Accelerate computations and make the most of your data effectively and efficiently on DatabricksKey Features• Understand Spark optimizations for big data workloads and maximizing performance• Build efficient big data engineering pipelines with Databricks and Delta Lake• Efficiently manage Spark clusters for big data processingBook DescriptionDatabricks is an industry-leading, cloud-based platform for data analytics, data science, and data engineering supporting thousands of organizations across the world in their data journey. It is a fast, easy, and collaborative Apache Spark-based big data analytics platform for data science and data engineering in the cloud.In Optimizing Databricks Workloads, you will get started with a brief introduction to Azure Databricks and quickly begin to understand the important optimization techniques. The book covers how to select the optimal Spark cluster configuration for running big data processing and workloads in Databricks, some very useful optimization techniques for Spark DataFrames, best practices for optimizing Delta Lake, and techniques to optimize Spark jobs through Spark core. It contains an opportunity to learn about some of the real-world scenarios where optimizing workloads in Databricks has helped organizations increase performance and save costs across various domains.By the end of this book, you will be prepared with the necessary toolkit to speed up your Spark jobs and process your data more efficiently.What you will learn• Get to grips with Spark fundamentals and the Databricks platform• Process big data using the Spark DataFrame API with Delta Lake• Analyze data using graph processing in Databricks• Use MLflow to manage machine learning life cycles in Databricks• Find out how to choose the right cluster configuration for your workloads• Explore file compaction and clustering methods to tune Delta tables• Discover advanced optimization techniques to speed up Spark jobsWho this book is forThis book is for data engineers, data scientists, and cloud architects who have working knowledge of Spark/Databricks and some basic understanding of data engineering principles. Readers will need to have a working knowledge of Python, and some experience of SQL in PySpark and Spark SQL is beneficial.

- 230 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Optimizing Databricks Workloads
About this book
Trusted by 375,005 students
Access to over 1 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Section 1: Introduction to Azure Databricks
In this section, we cover a quick introduction to Azure Databricks and several of its APIs for analyzing and processing big data – DataFrames, ML, Graph, and Streaming.
This section comprises the following chapters:
- Chapter 1, Discovering Databricks
- Chapter 2, Batch and Real-Time Processing in Databricks
- Chapter 3, Learning about Machine Learning and Graph Processing in Databricks
Chapter 1: Discovering Databricks
The original creators of Apache Spark established Databricks to solve the world's toughest data problems. Databricks was launched as a Spark-based unified data analytics platform in the cloud.
In this chapter, we will begin by understanding the internal architecture of Apache Spark™. This will be followed by an introduction to the basic components of Databricks. The following topics will be covered in this chapter:
- Introducing Spark fundamentals
- Introducing Databricks
- Learning about Delta Lake
Technical requirements
For this chapter, you will need the following:
- An Azure subscription
- Azure Databricks
Please refer to the code sample from: Code samples from https://github.com/PacktPublishing/Optimizing-Databricks-Workload/tree/main/Chapter01
Introducing Spark fundamentals
Spark is a distributed data processing framework capable of analyzing large datasets. At its very core, it consists of the following:
- DataFrames: Fundamental data structures consisting of rows and columns.
- Machine Learning (ML): Spark ML provides ML algorithms for processing big data.
- Graph processing: GraphX helps to analyze relationships between objects.
- Streaming: Spark's Structured Streaming helps to process real-time data.
- Spark SQL: A SQL to Spark engine with query plans and a cost-based optimizer.
DataFrames in Spark are built on top of Resilient Distributed Datasets (RDDs), which are now treated as the assembly language of the Spark ecosystem. Spark is compatible with various programming languages – Scala, Python, R, Java, and SQL.
Spark encompasses an architecture with one driver node and multiple worker nodes. The driver and worker nodes together constitute a Spark cluster. Under the hood, these nodes are based in Java Virtual Machines (JVMs). The driver is responsible for assigning and coordinating work between the workers.
