Create scalable machine learning applications to power a modern data-driven business using Spark 2.xAbout This Book• Get to the grips with the latest version of Apache Spark• Utilize Spark's machine learning library to implement predictive analytics• Leverage Spark's powerful tools to load, analyze, clean, and transform your dataWho This Book Is ForIf you have a basic knowledge of machine learning and want to implement various machine-learning concepts in the context of Spark ML, this book is for you. You should be well versed with the Scala and Python languages.What You Will Learn• Get hands-on with the latest version of Spark ML• Create your first Spark program with Scala and Python• Set up and configure a development environment for Spark on your own computer, as well as on Amazon EC2• Access public machine learning datasets and use Spark to load, process, clean, and transform data• Use Spark's machine learning library to implement programs by utilizing well-known machine learning models• Deal with large-scale text data, including feature extraction and using text data as input to your machine learning models• Write Spark functions to evaluate the performance of your machine learning modelsIn DetailThis book will teach you about popular machine learning algorithms and their implementation. You will learn how various machine learning concepts are implemented in the context of Spark ML. You will start by installing Spark in a single and multinode cluster. Next you'll see how to execute Scala and Python based programs for Spark ML. Then we will take a few datasets and go deeper into clustering, classification, and regression. Toward the end, we will also cover text processing using Spark ML.Once you have learned the concepts, they can be applied to implement algorithms in either green-field implementations or to migrate existing systems to this new platform. You can migrate from Mahout or Scikit to use Spark ML.By the end of this book, you will acquire the skills to leverage Spark's features to create your own scalable machine learning applications and power a modern data-driven business.Style and approachThis practical tutorial with real-world use cases enables you to develop your own machine learning systems with Spark. The examples will help you combine various techniques and models into an intelligent machine learning system.

eBook - ePub
Machine Learning with Spark - Second Edition
- 532 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Machine Learning with Spark - Second Edition
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Building a Classification Model with Spark
In this chapter, you will learn the basics of classification models, and how they can be used in a variety of contexts. Classification generically refers to classifying things into distinct categories or classes. In the case of a classification model, we typically wish to assign classes based on a set of features. The features might represent variables related to an item or object, an event or context, or some combination of these.
The simplest form of classification is when we have two classes; this is referred to as binary classification. One of the classes is usually labeled as the positive class (assigned a label of 1), while the other is labeled as the negative class (assigned a label of -1, or, sometimes, 0). A simple example with two classes is shown in the following figure. The input features, in this case, have two dimensions, and the feature values are represented on the x and y-axes in the figure. Our task is to train a model that can classify new data points in this two-dimensional space as either one class (red) or the other (blue).
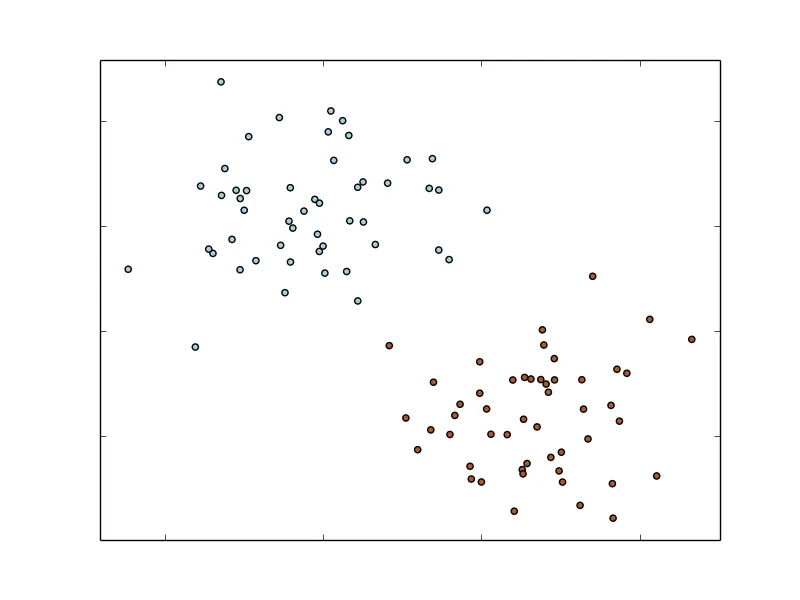
A simple binary classification problem
If we have more than two classes, we would refer to multiclass classification, and classes are typically labeled using integer numbers starting at 0 (for example, five different classes would range from label 0 to 4). An example is shown in the following figure. Again, the input features are assumed to be two-dimensional for ease of illustration:
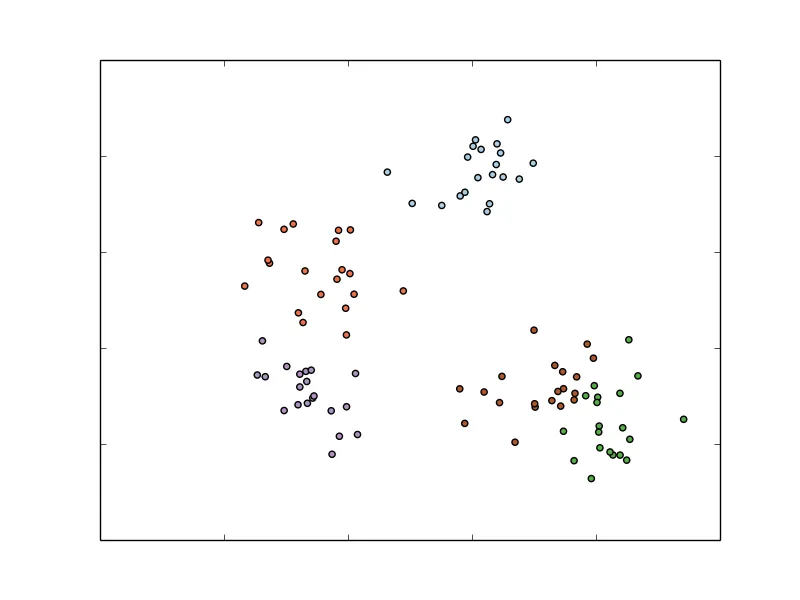
A simple multiclass classification problem
Classification is a form of supervised learning, where we train a model with training examples that include known targets or outcomes of interest (that is, the model is supervised with these example outcomes). Classification models can be used in many situations, but a few common examples include the ones listed next:
- Predicting the probability of Internet users clicking on an online advert; here, the classes are binary in nature (that is, click or no click)
- Detecting fraud; again, in this case, the classes are commonly binary (fraud or no fraud)
- Predicting defaults on loans (binary)
- Classifying images, video, or sounds (most often multiclass, with potentially very many different classes)
- Assigning categories or tags to news articles, web pages, or other content (multiclass)
- Discovering e-mail and web spam, network intrusions, and other malicious behavior (binary or multiclass)
- Detecting failure situations, for example, in computer systems or networks
- Ranking customers or users in order of probability that they might purchase a product or use a service
- Predicting customers or users who might stop using a product, service, or provider (called churn)
These are just a few possible use cases. In fact, it is probably safe to say that classification is one of the most widely used machine learning and statistical techniques in modern businesses, especially, online businesses.
