Get started with distributed computing using PySpark, a single unified framework to solve end-to-end data analytics at scaleKey Features• Discover how to convert huge amounts of raw data into meaningful and actionable insights• Use Spark's unified analytics engine for end-to-end analytics, from data preparation to predictive analytics• Perform data ingestion, cleansing, and integration for ML, data analytics, and data visualizationBook DescriptionApache Spark is a unified data analytics engine designed to process huge volumes of data quickly and efficiently. PySpark is Apache Spark's Python language API, which offers Python developers an easy-to-use scalable data analytics framework. Essential PySpark for Scalable Data Analytics starts by exploring the distributed computing paradigm and provides a high-level overview of Apache Spark. You'll begin your analytics journey with the data engineering process, learning how to perform data ingestion, cleansing, and integration at scale. This book helps you build real-time analytics pipelines that help you gain insights faster. You'll then discover methods for building cloud-based data lakes, and explore Delta Lake, which brings reliability to data lakes. The book also covers Data Lakehouse, an emerging paradigm, which combines the structure and performance of a data warehouse with the scalability of cloud-based data lakes. Later, you'll perform scalable data science and machine learning tasks using PySpark, such as data preparation, feature engineering, and model training and productionization. Finally, you'll learn ways to scale out standard Python ML libraries along with a new pandas API on top of PySpark called Koalas. By the end of this PySpark book, you'll be able to harness the power of PySpark to solve business problems.What you will learn• Understand the role of distributed computing in the world of big data• Gain an appreciation for Apache Spark as the de facto go-to for big data processing• Scale out your data analytics process using Apache Spark• Build data pipelines using data lakes, and perform data visualization with PySpark and Spark SQL• Leverage the cloud to build truly scalable and real-time data analytics applications• Explore the applications of data science and scalable machine learning with PySpark• Integrate your clean and curated data with BI and SQL analysis toolsWho this book is forThis book is for practicing data engineers, data scientists, data analysts, and data enthusiasts who are already using data analytics to explore distributed and scalable data analytics. Basic to intermediate knowledge of the disciplines of data engineering, data science, and SQL analytics is expected. General proficiency in using any programming language, especially Python, and working knowledge of performing data analytics using frameworks such as pandas and SQL will help you to get the most out of this book.

- 322 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Essential PySpark for Scalable Data Analytics
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Section 1: Data Engineering
This section introduces the uninitiated to the Distributed Computing paradigm and shows how Spark became the de facto standard for big data processing.
Upon completion of this section, you will be able to ingest data from various data sources, cleanse it, integrate it, and write it out to persistent storage such as a data lake in a scalable and distributed manner. You will also be able to build real-time analytics pipelines and perform change data capture in a data lake. You will understand the key differences between the ETL and ELT ways of data processing, and how ELT evolved for the cloud-based data lake world. This section also introduces you to Delta Lake to make cloud-based data lakes more reliable and performant. You will understand the nuances of Lambda architecture as a means to perform simultaneous batch and real-time analytics and how Apache Spark combined with Delta Lake greatly simplifies Lambda architecture.
This section includes the following chapters:
- Chapter 1, Distributed Computing Primer
- Chapter 2, Data Ingestion
- Chapter 3, Data Cleansing and Integration
- Chapter 4, Real-Time Data Analytics
Chapter 1: Distributed Computing Primer
This chapter introduces you to the Distributed Computing paradigm and shows you how Distributed Computing can help you to easily process very large amounts of data. You will learn about the concept of Data Parallel Processing using the MapReduce paradigm and, finally, learn how Data Parallel Processing can be made more efficient by using an in-memory, unified data processing engine such as Apache Spark.
Then, you will dive deeper into the architecture and components of Apache Spark along with code examples. Finally, you will get an overview of what's new with the latest 3.0 release of Apache Spark.
In this chapter, the key skills that you will acquire include an understanding of the basics of the Distributed Computing paradigm and a few different implementations of the Distributed Computing paradigm such as MapReduce and Apache Spark. You will learn about the fundamentals of Apache Spark along with its architecture and core components, such as the Driver, Executor, and Cluster Manager, and how they come together as a single unit to perform a Distributed Computing task. You will learn about Spark's Resilient Distributed Dataset (RDD) API along with higher-order functions and lambdas. You will also gain an understanding of the Spark SQL Engine and its DataFrame and SQL APIs. Additionally, you will implement working code examples. You will also learn about the various components of an Apache Spark data processing program, including transformations and actions, and you will learn about the concept of Lazy Evaluation.
In this chapter, we're going to cover the following main topics:
- Introduction Distributed Computing
- Distributed Computing with Apache Spark
- Big data processing with Spark SQL and DataFrames
Technical requirements
In this chapter, we will be using the Databricks Community Edition to run our code. This can be found at https://community.cloud.databricks.com.
Sign-up instructions can be found at https://databricks.com/try-databricks.
The code used in this chapter can be downloaded from https://github.com/PacktPublishing/Essential-PySpark-for-Data-Analytics/tree/main/Chapter01.
The datasets used in this chapter can be found at https://github.com/PacktPublishing/Essential-PySpark-for-Data-Analytics/tree/main/data.
