Build and deploy an efficient data processing pipeline for machine learning model training in an elastic, in-parallel model training or multi-tenant cluster and cloudKey Features• Accelerate model training and interference with order-of-magnitude time reduction• Learn state-of-the-art parallel schemes for both model training and serving• A detailed study of bottlenecks at distributed model training and serving stagesBook DescriptionReducing time cost in machine learning leads to a shorter waiting time for model training and a faster model updating cycle. Distributed machine learning enables machine learning practitioners to shorten model training and inference time by orders of magnitude. With the help of this practical guide, you'll be able to put your Python development knowledge to work to get up and running with the implementation of distributed machine learning, including multi-node machine learning systems, in no time. You'll begin by exploring how distributed systems work in the machine learning area and how distributed machine learning is applied to state-of-the-art deep learning models. As you advance, you'll see how to use distributed systems to enhance machine learning model training and serving speed. You'll also get to grips with applying data parallel and model parallel approaches before optimizing the in-parallel model training and serving pipeline in local clusters or cloud environments. By the end of this book, you'll have gained the knowledge and skills needed to build and deploy an efficient data processing pipeline for machine learning model training and inference in a distributed manner.What you will learn• Deploy distributed model training and serving pipelines• Get to grips with the advanced features in TensorFlow and PyTorch• Mitigate system bottlenecks during in-parallel model training and serving• Discover the latest techniques on top of classical parallelism paradigm• Explore advanced features in Megatron-LM and Mesh-TensorFlow• Use state-of-the-art hardware such as NVLink, NVSwitch, and GPUsWho this book is forThis book is for data scientists, machine learning engineers, and ML practitioners in both academia and industry. A fundamental understanding of machine learning concepts and working knowledge of Python programming is assumed. Prior experience implementing ML/DL models with TensorFlow or PyTorch will be beneficial. You'll find this book useful if you are interested in using distributed systems to boost machine learning model training and serving speed.

- 284 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Distributed Machine Learning with Python
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Section 1 – Data Parallelism
In this section, you will understand why data parallelism is needed and how it works. You will implement data-parallel training and serving pipelines and learn advanced techniques for further speed-ups.
This section comprises the following chapters:
- Chapter 1, Splitting Input Data
- Chapter 2, Parameter Server and All-Reduce
- Chapter 3, Building a Data Parallel Training and Serving Pipeline
- Chapter 4, Bottlenecks and Solutions
Chapter 1: Splitting Input Data
Over the recent years, data has grown drastically in size. For instance, if you take the computer vision domain as an example, datasets such as MNIST and CIFAR-10/100 consist of only 50k training images each, whereas recent datasets such as ImageNet-1k contain over 1 million training images. However, having a larger input data size leads to a much longer model training time on a single GPU/node. In the example mentioned previously, the total training time of a useable state-of-the-art single GPU training model on a CIFAR-10/100 dataset only takes a couple of hours. However, when it comes to the ImageNet-1K dataset, the training time for a GPU model will take days or even weeks.
The standard practice for speeding up the model training process is parallel execution, which is the main focus of this book. The most popular in-parallel model training is called data parallelism. In data parallel training, each GPU/node holds the full copy of a model. Then, it partitions the input data into disjoint subsets, where each GPU/node is only responsible for model training on one of the input partitions. Since each GPU only trains its local model on a subset (not the whole set) of the input data, we need to conduct a procedure called model synchronization periodically. Model synchronization is done to ensure that, after each training iteration, all the GPUs involved in this training job are on the same page. This guarantees that the model copies that are held on different GPUs have the same parameter values.
Data parallelism can also be applied at the model serving stage. Given that the fully-trained model may need to serve a large number of inference tasks, splitting the inference input data can reduce the end-to-end model serving time as well. One major difference compared to data parallel training is that in data parallel inference, all the GPUs/nodes involved in a single job do not need to communicate anymore, which means that the model synchronization phase during data parallel training is completely removed.
This chapter will discuss the bottleneck of model training with large datasets and how data parallelism mitigates this.