In this chapter, we will do the following:
- Discuss the types of classification models available in ML library
- Use Spark to extract appropriate features from raw input data
- Train a number of classification models using ML library
- Make predictions with our classification models
- Apply a number of standard evaluation techniques to assess the predictive performance of our models
- Illustrate how to improve model performance using some of the feature extraction approaches from Chapter 4, Obtaining, Processing, and Preparing Data with Spark
- Explore the impact of parameter tuning on model performance, and learn how to use cross-validation to select the most optimal model parameters
Types of classification models
We will explore three common classification models available in Spark: linear models, decision trees, and naive Bayes models. Linear models, while less complex, are relatively easier to scale to very large datasets. Decision tree is a powerful non-linear technique, which can be a little more difficult to scale up (fortunately, ML library takes care of this for us!) and more computationally intensive to train, but delivers leading performance in many situations. The naive Bayes models are more simple, but are easy to train efficiently and parallelize (in fact, they require only one pass over the dataset). They can also give reasonable performance in many cases where appropriate feature engineering is used. A naive Bayes model also provides a good baseline model against which we can measure the performance of other models.
Currently, Spark's ML library supports binary classification for linear models, decision trees, and naive Bayes models, and multiclass classification for decision trees and naive Bayes models. In this book, for simplicity in illustrating the examples, we will focus on the binary case.
Linear models
The core idea of linear models (or generalized linear models) is that we model the predicted outcome of interest (often called the target or dependent variable) as a function of a simple linear predictor applied to the input variables (also referred to as features or independent variables).
y = f(WTx)
Here, y is the target variable, w is the vector of parameters (known as the weight vector), and x is the vector of input features.
wTx is the linear predictor (or vector dot product) of the weight vector w and feature vector x. To this linear predictor, we applied a function f (called the link function).
Linear models can, in fact, be used for both classification and regression, simply by changing the link function. Standard linear regression (covered in the next chapter) uses an identity link (that is, y =WTx directly), while binary classification uses alternative link functions as discussed here.
Let's take a look at the example of online advertising. In this case, the target variable would be 0 (often assigned the class label of -1 in mathematical treatments) if no click was observed for a given advert displayed on a web page (called an impression). The target variable would be 1 if a click occurred. The feature vector for each impression would consist of variables related to the impression event (such as features relating to the user, web page, advert and advertiser, and various other factors relating to the context of the event, such as the type of device used, time of the day, and geolocation).
Thus, we would like to find a model that maps a given input feature vector (advert impression) to a predicted outcome (click or not). To make a prediction for a new data point, we will take the new feature vector (which is unseen, and hence, we do not know what the target variable is), and compute the dot product with our weight vector. We will then apply the relevant link function, and the result is our predicted outcome (after applying a threshold to the prediction, in the case of some models).
Given a set of input data in the form of feature vectors and target variables, we would like to find the weight vector that is the best fit for the data, in the sense that we minimize some error between what our model predicts and the actual outcomes observed. This process is called model fitting, training, or optimization.
More formally, we seek to find the weight vector that minimizes the sum, over all the training examples, of the loss (or error) computed from some loss function. The loss function takes the weight vector, feature vector, and the actual outcome for a given training example as input, and outputs the loss. In fact, the loss function itself is effectively specified by the link function; hence, for a given type of classificati...
Table of contents
- Title Page
- Copyright
- Credits
- About the Authors
- About the Reviewer
- www.PacktPub.com
- Customer Feedback
- Preface
- Getting Up and Running with Spark
- Math for Machine Learning
- Designing a Machine Learning System
- Obtaining, Processing, and Preparing Data with Spark
- Building a Recommendation Engine with Spark
- Building a Classification Model with Spark
- Building a Regression Model with Spark
- Building a Clustering Model with Spark
- Dimensionality Reduction with Spark
- Advanced Text Processing with Spark
- Real-Time Machine Learning with Spark Streaming
- Pipeline APIs for Spark ML
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Machine Learning with Spark - Second Edition by Rajdeep Dua, Manpreet Singh Ghotra, Nick Pentreath in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Mining. We have over 1.5 million books available in our catalogue for you to explore.