Learn how to use Python to create efficient applicationsAbout This Book• Identify the bottlenecks in your applications and solve them using the best profiling techniques• Write efficient numerical code in NumPy, Cython, and Pandas• Adapt your programs to run on multiple processors and machines with parallel programmingWho This Book Is ForThe book is aimed at Python developers who want to improve the performance of their application. Basic knowledge of Python is expectedWhat You Will Learn• Write efficient numerical code with the NumPy and Pandas libraries• Use Cython and Numba to achieve native performance• Find bottlenecks in your Python code using profilers• Write asynchronous code using Asyncio and RxPy• Use Tensorflow and Theano for automatic parallelism in Python• Set up and run distributed algorithms on a cluster using Dask and PySparkIn DetailPython is a versatile language that has found applications in many industries. The clean syntax, rich standard library, and vast selection of third-party libraries make Python a wildly popular language.Python High Performance is a practical guide that shows how to leverage the power of both native and third-party Python libraries to build robust applications.The book explains how to use various profilers to find performance bottlenecks and apply the correct algorithm to fix them. The reader will learn how to effectively use NumPy and Cython to speed up numerical code. The book explains concepts of concurrent programming and how to implement robust and responsive applications using Reactive programming. Readers will learn how to write code for parallel architectures using Tensorflow and Theano, and use a cluster of computers for large-scale computations using technologies such as Dask and PySpark.By the end of the book, readers will have learned to achieve performance and scale from their Python applications.Style and approachA step-by-step practical guide filled with real-world use cases and examples

- 270 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Python High Performance - Second Edition
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Implementing Concurrency
So far, we have explored how to measure and improve the performance of programs by reducing the number of operations performed by the CPU through clever algorithms and more efficient machine code. In this chapter, we will shift our focus to programs where most of the time is spent waiting for resources that are much slower than the CPU, such as persistent storage and network resources.
Asynchronous programming is a programming paradigm that helps to deal with slow and unpredictable resources (such as users) and is widely used to build responsive services and user interfaces. In this chapter, we will show you how to program asynchronously in Python using techniques such as coroutines and reactive programming.
In this chapter, we will cover the following topics:
- The memory hierarchy
- Callbacks
- Futures
- Event loops
- Writing coroutines with asyncio
- Converting synchronous code to asynchronous code
- Reactive programming with RxPy
- Working with observables
- Building a memory monitor with RxPY
Asynchronous programming
Asynchronous programming is a way of dealing with slow and unpredictable resources. Rather than waiting idle for resources to become available, asynchronous programs are able to handle multiple resources concurrently and efficiently. Programming in an asynchronous way can be challenging because it is necessary to deal with external requests that can arrive in any order, may take a variable amount of time, or may fail unpredictably. In this section, we will introduce the topic by explaining the main concepts and terminology as well as by giving an idea of how asynchronous programs work.
Waiting for I/O
A modern computer employs different kinds of memory to store data and perform operations. In general, a computer possesses a combination of expensive memory that is capable of operating at fast speeds and cheaper, and more abundant memory that operates at lower speeds and is used to store a larger amount of data.
The memory hierarchy is shown in the following diagram:
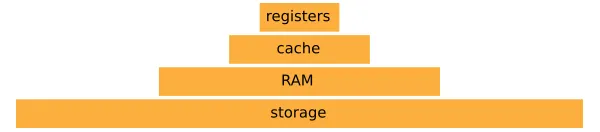
At the top of the memory hierarchy are the CPU registers. Those are integrated in the CPU and are used to store and execute machine instructions. Accessing data in a register generally takes one clock cycle. This means that if the CPU operates at 3 GHz, the time it takes to access one element in a CPU register is in the order of 0.3 nanoseconds.
At the layer just below the registers, you can find the CPU cache, which is comprised of multiple levels and is integrated in the processor. The cache operates at a slightly slower speed than the registers but within the same order of magnitude.
The next item in the hierarchy is the main memory (RAM), which holds much more data but is slower than the cache. Fetching an item from memory can take a few hundred clock cycles.
At the bottom layer, you can find persistent storage, such as a rotating disks (HDD) and Solid State Drives (SSD). These devices hold the most data and are orders of magnitude slower than the main memory. An HDD may take a few milliseconds to seek and retrieve an item, while an SSD is substantially faster and takes only a fraction of a millisecond.
To put the relative speed of each memory type into perspective, if you were to have the CPU with a clock speed of about one second, a register access would be equivalent to picking up a pen from the table. A cache access will be equivalent to picking up a book from the shelf. Moving higher in the hierarchy, a RAM access will be equivalent to loading up the laundry (about twenty x slower than the cache). When we move to persistent storage, things are quite a bit different. Retrieving an element from an SSD will be equivalent to doing a four day trip, while retrieving an element from an HDD can take up to six months! The times can stretch even further if we move on to access resources over the network.
