Build Machine Learning models with a sound statistical understanding.About This Book• Learn about the statistics behind powerful predictive models with p-value, ANOVA, and F- statistics.• Implement statistical computations programmatically for supervised and unsupervised learning through K-means clustering.• Master the statistical aspect of Machine Learning with the help of this example-rich guide to R and Python.Who This Book Is ForThis book is intended for developers with little to no background in statistics, who want to implement Machine Learning in their systems. Some programming knowledge in R or Python will be useful.What You Will Learn• Understand the Statistical and Machine Learning fundamentals necessary to build models• Understand the major differences and parallels between the statistical way and the Machine Learning way to solve problems• Learn how to prepare data and feed models by using the appropriate Machine Learning algorithms from the more-than-adequate R and Python packages• Analyze the results and tune the model appropriately to your own predictive goals• Understand the concepts of required statistics for Machine Learning• Introduce yourself to necessary fundamentals required for building supervised & unsupervised deep learning models• Learn reinforcement learning and its application in the field of artificial intelligence domainIn DetailComplex statistics in Machine Learning worry a lot of developers. Knowing statistics helps you build strong Machine Learning models that are optimized for a given problem statement. This book will teach you all it takes to perform complex statistical computations required for Machine Learning. You will gain information on statistics behind supervised learning, unsupervised learning, reinforcement learning, and more. Understand the real-world examples that discuss the statistical side of Machine Learning and familiarize yourself with it. You will also design programs for performing tasks such as model, parameter fitting, regression, classification, density collection, and more.By the end of the book, you will have mastered the required statistics for Machine Learning and will be able to apply your new skills to any sort of industry problem.Style and approachThis practical, step-by-step guide will give you an understanding of the Statistical and Machine Learning fundamentals you'll need to build models.

- 442 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Statistics for Machine Learning
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Unsupervised Learning
The goal of unsupervised learning is to discover the hidden patterns or structures of the data in which no target variable exists to perform either classification or regression methods. Unsupervised learning methods are often more challenging, as the outcomes are subjective and there is no simple goal for the analysis, such as predicting the class or continuous variable. These methods are performed as part of exploratory data analysis. On top of that, it can be hard to assess the results obtained from unsupervised learning methods, since there is no universally accepted mechanism for performing the validation of results.
Nonetheless, unsupervised learning methods have growing importance in various fields as a trending topic nowadays, and many researchers are actively working on them at the moment to explore this new horizon. A few good applications are:
- Genomics: Unsupervised learning applied to understanding genomic-wide biological insights from DNA to better understand diseases and peoples. These types of tasks are more exploratory in nature.
- Search engine: Search engines might choose which search results to display to a particular individual based on the click histories of other similar users.
- Knowledge extraction: To extract the taxonomies of concepts from raw text to generate the knowledge graph to create the semantic structures in the field of NLP.
- Segmentation of customers: In the banking industry, unsupervised learning like clustering is applied to group similar customers, and based on those segments, marketing departments design their contact strategies. For example, older, low-risk customers will be targeted with fixed deposit products and high-risk, younger customers will be targeted with credit cards or mutual funds, and so on.
- Social network analysis: To identify the cohesive groups of people in social networks who are more connected with each other and have similar characteristics in common.
In this chapter, we will be covering the following techniques to perform unsupervised learning with data which is openly available:
- K-means clustering
- Principal component analysis
- Singular value decomposition
- Deep auto encoders
K-means clustering
Clustering is the task of grouping observations in such a way that members of the same cluster are more similar to each other and members of different clusters are very different from each other.
Clustering is commonly used to explore a dataset to either identify the underlying patterns in it or to create a group of characteristics. In the case of social networks, they can be clustered to identify communities and to suggest missing connections between people. Here are a few examples:
- In anti-money laundering measures, suspicious activities and individuals can be identified using anomaly detection
- In biology, clustering is used to find groups of genes with similar expression patterns
- In marketing analytics, clustering is used to find segments of similar customers so that different marketing strategies can be applied to different customer segments accordingly
The k-means clustering algorithm is an iterative process of moving the centers of clusters or centroids to the mean position of their constituent points, and reassigning instances to their closest clusters iteratively until there is no significant change in the number of cluster centers possible or number of iterations reached.
The cost function of k-means is determined by the Euclidean distance (square-norm) between the observations belonging to that cluster with its respective centroid value. An intuitive way to understand the equation is, if there is only one cluster (k=1), then the distances between all the observations are compared with its single mean. Whereas, if, number of clusters increases to 2 (k= 2), then two-means are calculated and a few of the observations are assigned to cluster 1 and other observations are assigned to cluster two-based on proximity. Subsequently, distances are calculated in cost functions by applying the same distance measure, but separately to their cluster centers:
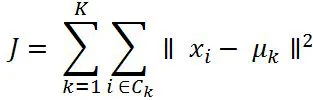
Table of contents
- Title Page
- Copyright
- Credits
- About the Author
- About the Reviewer
- www.PacktPub.com
- Customer Feedback
- Preface
- Journey from Statistics to Machine Learning
- Parallelism of Statistics and Machine Learning
- Logistic Regression Versus Random Forest
- Tree-Based Machine Learning Models
- K-Nearest Neighbors and Naive Bayes
- Support Vector Machines and Neural Networks
- Recommendation Engines
- Unsupervised Learning
- Reinforcement Learning
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Statistics for Machine Learning by Pratap Dangeti in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Science General. We have over 1.5 million books available in our catalogue for you to explore.