
eBook - ePub
Applying Respondent Driven Sampling to Migrant Populations
Lessons from the Field
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Applying Respondent Driven Sampling to Migrant Populations
Lessons from the Field
About this book
This book gives a thorough introduction to the theoretical and practical aspects of planning, conducting and analysing data from Respondent Driven Sampling surveys, drawing on the experiences of experts in the field as well as pioneers that have applied Respondent Driven Sampling methodology to migrant populations.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
1
Sampling Migrants: How Respondent Driven Sampling Works
Lisa G. Johnston
Abstract: Migrants are usually considered hard-to-reach for research purposes. This chapter provides an overview of RDS and describes how and why it is superior to other common types of sampling methods used to sample hard-to-reach populations. RDS uses the social network properties of populations to enable peers to recruit their peers. Although the method may appear to be straightforward, there are several important assumptions upon which recruitment and analysis are based. This chapter lays the foundation upon which the other chapters are based.
Tyldum, Guri and Lisa G. Johnston, eds. Applying Respondent Driven Sampling to Migrant Populations: Lessons from the Field. Basingstoke: Palgrave Macmillan, 2014. DOI: 10.1057/9781137363619.0008.
Introduction
Migrants comprise populations that are considered hard-to-reach, making them difficult to sample using traditional probability methods. First, these populations lack the sampling frames needed to accurately determine the probability that each person has a chance of being selected for a sample (Kalton, 2001; Kalton & Anderson, 1986). These populations are also hard-to-reach because of language differences, time constraints due to long or irregular working hours, lack of trust due to marginalization, racism and stigma (IOM, 2001), and due to illegality as a result of being employed in shadow economies and having an irregular administrative status.
Data from demographic measurement systems, such as population censuses and registers, border admission, duration, work permit or other administrative systems are inconsistent across countries (including sending and receiving countries), and capture limited information on less hidden portions of migrant populations (Groenewold & Bilsborrow, 2008). Efforts to capture information from sizable samples of migrant populations have relied on household surveys, and on targeted and snowball sampling methods (McKenzie & Mistiaen, 2009). Household surveys using traditional random sampling or random digit dialing are capable of gathering representative data but are expensive, time consuming, and often fail to capture meaningful numbers of migrants. In addition, household surveys miss people living temporary housing and shelters, and commercial buildings as well as undocumented domestic workers living in their employer’s residence. Targeted sampling or time-location sampling only work for populations that are geographically concentrated or are visible at common venues such as mosques, churches or other social organizations, health care facilities, temporary shelters and public squares (Watters & Biernacki, 1989; Muhib et al., 2001). This type of sampling often requires questionnaires to be short, post sampling weights to account for venue attendance frequency variation and a random selection of numerous sampling venues, as well as being prone to high non-response rates (Karon & Wenjert, 2012; McKenzie & Mistiaen, 2009). Snowball sampling, in which migrant individuals or households containing migrants are asked to provide referrals to other individuals or households, produce non-probability samples of unknown representativeness, making it difficult to generalize any conclusions reached from them (Bonnie, 1978).
In 1997, respondent driven sampling (RDS) was introduced as an alternative method to recruit and to provide generalizable estimates of hard-to-reach populations. Several aspects of RDS make is suitable for sampling migrant populations, especially those that are most hidden and are least likely to participate in surveys using other sampling strategies. This chapter describes how RDS works, providing examples of its suitability for hard-to-reach populations, and the functional and analytic assumptions upon which RDS is based.
How RDS works
Although RDS may at first appear to be a relatively easy-to-implement method, in reality many investigators have difficulty making sense of and meeting the strict assumptions and in properly following the implementation and analysis parameters of the method. Basically, RDS is a modified form of chain-referral sampling, whereby peers recruit their peers using coupons with unique code numbers (Heckathorn, 1997; 2002). As many migrant populations can identify others as members of their own group, relying on them to recruit other migrants is often a feasible strategy (Johnston & Malekinejad, 2014). Involved in the recruitment process are nominal incentives for survey participation and peer recruitment. Incentives, along with modified peer pressure, encourage people to enroll in the survey and to, in turn, influence their peers to enroll as well.
