Measuring Second Language Vocabulary Acquisition provides an examination of the background to testing vocabulary knowledge in a second language and in particular considers the effect that word frequency and lexical coverage have on learning and communication in a foreign language. It examines the tools we have for assessing the various facets of vocabulary knowledge such as aural and written word recognition, the link with word meaning, and vocabulary depth. These are illustrated and the scores they produce are demonstrated to provide normative data. Vocabulary acquisition from course books and in the classroom in examined, as is vocabulary uptake from informal tasks. This book ties scores on tests of vocabulary breadth to performance on standard foreign language examinations and on hierarchies of communicative performance such as the CEFR.

- 328 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Measuring Second Language Vocabulary Acquisition
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
Explanations and Definitions
The intention in this chapter is to give working explanations of vocabulary and the various ways it can be measured. The chapter will not discuss every option and detail about why these measures have evolved exactly as they have, but should provide readers with an understanding of the terms used in this book. It will cover:
• What is vocabulary and what is meant by a word?
• What is word knowledge?
• How can vocabulary knowledge be measured?
We live in a society where we measure things all the time: our height, our weight, our shoe size, our car speed. We do it automatically and rarely think about the units we use for measurement until, that is, the units change for some reason. For example, exactly how fast is the maximum speed limit of 120 kph on roads in continental Europe when your car (my car, at least, it's an old one) only gives miles per hour (mph) on the speedometer? In order to measure anything, therefore, we need to understand the units of measurement and use them appropriately. Measuring language, and vocabulary knowledge in particular, is no exception. Misunderstand the units, or use the wrong units, and we are likely to learn very little about the language we are trying to understand. The purpose of this opening chapter is to explain what these units of measurement are in describing vocabulary acquisition and how we set about measuring vocabulary knowledge.
Measuring language is not as easy as measuring distance or weight. Language knowledge is not a directly accessible quality and we rely on learners to display their knowledge in some way so it can be measured. If learners are tired or uninterested, or misunderstand what they are expected to do, or if we construct a test badly, then they may produce language that does not represent their knowledge. A further problem arises with the qualities of language we are interested in monitoring. Grammar, for example, does not come in conveniently sized packages that can be counted. The techniques we frequently use to elicit language from learners, such as writing an essay, provide data that are not easy to assess objectively. We tend to grade performance rather than measure it and this can lead to misinterpretation. For example, if two essays are given a mark out of 10, and one is given 8 and the other 4, this does not mean that the first learner has twice the knowledge or ability as the second, even though the mark is twice as large. The use of numbers for grading suggests this ought to be the case, but it is not so. In these circumstances, it is hard to characterise second language knowledge and progress accurately or with any precision; it is hard to measure language. One of the advantages of examining vocabulary learning in a second language is that, superficially at least, it is a quality that appears to be countable or measurable in some meaningful sense. You can count the words in a passage or estimate the number of words a learner knows, and the numbers that emerge have rather more meaning than a mark out of 10 for an essay. A passage of 400 words is twice as long as a passage of 200 words. A learner who knows 2000 words in a foreign language can be said to have twice the knowledge of a learner who knows only 1000 words. While the principle of this looks very hopeful, in reality, assessing vocabulary knowledge is not quite so easy. It is not always clear, for example, exactly what is a word, and what appears to be a simple task of counting the number of words in a text can result in several possible answers. Again, in estimating the number of words a learner knows, it is possible to come up with several definitions of knowledge, some more demanding than others, which might produce very differently sized estimates. The following sections will explain the terms that are used in measuring vocabulary knowledge and learning, and will set some ground rules for the terms used in this book.
What is Vocabulary and What is Meant by a Word?
One thing the reader will find in accessing the literature on vocabulary knowledge, is that we tend to use the word 'word', presumably for ease and convenience, when we are really referring to some very specialist definitions of the term, such as types, tokens, lemmas, word families and even the attractively named hapax legomena. This can be very confusing, even depressing. My undergraduate students, for example, having read that native speakers of English know something like 200,000 words (Seashore & Eckerson, 1940), are mortified to find that their vocabularies appear less than one tenth of this size when they try out Goulden et al.'s (1990) or Diack's (1975) vocabulary size tests. The reason is that early estimates of the vocabulary knowledge of native speakers, such as Seashore and Eckerson's, used a dictionary count where every different form of a word included in the dictionary, was counted as a different word. Words such as know, knows and knowing were all treated as different words and counted separately. Later attempts to systematise such counts and use frequency information for greater accuracy, such as that of Goulden et al., include a treatment of all the common inflections and derived forms of words as a single word family. By this method, know, knows and knowing and many other similar forms are all treated as a single unit. Not surprisingly, this method of counting comes up with a smaller count than Seashore and Eckerson's — but often the result is still called a word count.