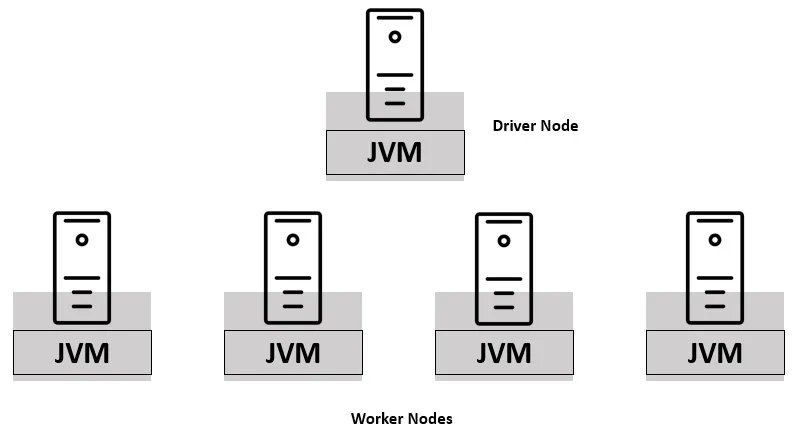
Figure 1.1 – Spark architecture – driver and workers
The worker nodes have executors running inside each of them, which host the Spark program. Each executor consists of one or more slots that act as the compute resource. Each slot can process a single unit of work at a time.
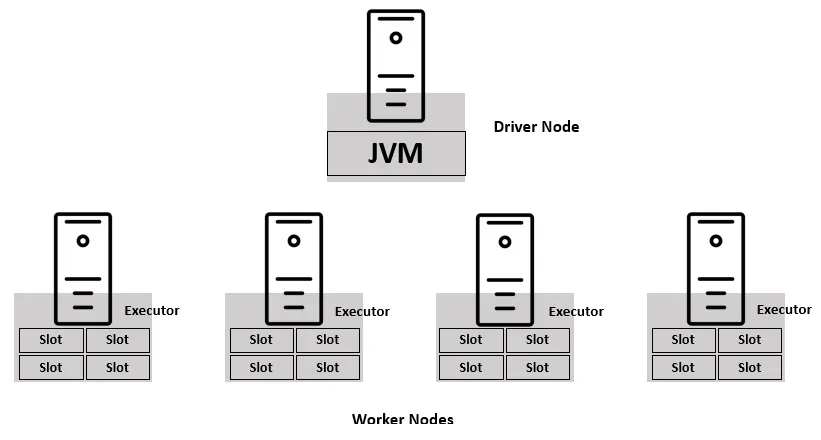
Figure 1.2 – Spark architecture – executors and slots
Every executor reserves memory for two purposes:
- Cache
- Computation
The cache section of the memory is used to store the DataFrames in a compressed format (called caching), while the compute section is utilized for data processing (aggregations, joins, and so on). For resource allocation, Spark can be used with a cluster manager that is responsible for provisioning the nodes of the cluster. Databricks has an in-built cluster manager as part of its overall offering.
Note
Executor slots are also called cores or threads.
Spark supports parallelism in two ways:
- Vertical parallelism: Scaling the number of slots in the executors
- Horizontal parallelism: Scaling the number of executors in a Spark cluster
Spark processes the data by breaking it down into chunks called partitions. These partitions are usually 128 MB blocks that are read by the executors and assigned to them by the driver. The size and the number of partitions are decided by the driver node. While writing Spark code, we come across two functionalities, transformations and actions. Transformations instruct the Spark cluster to perform changes to the DataFrame. These are further categorized into narrow transformations and wide transformations. Wide transformations lead to the shuffling of data as data requires movement across executors, whereas narrow transformations do not lead to re-partitioning across executors.
Running these transformations does not make the Spark cluster do anything. It is only when an action is called that the Spark cluster begins execution, hence the saying Spark is lazy. Before executing an action, all that Spark does is make a data processing plan. We call this plan the Directed Acyclic Graph (DAG). The DAG consists of various transformations such as read, filter, and join and...
Table of contents
- Optimizing Databricks Workloads
- Contributors
- Preface
- Section 1: Introduction to Azure Databricks
- Chapter 1: Discovering Databricks
- Chapter 2: Batch and Real-Time Processing in Databricks
- Chapter 3: Learning about Machine Learning and Graph Processing in Databricks
- Section 2: Optimization Techniques
- Chapter 4: Managing Spark Clusters
- Chapter 5: Big Data Analytics
- Chapter 6: Databricks Delta Lake
- Chapter 7: Spark Core
- Section 3: Real-World Scenarios
- Chapter 8: Case Studies
- Other Books You May Enjoy
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Optimizing Databricks Workloads by Anirudh Kala,Anshul Bhatnagar,Sarthak Sarbahi in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Science General. We have over one million books available in our catalogue for you to explore.