Recruitment is initiated with a small, diverse and influential group of “seeds” (eligible respondents) selected by the researchers. Each seed receives a set number of recruitment coupons to recruit his/her peers who then present the coupons at a fixed site to enroll in the survey. Eligible recruits who finish the survey process are also given a set number of coupons to recruit their peers. The recruited peers of seeds who enroll in the survey become wave one respondents, and the recruits of wave one respondents become wave two respondents. This process of recruitment continues through successive waves until the calculated sample size is reached. In the end, the waves produced by effective seeds make up recruitment chains of varying lengths. The goal is to acquire long recruitment chains made up of multiple waves. Figure 1.1, from the sub-Saharan Africans in Morocco’ survey, (see Appendix I, for a thorough presentation of all surveys referred to in this volume) shows a recruitment chain made up of ten waves, including 50 respondents. To the left of the graphic is a side bar with the corresponding wave numbers.
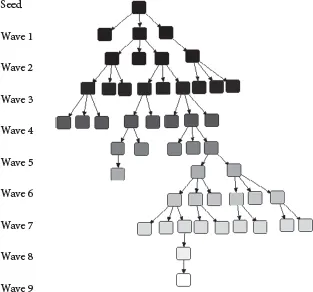
FIGURE 1.1 Recruitment chain in RDS. Illustration of seed and waves
Source: Authors simulation.
The RDS sampling methodology minimizes several types of bias found in other chain-referral methods (Heckathorn, 1997; Johnston, 2013b). The use of “coupon quotas” (a set number of coupons, usually no more than three) for all respondents reduces the opportunity for those with larger network sizes to over-represent the sample with individuals who have characteristics similar to them. Allowing the use of a small number of coupons for each respondent also serves to lengthen recruitment chains, penetrating more deeply into the network and reducing sample dependence on the seeds. So even if the only available seeds are those who can be found at the only migrant social organization in town, long recruitment chains help ensure that individuals not associated with that migrant social organization are also included in the sample.
An incentive not only for participation, but also for recruitment, encourages traditionally hesitant individuals to participate in the survey, thereby reducing non-response. Additionally, the use of social pressure from a trusted peer, who is incentivized to recruit his or her peers, results in higher response rates. Finally, the use of coupons with unique numbers or codes allows respondents to remain anonymous, also reducing non-response bias. More hidden types of migrants, who normally would not participate in a survey, may feel more comfortable in enrolling knowing that researchers will not have any personal information that can be used to contact them later.
It is common that researchers gather data using RDS methods without understanding that RDS requires special analysis. Once data is collected using RDS methods, it must be analyzed to reduce biases by applying computational weights. Therefore, RDS must be considered both a sampling and an analysis method and every survey requires both methods in order to be called “RDS”.
RDS assumptions
There are a number of assumptions in RDS, many of which are based on social science statistics (Heckathorn, 2007), and some of which are difficult to meet in real-world applications of RDS (Gile et al., 2014). The first assumption is that respondents know one another as members of the target population and recruitment ties are reciprocal. Basically, the target population must be socially networked and know (and be able to recruit) persons in that social network who also know them. For instance, just because someone is a “migrant” living in Madrid does not mean he/she is socially networked with other migrants. Migrants may be from different countries, speak different languages and have different customs, all of which would create barriers to forming social networks. However, migrants originating from a particular country living in Madrid may be socially networked and have reciprocal relationships with other migrants from that same originating country.
The second assumption is that there is sufficient cross-over between sub-groups and that networks are dense enough to sustain a chain-referral process. Although a population might be socially networked, there may be barriers within that network that would prevent members recruiting each other or there might be so few members that sampling cannot be sustained. Polish migrants living in Madrid, for example, might contain two distinct groups that never interact. The barrier here could, for instance, be between migrants with high and low socioeconomic status. If these two distinct groups of Polish migrants do not recruit each other and they have distinctly different characteristics, then the final estimates from the survey will be unstable. Avoiding these types of barriers ensures that the entire network being sampled is one single network component rather than isolated clusters of distinct sub-groups. In addition, if there are too few Polish migrants in Madrid, the numbers will not allow the required sample.
The third assumption is that sampling occurs with replacement. Sampling with replacement requires that the sample size be small in relation to the population size. If the sample size required to create valid estimates is large and your population size is small, it is possible that achieving the target sample size would be impossible because respondents would not have a large enough pool of eligible individuals in their network to recruit. There is some debate about whether RDS can be a sampling with replacement method. On the surface, it is not, since a respondent is allowed to enroll only once (Gile & Handcock, 2010); however, the assumption is viewed more loosely if the sample size is small relative to the population size (Volz & Heckathorn, 2008).