From the preceding example, it should be clear that accessing data from storage and other I/O devices is much slower compared to the CPU; therefore, it is very important to handle those resources so that the CPU is never stuck waiting aimlessly. This can be accomplished by carefully designing software capable of managing multiple, ongoing requests at the same time.
Concurrency
Concurrency is a way to implement a system that is able to deal with multiple requests at the same time. The idea is that we can move on and start handling other resources while we wait for a resource to become available. Concurrency works by splitting a task into smaller subtasks that can be executed out of order so that multiple tasks can be partially advanced without waiting for the previous tasks to finish.
As a first example, we will describe how to implement concurrent access to a slow network resource. Let's say we have a web service that takes the square of a number, and the time between our request and the response will be approximately one second. We can implement the network_request function that takes a number and returns a dictionary that contains information about the success of the operation and the result. We can simulate such services using the time.sleep function, as follows:
import time
def network_request(number):
time.sleep(1.0)
return {"success": True, "result": number ** 2}
We will also write some additional code that performs the request, verifies that the request was successful, and prints the result. In the following code, we define the fetch_square function and use it to calculate the square of the number two using a call to network_request:
def fetch_square(number):
response = network_request(number)
if response["success"]:
print("Result is: {}".format(response["result"]))
fetch_square(2)
# Output:
# Result is: 4
Fetching a number from the network will take one second because of the slow network. What if we want to calculate the square of multiple numbers? We can call fetch_square, which will start a network request as soon as the previous one is done:
fetch_square(2)
fetch_square(3)
fetch_square(4)
# Output:
# Result is: 4
# Result is: 9
# Result is: 16
The previous code will take three seconds to run, but it's not the best we can do. Waiting for the previous result to finish is unnecessary as we can technically submit multiple requests at and wait for them parallely.
In the following diagram, the three tasks are represented as boxes. The time spent by the CPU processing and submitting the request is in orange while the waiting times are in blue. You can see how most of the time is spent waiting for the resources while our machine sits idle without doing anything else:

Ideally, we would like to start other new task while we are waiting for the already submitted tasks to finish. In the following figure, you can see that as soon as we submit our request in fetch_square(2), we can start preparing for fetch_square(3) and so on. This allows us to reduce the CPU waiting time and to start processing the results as soon as they become available:
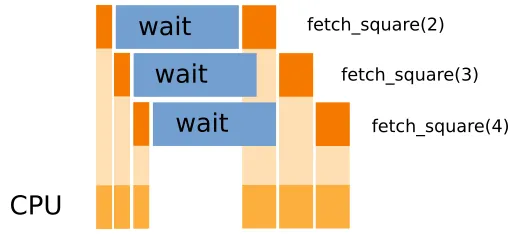
This strategy is made possible by the fact that the three requests are completely independent, and we don't need to wait for the completion of a previous task to start the next one. Also, note how a single CPU can comfortably handle this scenario. While distributing the work on multiple CPUs can further speedup the execution, if the waiting time is large compared to the processing times, the speedup will be minimal.
To implement concurrency, it is necessary to think and code differently; in the following sections, we'll demonstrate techniques and best practices to implement robust concurrent applications.
Callbacks
The code we have seen so far blocks the execution of the program until the resource is available. The call responsible for the waiting is time.sleep. To make the code start working on other tasks, we need to find a way to avoid blocking the program flow so that the rest of the program can go on with the other tasks.
One of the simplest ways to accomplish this behavior is through callbacks. The strategy is quite similar to what we do when we request a cab.
Imagine that you are at a restaurant and you've had a few drinks. It's raining outside, and you'd rather not take the bus; therefore, you request a taxi and ask them to call when they're outside so that you can come out, and you don't have to wait in the rain.
What you did in this case is request a taxi (that is, the slow resource) but instead of waiting outside until the taxi arrives, you provide your number and instructions (callback) so that you can come outside when they're ready and go home.
We will now show how this mechanism can work in code. We will compare the blocking code of time.sleep with the equivale...
Table of contents
- Title Page
- Copyright
- Credits
- About the Author
- About the Reviewer
- www.PacktPub.com
- Customer Feedback
- Preface
- Benchmarking and Profiling
- Pure Python Optimizations
- Fast Array Operations with NumPy and Pandas
- C Performance with Cython
- Exploring Compilers
- Implementing Concurrency
- Parallel Processing
- Distributed Processing
- Designing for High Performance
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Python High Performance - Second Edition by Gabriele Lanaro in PDF and/or ePUB format, as well as other popular books in Computer Science & Parallel Programming. We have over 1.5 million books available in our catalogue for you to explore.