The original datasets can be taken from their sources, as follows:
- Online Retail: https://archive.ics.uci.edu/ml/datasets/Online+Retail+II
- Image Data: https://archive.ics.uci.edu/ml/datasets/Rice+Leaf+Diseases
- Census Data: https://archive.ics.uci.edu/ml/datasets/Census+Income
- Country Data: https://public.opendatasoft.com/explore/dataset/countries-codes/information/
Distributed Computing
In this section, you will learn about Distributed Computing, the need for it, and how you can use it to process very large amounts of data in a quick and efficient manner.
Introduction to Distributed Computing
Distributed Computing is a class of computing techniques where we use a group of computers as a single unit to solve a computational problem instead of just using a single machine.
In data analytics, when the amount of data becomes too large to fit in a single machine, we can either split the data into smaller chunks and process it on a single machine iteratively, or we can process the chunks of data on several machines in parallel. While the former gets the job done, it might take longer to process the entire dataset iteratively; the latter technique gets the job completed in a shorter period of time by using multiple machines at once.
There are different kinds of Distributed Computing techniques; however, for data analytics, one popular technique is Data Parallel Processing.
Data Parallel Processing
Data Parallel Processing involves two main parts:
- The actual data that needs to be processed
- The piece of code or business logic that needs to be applied to the data in order to process it
We can process large amounts of data by splitting it into smaller chunks and processing them in parallel on several machines. This can be done in two ways:
- First, bring the data to the machine where our code is running.
- Second, take our code to where our data is actually stored.
One drawback of the first technique is that as our data sizes become larger, the amount of time it takes to move data also increases proportionally. Therefore, we end up spending more time moving data from one system to another and, in turn, negating any efficiency gained by our parallel processing system. We also find ourselves creating multiple copies of data during data replication.
The second technique is far more efficient because instead of moving large amounts of data, we can easily move a few lines of code to where our data actually resides. This technique of moving code to where the data resides is referred to as Data Parallel Processing. This Data Parallel Processing technique is very fast and efficient, as we save the amount of time that was needed earlier to move and copy data across different systems. One such Data Parallel Processing technique is called the MapReduce paradigm.
Data Parallel Processing using the MapReduce paradigm
The MapReduce paradigm breaks down a Data Parallel Processing problem into three main stages:
- The Map stage
- The Shuffle stage
- The Reduce stage
The Map stage takes the input dataset, splits it into (key, value) pairs, applies some processing on the pairs, and transforms them into another set of (key, value) pairs.
The Shuffle stage takes the (key, value) pairs from the Map stage and shuffles/sorts them so that pairs with the same key end up together.
The Reduce stage takes the resultant (key, value) pairs from the Shuffle stage and reduces or aggregates the pairs to produce the final result.
There can be multiple Map stages followed by multiple Reduce stages. However, a Reduce stage only starts after all of the Map stages have been completed.
Let's take a look at an example where we want to calculate the counts of all the different words in a text document and apply the MapReduce paradigm to it.
The following diagram shows how the MapReduce paradigm works in general:
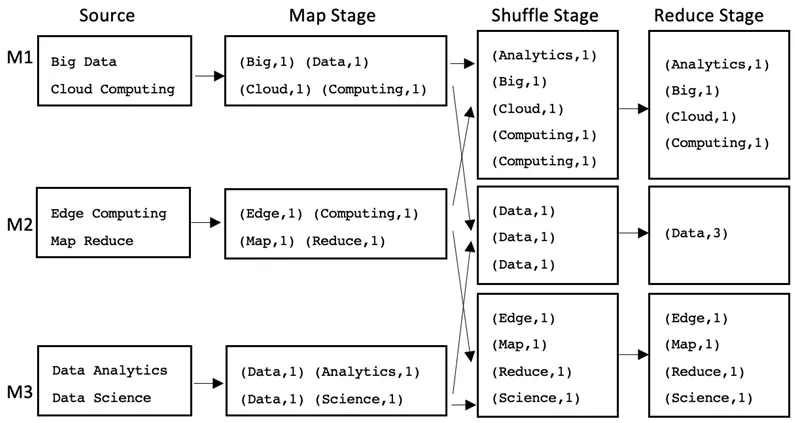
Figure 1.1 – Calculating the word count...
Table of contents
- Essential PySpark for Scalable Data Analytics
- Contributors
- Preface
- Section 1: Data Engineering
- Chapter 1: Distributed Computing Primer
- Chapter 2: Data Ingestion
- Chapter 3: Data Cleansing and Integration
- Chapter 4: Real-Time Data Analytics
- Section 2: Data Science
- Chapter 5: Scalable Machine Learning with PySpark
- Chapter 6: Feature Engineering – Extraction, Transformation, and Selection
- Chapter 7: Supervised Machine Learning
- Chapter 8: Unsupervised Machine Learning
- Chapter 9: Machine Learning Life Cycle Management
- Chapter 10: Scaling Out Single-Node Machine Learning Using PySpark
- Section 3: Data Analysis
- Chapter 11: Data Visualization with PySpark
- Chapter 12: Spark SQL Primer
- Chapter 13: Integrating External Tools with Spark SQL
- Chapter 14: The Data Lakehouse
- Other Books You May Enjoy
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Essential PySpark for Scalable Data Analytics by Sreeram Nudurupati in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Processing. We have over 1.5 million books available in our catalogue for you to explore.