Harness the power of Scala to program Spark and analyze tonnes of data in the blink of an eye!About This Book• Learn Scala's sophisticated type system that combines Functional Programming and object-oriented concepts• Work on a wide array of applications, from simple batch jobs to stream processing and machine learning• Explore the most common as well as some complex use-cases to perform large-scale data analysis with SparkWho This Book Is ForAnyone who wishes to learn how to perform data analysis by harnessing the power of Spark will find this book extremely useful. No knowledge of Spark or Scala is assumed, although prior programming experience (especially with other JVM languages) will be useful to pick up concepts quicker.What You Will Learn• Understand object-oriented & functional programming concepts of Scala• In-depth understanding of Scala collection APIs• Work with RDD and DataFrame to learn Spark's core abstractions• Analysing structured and unstructured data using SparkSQL and GraphX• Scalable and fault-tolerant streaming application development using Spark structured streaming• Learn machine-learning best practices for classification, regression, dimensionality reduction, and recommendation system to build predictive models with widely used algorithms in Spark MLlib & ML• Build clustering models to cluster a vast amount of data• Understand tuning, debugging, and monitoring Spark applications• Deploy Spark applications on real clusters in Standalone, Mesos, and YARNIn DetailScala has been observing wide adoption over the past few years, especially in the field of data science and analytics. Spark, built on Scala, has gained a lot of recognition and is being used widely in productions. Thus, if you want to leverage the power of Scala and Spark to make sense of big data, this book is for you.The first part introduces you to Scala, helping you understand the object-oriented and functional programming concepts needed for Spark application development. It then moves on to Spark to cover the basic abstractions using RDD and DataFrame. This will help you develop scalable and fault-tolerant streaming applications by analyzing structured and unstructured data using SparkSQL, GraphX, and Spark structured streaming. Finally, the book moves on to some advanced topics, such as monitoring, configuration, debugging, testing, and deployment.You will also learn how to develop Spark applications using SparkR and PySpark APIs, interactive data analytics using Zeppelin, and in-memory data processing with Alluxio.By the end of this book, you will have a thorough understanding of Spark, and you will be able to perform full-stack data analytics with a feel that no amount of data is too big.Style and approachFilled with practical examples and use cases, this book will hot only help you get up and running with Spark, but will also take you farther down the road to becoming a data scientist.

- 898 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Scala and Spark for Big Data Analytics
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Collection APIs
"That we become depends on what we read after all of the professors have finished with us. The greatest university of all is a collection of books."
- Thomas Carlyle
One of the features that attract most Scala users in its Collection APIs that are very powerful, flexible, and has lots of operations coupled with it. The wide range of operations will make your life easy dealing with any kind of data. We are going to introduce Scala collections APIs including their different types and hierarchies in order to accommodate different types of data and solve a wide range of different problems. In a nutshell, the following topics will be covered in this chapter:
- Scala collection APIs
- Types and hierarchies
- Performance characteristics
- Java interoperability
- Using Scala implicits
Scala collection APIs
The Scala collections are a well-understood and frequently used programming abstraction that can be distinguished between mutable and immutable collections. Like a mutable variable, a mutable collection can be changed, updated, or extended when necessary. However, like an immutable variable, immutable collections cannot be changed. Most collection classes to utilize them are located in the packages scala.collection, scala.collection.immutable, and scala.collection.mutable, respectively.
This extremely powerful feature of Scala provides you with the following facility to use and manipulate your data:
- Easy to use: For example, it helps you eliminate the interference between iterators and collection updates. As a result, a small vocabulary consisting of 20-50 methods should be enough to solve most of your collection problem in your data analytics solution.
- Concise: You can use functional operations with a light-weight syntax and combine operations and, at the end, you will feel like that you're using custom algebra.
- Safe: Helps you deal with most errors while coding.
- Fast: most collection objects are carefully tuned and optimized; this enables you data computation in a faster way.
- Universal: Collections enable you to use and perform the same operations on any type, anywhere.
In the next section, we will explore the types and associated hierarchies of Scala collection APIs. We will see several examples of using most features in the collection APIs.
Types and hierarchies
Scala collections are a well-understood and frequently-used programming abstraction that can be distinguished between mutable and immutable collections. Like a mutable variable, a mutable collection can be changed, updated, or extended when necessary. Like an immutable variable, immutable collections; cannot be changed. Most collection classes that utilize them are located in the packages scala.collection, scala.collection.immutable, and scala.collection.mutable, respectively.
The following hierarchical diagram (Figure 1) shows the Scala collections API hierarchy according to the official documentation of Scala. These all are either high-level abstract classes or traits. These have mutable as well as immutable implementations.
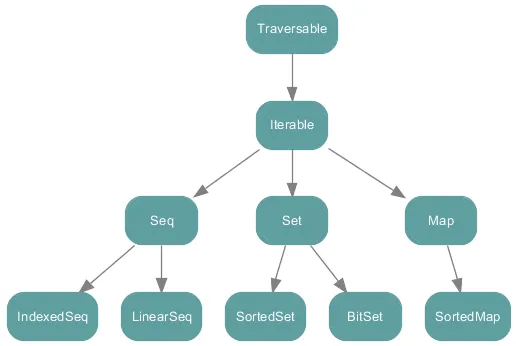
Figure 1: Collections under package scala.collection
Traversable
Traversable is the root of the collections' hierarchy. In Traversable, there are definitions for a wide range of operations that the Scala Collections API offers. There is only one abstract method in Traversable, which is the foreach method.
def foreach[U](f: Elem => U): Unit
This method is essential to all the operations contained in Traversable. If you have studied data structures, you will be familiar with traversing a data structure's elements and executing a function on each element. The foreach method does exactly so that, it traverses the elements in the collection and executes a function f on each element. As we mentioned, this is an abstract method and it was designed to have different definitions according to the underlying collection that will make use of it, to ensure highly optimized code for each collection.
Iterable
Iterable is the second root in the hierarchy diagram of the Scala collections API. It has an abstract method called iterator that must be implemented/defined in all other subcollections. It also implements the foreach method from the root, which is Traversable. But as we mentioned, all the descendent subcollections will override this implementation to make specific optimizations related to this subcollection.
Seq, LinearSeq, and IndexedSeq
A sequence has some differences from the usual Iterable, and it has a defined length and order. Seq has two sub-traits such as LinearSeq and IndexedSeq. Let's have a quick overview on them.
LinearSeq is a base trait for linear sequences. Linear sequences have reasonably efficient head, tail, and isEmpty methods. If these methods...
Table of contents
- Title Page
- Copyright
- Credits
- About the Authors
- About the Reviewers
- www.PacktPub.com
- Customer Feedback
- Preface
- Introduction to Scala
- Object-Oriented Scala
- Functional Programming Concepts
- Collection APIs
- Tackle Big Data – Spark Comes to the Party
- Start Working with Spark – REPL and RDDs
- Special RDD Operations
- Introduce a Little Structure - Spark SQL
- Stream Me Up, Scotty - Spark Streaming
- Everything is Connected - GraphX
- Learning Machine Learning - Spark MLlib and Spark ML
- My Name is Bayes, Naive Bayes
- Time to Put Some Order - Cluster Your Data with Spark MLlib
- Text Analytics Using Spark ML
- Spark Tuning
- Time to Go to ClusterLand - Deploying Spark on a Cluster
- Testing and Debugging Spark
- PySpark and SparkR
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Scala and Spark for Big Data Analytics by Md. Rezaul Karim, Sridhar Alla in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Processing. We have over 1.5 million books available in our catalogue for you to explore.