Text Analytics: An Introduction to the Science and Applications of Unstructured Information Analysis is a concise and accessible introduction to the science and applications of text analytics (or text mining), which enables automatic knowledge discovery from unstructured information sources, for both industrial and academic purposes. The book introduces the main concepts, models, and computational techniques that enable the reader to solve real decision-making problems arising from textual and/or documentary sources.
Features:
Easy-to-follow step-by-step concepts and methods
Every chapter is introduced in a very gentle and intuitive way so students can understand the WHYs, WHAT-IFs, WHAT-IS-THIS-FORs, HOWs, etc. by themselves
Practical programming exercises in Python for each chapter
Includes theory and practice for every chapter, summaries, practical coding exercises for target problems, QA, and sample code and data available for download at https://www.routledge.com/Atkinson-Abutridy/p/book/9781032249797
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
There are thousands of scientific articles in the world on viruses and diseases that human specialists aren’t able to read or analyze. How could computers process such documents and be able to make discoveries and/or detect patterns of interest so that humans can make decisions about new treatments, drugs, and interactions between bio-components? A company receives hundreds of complaints or inquiries from customers daily through its website or emails. How could this company analyze those complaints to study and determine common behaviors and customer profiles in order to offer them a better service? An Internet news outlet receives hundreds of national and international news reports weekly. How could this medium synthesize, group, or characterize them to provide more filtered and digested information to readers seeking specific data? As a result of several national events, various public bodies receive thousands of opinion messages through social networks such as Twitter. How could these messages be analyzed in order to determine trends and/or preferences of users regarding those events?
Clearly, in the last decades, we’ve experienced a gigantic growth of the data available in various electronic media. The information overload is such that it becomes very difficult to take advantage of such data using conventional technologies, so new abilities are required for its efficient analysis. This will depend on the nature of the information, which in general can be divided into two large groups:
Structured data: Corresponds to data that have been organized in repositories such as a database, so that its elements can be accessed by effective analysis and processing methods (i.e., an SQL table).
Non-Structured data: Corresponds to data that don’t have a predefined structure or model or that’s not organized in a predefined way, making them hard to understand using traditional computational methods (i.e., news and customer complaints).
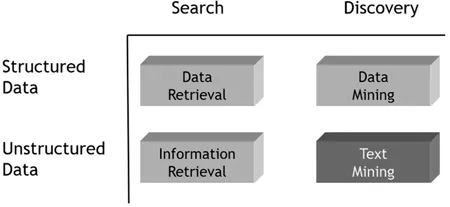
Depending on the nature of the data, we can perform two types of tasks on them: search and discovery, as shown in Figure 1.1.
FIGURE1.1 Search versus data discovery.
A search task is goal-oriented, which means that you must provide a clear criterion to receive the results that you need (i.e., a condition that must be met by the data attributes). In this scenario, we’re not looking for anything new, we’re only reducing the information overload, retrieving only data which satisfy certain conditions (Zhai & Massung, 2016). Then,
If data are structured: We must specify some condition, key or characteristic, of the data we want to search. For example, you want to retrieve the information of all the clients that were registered in a company in 2018 from a SQL database. For this, there are usually database engines capable of efficiently accessing, query and retrieve data from a previously specified combination of attributes (i.e., a structured query).
If data are not structured: We must then search for documents relevant to a query, consisting of a list of keywords. For example, you want to search documents online that contain the terms rent and houses. For this, information retrieval (IR) technologies (Büttcher et al., 2010) are usually available in the form of web search engines such as Google and Yahoo or specialized search systems (i.e., MEDLINE medical literature search engines1).
Unlike search, a discovery task is by nature opportunistic, that is, you don’t know what you want to search for, so data hypotheses are automatically explored to discover new opportunities in the form of data hidden patterns (or latent), which can be interesting and novel. Then,
If data are structured: We must have some discovery task in mind so that later, some Data Mining technology (Tan et al., 2018) can mine the data to discover or extract hidden patterns that are actionable, that is, having the ability to act regarding some kind of process that produces real results. For example, given a database of purchase transactions made by customers in a supermarket, we would like to know if there’s any behavior pattern which allows us to understand how these purchases are associated with each other, to make recommendations, create better promotions, adjust the product layout, etc.
If data are not structured: We must have some discovery task in mind about textual data, so that later, some Text Mining or Textual Analytics Technology can automatically discover hidden patterns in texts that support decision-making. For example, given a set of documents that describe complaints from clients of a company, we would like to find patterns that allow characterizing these complaints, finding nonobvious connections between them, and grouping them to generate recommendations.
The nature of unstructured data and the complexity of its analysis have generated a growing need for technologies that allow it to be analyzed and automatically discover insights (i.e., hidden aspects regarding how users/clients act, which can generate opportunities for new products/services, strategies, etc.). This becomes even more latent at the business level, considering that unstructured information represents more than 85% of the data handled by corporations. Hence, this has impacted practically all industrial, public, scientific, and technological areas in a transversal way. Thus, we can find different types of textual information, including emails, insurance claims statements, news pages, scientific articles, innovation patents descriptions, customer complaints, business contracts, and opinions on forums and/or social networks, among others.