The following topics will be covered in this chapter:
- Single-node training is too slow
- Data parallelism – the high-level bits
- Hyperparameter tuning
Single-node training is too slow
The vanilla model training process is to load both the training data and ML model into the same accelerator (for example, a GPU), which is called single-node training. There are mainly three steps that occur in a single node training model:
- Input pre-processing
- Training
- Validation
The following diagram shows what this looks like in a typical model training workflow:
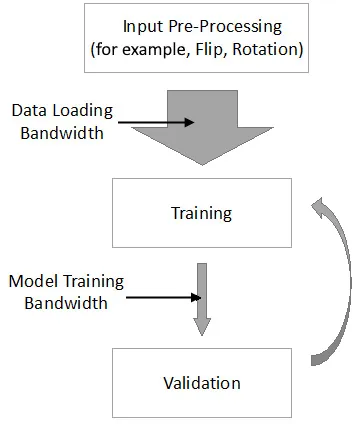
Figure 1.1 – Model training workflow on a single node
As you can see, after input pre-processing, the augmented input data is loaded into the memory of the accelerators (such as GPUs). Following that, the model is trained on the loaded input data batch and validates our trained model iteratively. The goal of this section is to discuss why single-node training is way too slow. First, we will show the real bottleneck in single-node training and then describe how data parallelism mitigates this bottleneck.
The mismatch between data loading bandwidth and model training bandwidth
Now, let's focus on the two kinds of bandwidth (BW) in this data pipeline, namely data loading bandwidth and model training bandwidth, as shown in the preceding diagram. Nowadays, we have more and more input data. Hence, we would ideally want the data loading bandwidth to be as large as possible (the wide gray arrow in the preceding diagram). However, due to the limited on-device memory of the GPUs or other accelerators, the real model training bandwidth is also limited (the narrow gray arrow in the preceding diagram).
Although it is generally believed that the larger input data size leads to a longer training time in single-node training, this is not true from the data flow perspective. From a system perspective, the mismatch between data loading bandwidth and model training bandwidth is the real issue. If we can match data loading bandwidth and model training bandwidth in single-node training, it is unnecessary to conduct in-parallel model training since distributed data processing will always introduce control overheads.
Real Bottleneck
A large input data size is not the fundamental cause of long training times in terms of single nodes. The mismatch between data loading bandwidth and model training bandwidth is the key issue.
Now that we know the reason behind the delay in single-node training when faced with large input data, let's move on to the next subtopic. Next, we will quantitively show the training times of some classic deep learning models by using standard datasets. This should help you understand why data parallel training is a must-have to deal with the mismatch between data loading bandwidth and model training bandwidth.
Single-node training time on popular datasets
Let's directly jump into training time analysis using a single GPU. We will use an NVIDIA Tesla M60 GPU as the accelerator. First, we will train both VGG-19 and ResNet-164 on the CIFAR-10 and CIFAR-100 datasets. The following diagram shows the corresponding total training time for reaching a model test accuracy over 91%:
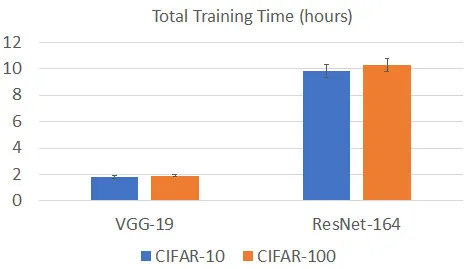
Figure 1.2 – Model training time of a single node on the CIFAR-10/100 datasets
As we can see, the total training time of VGG-19 is around 2 hours for both the CIFAR-10 and CIFAR-100 datasets, while for ResNet-164, the total training time for both the CIFAR-10 and CIFAR-100 datasets is around 10 hours.
It seems that the standard model training time, when using a single GPU on the CIFAR-10/100 dataset, is neither short nor long, which is acceptable. This is mainly because of low image resolution. For the CIFAR-10/100 datasets, the resolution of each image is very low at 32x32. Thus, the intermediate results that are generated ...
Table of contents
- Distributed Machine Learning with Python
- Contributors
- Preface
- Section 1 – Data Parallelism
- Chapter 1: Splitting Input Data
- Chapter 2: Parameter Server and All-Reduce
- Chapter 3: Building a Data Parallel Training and Serving Pipeline
- Chapter 4: Bottlenecks and Solutions
- Section 2 – Model Parallelism
- Chapter 5: Splitting the Model
- Chapter 6: Pipeline Input and Layer Split
- Chapter 7: Implementing Model Parallel Training and Serving Workflows
- Chapter 8: Achieving Higher Throughput and Lower Latency
- Section 3 – Advanced Parallelism Paradigms
- Chapter 9: A Hybrid of Data and Model Parallelism
- Chapter 10: Federated Learning and Edge Devices
- Chapter 11: Elastic Model Training and Serving
- Chapter 12: Advanced Techniques for Further Speed-Ups
- Other Books You May Enjoy
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Distributed Machine Learning with Python by Guanhua Wang in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Modelling & Design. We have over 1.5 million books available in our catalogue for you to explore.