The fourth assumption is that respondents are recruited from one’s network at random. RDS assumes that respondents recruit as though they are choosing randomly from the pool of people they know who are eligible for recruitment. Non-random recruitment will not necessarily bias the RDS estimator as long as recruitment is not correlated with any variable important for estimation (Volz & Heckathorn, 2008). In practice, it is difficult to ensure random recruitment in RDS (Gile et al., 2014). The type or size of incentive, the interview venue or level of stigma and discrimination towards the population and the survey topic can influence whom respondents choose to recruit (Heckathorn, 2007).
The fifth assumption is that respondents can accurately report their personal network size, defined as the number of acquaintances, relatives and friends who can be considered members of the target population. The personal network size is measured by asking the respondent a series of questions that will lead to an estimate of the number of people they know, who would meet the eligibility criteria. The personal network size sets up the probability that an individual will be recruited and is used to calculate weights for data analysis. Essentially, those with larger network sizes have more paths that lead to them and are therefore more likely to be recruited than those with smaller networks, so they are assigned smaller weights. Respondents with small network sizes are assigned larger weights because they have fewer paths that lead to them.
The sixth assumption is that each respondent recruits a single peer. Ideally, RDS should allow for each person to recruit only one peer in order to avoid the bias of differential recruitment. However, to avoid recruitment chains from terminating, RDS allows for respondents to recruit slightly more, usually two or three. Many surveys now start with multiple coupons but reduce coupons once sampling is underway (Johnston et al., 2008) in order to reduce differential recruitment and improve variance (Goel & Salganik, 2009).
The seventh and final assumption is that a Markov chain model of recruitment is appropriate, resulting in a sample independent of seeds (Heckathorn, 2007). This is where the concepts of homophily and equilibrium are important. Homophily is the principle that contact between similar people occurs at a higher rate than between dissimilar people. This tendency often results in homogeneity of characteristics (most importantly socio-demographic characteristics) within respondent’s personal networks (McPherson et al., 2001). Given that the seeds are purposefully selected, it is expected that the characteristics of the respondents in the initial waves of recruitment would be similar to those of the purposefully selected seeds. As a chain accumulates more waves, the bias from the seeds is reduced as new recruits enter the sample. Equilibrium is a diagnostic that measures the bias of the seeds. Equilibrium, also known as convergence, is the cumulative measure of proportions for a variable for each wave of the sample. For illustration, Figure 1.2 below shows the equilibrium estimates for the gender distribution in a sample. The vertical axis shows the percentage of males and females at each wave (horizontal axis). Equilibrium is attained when the proportions remain stable, within 2%, of the sample proportion. The proportions for this example appear to stabilize around wave 6 or 7 (see arrow), and remain stable until the final wave. The final sample comprises 71.5% males and 28.5% females.
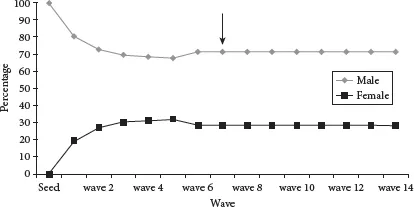
FIGURE 1.2 Equilibrium for males and females
Source: Survey of Anglophone sub-Saharan Africans in Morocco.
Equilibrium is the point at which the sample is no longer biased by the seeds’ characteristics, and is beginning to match the proportions of the characteristics of the network of the population being sampled.
Conclusion
RDS is a probability-based sampling method that offers solutions to numerous challenges found in many of the commonly used methods to sample migrants. If a traditional probability-based sampling design is easily available to sample a migrant population (i.e., a sampling frame exists or can be constructed, and there are no limitations in accessing migrants), it is usually best to stick with these methods rather than choose RDS. In addition, if the population is not socially networked, then some sampling method other than RDS may be more suitable. However, if considering the choice between a convenience sample, a probability-based sample that may suffer from numerous barriers to a...
Table of contents
- Cover
- Title
- Introduction
- 1 Sampling Migrants: How Respondent Driven Sampling Works
- 2 RDS and the Structure of Migrant Populations
- 3 Measuring Personal Network Size in RDS
- 4 Initiation of the RDS Recruitment Process: Seed Selection and Role
- 5 Deciding on and Distributing Incentives in RDS
- 6 Formative Assessment, Data Collection and Parallel Monitoring for RDS Fieldwork
- 7 Analyzing Data in RDS
- Appendix I: Summary of RDS Surveys Referenced
- References
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Applying Respondent Driven Sampling to Migrant Populations by G. Tyldum,L. Johnston in PDF and/or ePUB format, as well as other popular books in Social Sciences & Social Policy. We have over 1.5 million books available in our catalogue for you to explore.