The book elaborates in detail on the current needs of data mining and machine learning and promotes mutual understanding among research in different disciplines, thus facilitating research development and collaboration.
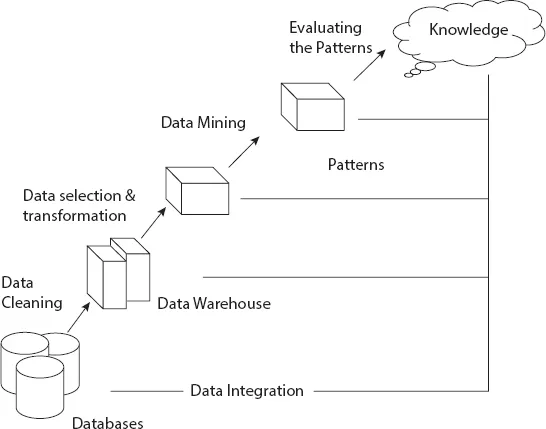
Data, the latest currency of today's world, is the new gold. In this new form of gold, the most beautiful jewels are data analytics and machine learning. Data mining and machine learning are considered interdisciplinary fields. Data mining is a subset of data analytics and machine learning involves the use of algorithms that automatically improve through experience based on data.
Massive datasets can be classified and clustered to obtain accurate results. The most common technologies used include classification and clustering methods. Accuracy and error rates are calculated for regression and classification and clustering to find actual results through algorithms like support vector machines and neural networks with forward and backward propagation. Applications include fraud detection, image processing, medical diagnosis, weather prediction, e-commerce and so forth.
The book features:
- A review of the state-of-the-art in data mining and machine learning,
- A review and description of the learning methods in human-computer interaction,
- Implementation strategies and future research directions used to meet the design and application requirements of several modern and real-time applications for a long time,
- The scope and implementation of a majority of data mining and machine learning strategies.
- A discussion of real-time problems.
Audience
Industry and academic researchers, scientists, and engineers in information technology, data science and machine and deep learning, as well as artificial intelligence more broadly.