So, what is a word and how do we count it? In one sense, it can be very simple. Faced with a sentence like,
The boy stood on the burning deck,
we can count up the number of separate words in the sentence. In this case, there are seven separate words. This type of definition is useful if we want to know how many words there are in a passage, for example, or how long a student's essay is. It is also the type of definition used by dictionary compilers and publishers to explain how big the corpus is, which they use to find real examples of word use. When counting words this way, words are often called tokens to make it quite clear what is being talked about. So, we would say that the example sentence above contains seven tokens.
Sometimes you will see the expression running words used with much the same meaning. Where dictionaries give information about how frequent a word or expression is, you may be told that a word occurs once every so many thousand or million words or running words. The most common words in languages are much more frequent than this. In English, the three most frequent words (usually the, and and a/an) might make up 20% of a corpus. In a fairly normal text, therefore, you might expect to encounter one of these words once in every five running words rather than every thousand or million. In French, the two most frequent words make up 25% of Baudot's (1992) corpus, and in Greek the definite article alone comprises nearly 14% of the Hellenic National Corpus (Hatzigeorgiu et al., 2001). At the other end of the continuum, the uncommon words are much less frequent and even in the largest corpora a huge number of words occur once only. In Baudot's corpus of approximately 1.1 million words, for example, just under one third of all the entries fall into this category. There is a term for words that occur only once in any corpus or text: hapax legomena, often shortened to hapax.
In addition to knowing about the size of a piece of writing or speech, the number of words produced, we may also be interested in the number of different words that are used. The terms types and tokens are used to distinguish between the two types of count. Tokens refers to the number of words in a text or corpus, while types refers to the number of different words. Look again at the example,
The boy stood on the burning deck.
There are seven tokens, but only six types because the occurs twice. It will be appreciated that types are much more interesting to us in measuring the vocabulary knowledge of learners, as we usually want to know how many different words they have at their disposal, rather than how much they can produce regardless of repetition.
When dealing with word counts in writing, this catch-all type of definition appears quite straightforward. But, in dealing with spoken text in particular, knowing exactly what to count as a word can be difficult. How do you count the ums and ers that we sprinkle throughout our speech while we struggle to remember a word or think of what to say next? And how should we count the expressions we contract in speech, such as don't and won't; should these be counted as one word or two; do not and will not? How do you count numbers such as 777? In writing, it looks like it could be treated as a single expression, but the same expression in speech requires five words, seven hundred and seventy seven. There are few hard and fast answers to these questions, but there are conventions that most writers adhere to most of the time. In producing frequency lists for estimating vocabulary size, in general, numbers, proper nouns and names, and false starts and mistakes are now excluded from word counts. By contrast, the corpora used by dictionary compilers and other researchers may well include many of these things and even ums and ers can be recorded and categorised.
A type count uses the kind of definition of a word which Seashore and Eckerson (1940) applied in making calculations of the vocabulary knowledge in the 1920s and 1930s. It gives a very workable figure that is easily understood. Adult, educated native speakers may know several tens or even hundreds of thousands of words. So why do more modern researchers choose to use a different definition that counts different forms of a word as a single unit? The answer lies in the regularity of the rules by which words are inflected and derived in any language. A good example of this is the way plurals are formed in English. Words like dog and cat are made plural simply by adding —s to make dogs and cats. Once this rule is mastered, and it is generally learned very early, it can be applied to a huge number of other nouns. Learners do not have to learn these plural forms as separate items from the singular form. If you know one form, you can just apply the rule and you automatically have other words of this kind. Unfortunately, not all plurals are this regular and the over-application of these rules can lead to errors. Young children may use the word foots instead of feet, for example, until time and experience teach them the plural for this particular word is irregular. Irregular plural forms, such as child and children, and sheep and sheep, will need to be learned individually. Nonetheless, it makes sense, to assume, for most learners that if one form of a word is known, then other, very common derivations and inflections will also be known.
This has important implications for testing and for our understanding of how learners build very large vocabularies. In testing, it simplifies the process of choosing the words to include in a test. Instead of having to choose from hundreds of thousands or even millions of words in a dictionary, we can choose from a few thousand word families. This should give better coverage. We can test a bigger proportion of the words in a language, and make a more reliable test. It also helps explain how learners can master the several hundred thousand words which Seashore and Eckerson referred to and which appears an insuperable barrier to foreign language learners. With only a few hundred hours of classroom time available for learning, how do you learn the hundreds of thousands of words you see in a dictionary and which appear necessary for fluency? The answer is that you do not learn these words as separate items. Once you encounter and learn one form of a word, you can apply the rules for making plurals, or past tenses of verbs, or comparative and superlative adjectives, and you have a whole family of words at your disposal. This does not mean that learning vocabulary is a small or simple task. A learner still needs to learn thousands of new words in a foreign language to become competent, but it does make the task approachable in scale. Further, using the word family as the unit of measurement, it is possible to construct tests which can tell us a number of things: how vocabulary is learned, which words are being learned and when these words are being learned. Learning vocabulary in a second language becomes much more understandable when words are considered as a basic form with rule-based variations, than if every different form of the word is measured separately. It can make good sense, therefore, to count word families in some form rather than every different inflected form or spelling of a word. In counting word families, what types of word are included within the family and what forms are left out? Once again, there are no hard and fast rules for doing this, but two broad conventions have emerged. One is called lemmatisation. A lemma includes a headword and its most frequent inflections, and this process must not involve changing the part of speech from that of the headword. In English, the lemma of the verb govern, for example, would include governs, governed and governing, but not government, which is a noun and not a verb and, by this method of counting, would be a different word. Again, the lemma of quick would include quicker and quickest, which remain adjectives, but not quickly, which is an adverb and is also a different word in this system. The frequency criterion in English often uses a count made by Bauer and Nation (1993) of the occurrence of affixes. They divide these affixes into nine bands by frequency, and in lemmatising wordlists it is common to include the inflections that use affixes found only in the three most frequent bands. Table 1.1 lists some frequent headwords and the words that could be included under the lemma definition. This convention is not restricted to English. While language rules will vary in different languages, and affixes will differ in both their forms and the frequency of use, it is now convention to construct wordlists in other languages which have been lemmatised and which are as equivalent as they reasonably can be to English and to each other (e.g. Baudot [1992] in French and the Hellenic National Corpus in Greek). This raises the enticing, but as yet little investigated, possibility of comparing language knowledge in different languages rather more meaningfully than has been possible before.
