAM), 2 gigabytes (GB) storage—for close to $ 25K. The intended use of the server was to run a client/server application over an Oracle database in production. Given the high price of storage and compute resources, I had to enforce strict countermeasures to appropriately balance the demands of online transaction processing (OLTP) and online analytical processing (OLAP) of my users. One such limitation was implementing strict timings for when these programs could be...
Table of contents
- Data Engineering with Apache Spark, Delta Lake, and Lakehouse
- Foreword
- Preface
- Section 1: Modern Data Engineering and Tools
- Chapter 1: The Story of Data Engineering and Analytics
- Chapter 2: Discovering Storage and Compute Data Lakes
- Chapter 3: Data Engineering on Microsoft Azure
- Section 2: Data Pipelines and Stages of Data Engineering
- Chapter 4: Understanding Data Pipelines
- Chapter 5: Data Collection Stage – The Bronze Layer
- Chapter 6: Understanding Delta Lake
- Chapter 7: Data Curation Stage – The Silver Layer
- Chapter 8: Data Aggregation Stage – The Gold Layer
- Section 3: Data Engineering Challenges and Effective Deployment Strategies
- Chapter 9: Deploying and Monitoring Pipelines in Production
- Chapter 10: Solving Data Engineering Challenges
- Chapter 11: Infrastructure Provisioning
- Chapter 12: Continuous Integration and Deployment (CI/CD) of Data Pipelines
- Other Books You May Enjoy
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Engineering with Apache Spark, Delta Lake, and Lakehouse by Manoj Kukreja,Danil Zburivsky in PDF and/or ePUB format, as well as other popular books in Informatik & Datenmodellierung- & design. We have over one million books available in our catalogue for you to explore.