1https://www.nlm.nih.gov/bsd/medline.html.
Clearly, it’s not possible to analyze this kind of data with known Data Mining techniques, due to its linguistic nature, and therefore the unstructured and free way to express human knowledge. For this, computational techniques are required to discover patterns of interest in those textual information sets.
1.2 Text Mining and Text Analytics
Text mining and text analytics are highly interchangeable terms. Text mining is the automated process of examining large collections of documents or corpora to discover patterns or insights that may be interesting and useful (Ignatow & Mihalcea, 2017; Struhl, 2015; Zhai & Massung, 2016). For this, text mining identifies facts, relationships, and patterns that would otherwise be buried in textual data (Atkinson & Pérez, 2013). This information can be converted to a structured form that can be later analyzed and integrated with other types of systems (i.e., business intelligence, databases, and data warehouses). On the other hand, text analytics synthesizes the results of text mining so that they can be quantified and visualized in a way that supports decision-making, producing actionable insights, so text mining encompasses broader aspects than text analytics.
The applications of text analytics in industrial and business areas are many, including document clustering, text categorization, information extraction to populate databases, text generation, association discovery, etc. However, since the goal is to automatically analyze textual information sources that are written in natural language by humans, computational methods (Jurafsky et al., 2014) must be able to address three key linguistic problems:
Ambiguity: Natural language is by nature a communication mode characterized by inherent ambiguity. In linguistics, this ambiguity originates when some linguistic object has multiple interpretations or meanings. Thus, this ambiguity can be lexical (i.e., a single word with more than one meaning), syntactic (i.e., a single sentence that has several possible grammatical structures), semantic (i.e., a sentence with several possible interpretations), and pragmatic (i.e., a sentence with several possible contexts to determine its intention). To understand why this is relevant to text mining, consider the following two sentences extracted from informal texts, when searching for the word nail:
The nails of the installation are rusty.
Her nails are split after falling out.
Assume the desired task was to group phrases like these to determine common patterns. In this case, if we take few words to compare these sentences, a group with both sentences would be created. However, you know that this isn’t right, because both sentences refer to very different topics since it’s the same word that has two interpretations.
Dimensionality: Given the lexical ambiguity of the previous example, if you try to compare both sentences that have a simple syntactic structure and just a few words, you could surely compare them out without much difficulty, but even so, with quite limited analysis. However, the reality is much more complex, since a text written in natural language is highly dimensional, that is, it has many characteristics or dimensions that can describe it. Each dimension could be a word, a term (i.e., “San Francisco”), or a phrase, etc.; so, if you consider collections of many texts or documents, clearly, using conventional data analysis methods is not enough. For example, the dimensions of a Twitter message are all the words and symbols it contains, and if thousands or millions of messages are considered, clearly the dimensions begin to increase enormously, increasing the difficulty of some analysis tasks.
Linguistic Knowledge: For a human reader, the previous example sentences are relatively simple to understand for further analysis. However, for a computational method to be able to understand them, there should be a lot of lexical (i.e., Do I know the word?), syntactic (i.e., Is the phrase well formed?), semantic (i.e., What’s the meaning of the phrase?), and pragmatic (i.e., What’s the text trying to communicate as a whole?) knowledge.
For example, consider the following opinion taken from a social network: “I didn’t like your customer service”. Suppose we want to automatically determine if it expresses a positive or negative emotion about a product or service. Clearly, for this to be effective, a computational method should have or infer lexical (i.e., Are the words known and relevant?), syntactic (i.e., Is the sentence well written?), and semantic (i.e., What’s the literal meaning of the phrase?) knowledge. However, the analysis is not enough, as pragmatic knowledge is also required (To whom is this opinion referring in the context? What is it trying to communicate?), which allows reasoning about the implicit intentions of that statement and that can feed further analysis tasks. Otherwise, the answer will still be pending: didn’t like customer service, but ...
Table of contents
Cover
Half Title
Title Page
Copyright Page
Dedication
Table of Contents
List of Figures
List of Tables
Preface
Acknowledgments
Author
Chapter 1 Text Analytics
Chapter 2 Natural-Language Processing
Chapter 3 Information Extraction
Chapter 4 Document Representation
Chapter 5 Association Rules Mining
Chapter 6 Corpus-Based Semantic Analysis
Chapter 7 Document Clustering
Chapter 8 Topic Modeling
Chapter 9 Document Categorization
Concluding Remarks
Bibliography
Glossary
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Text Analytics by John Atkinson-Abutridy in PDF and/or ePUB format, as well as other popular books in Computer Science & Statistics for Business & Economics. We have over 1.5 million books available in our catalogue for you to explore.