Table 1.1 Some examples of common words and forms included under the definition of lemma and word family
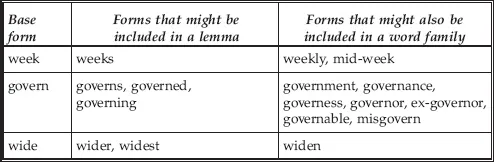
This type of count has proved useful in making estimates of the vocabulary knowledge of foreign language learners who are at elementary or intermediate levels of performance. The reason is often a practical and pragmatic one; it seems to work. As Vermeer (2004) points out, the lemma is the most reliable unit of counting words. The presumption is that learners at this level are likely to have mastered only the most frequent inflections and derivations, but will not know the more infrequent and irregular ways in which words can change. By using lemmatised wordlists as the basis for tests at this level, we get believable and stable results. Vocabulary tests, such as Nation's Levels Test (Nation, 1990; revised Schmitt et al., 2001) and X-Lex (Meara & Milton, 2003), use this kind of definition of a word in their counts and estimates of vocabulary knowledge.
The second convention is to include a wider range of inflections and derivations, and uses a word family as the basis of word counts. Again, in English, it is now usual to apply a frequency criterion on the basis of Bauer and Nation's (1993) list of affixes; in this case, inflections and derivations using affixes in the first six of the levels they define. There is no requirement, as with lemmas, for words in a word family to remain the same part of speech. Table 1.1 also lists some frequent headwords and the words that could be included in the word family definition. The table is not intended to be a complete list, which could be very long in the case of the word family, but is intended to give an idea of the process of lemma and word family formation.
Not surprisingly, this type of count will produce smaller figures for vocabulary size than calculations made using a lemmatised count. Words that would be treated as separate in a lemmatised count now fall under a single headword. This is the type of count used by Goulden et al. (1990) and Diack (1975) for their tests and the reason is not hard to see. In both cases, they are attempting to estimate the vocabulary knowledge of native speakers who can reasonably be expected to be familiar with almost all the ways of deriving and inflecting words (even if they do not know they can do this). The word family has also been used in deriving wordlists for advanced users of English as a foreign language. Coxhead's Academic Word List (2000) is one such example, and the presumption must be that the users of this list, who intend to study at university through the medium of English, will have the kind of knowledge of word formation to make them comparable with native speakers. The drawback of this convention is that the estimates of the vocabulary size it produces are not directly comparable with the estimates of foreign language learners' knowledge that often uses the lemma as the unit of measurement. There is a rule of thumb that can be used to multiply the word family score to give an equivalent score in lemmas, but this is very crude.
Rule of thumb
To compare a vocabulary size measurement made using word families with one made using lemmas, multiply the score in word families by 1.6 to get a rough (very rough) equivalent score in lemmas.
There is one further convent...
Table of contents
- Cover
- Title Page
- Copyright Page
- Contents
- Introduction
- 1 Explanations and Definitions
- 2 Word Difficulty, Word Frequency and Acquisition: Lexical Profiles
- 3 Frequency and Coverage
- 4 Measuring Vocabulary Breadth: Passive Recognition Vocabulary
- 5 Measuring Other Aspects of Vocabulary Breadth
- 6 Measuring Productive Vocabulary Knowledge
- 7 Measuring Vocabulary Depth
- 8 Vocabulary Acquisition and Assessments of Language Level
- 9 Vocabulary Acquisition and Classroom Input
- 10 Vocabulary Acquisition and Informal Language Input
- 11 Implications for Learning and Teaching: Theory and Practice
- Appendix 1
- Appendix 2
- References
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Measuring Second Language Vocabulary Acquisition by James Milton in PDF and/or ePUB format, as well as other popular books in Languages & Linguistics & Psycolinguistics. We have over 1.5 million books available in our catalogue for you to explore.