
Extending OpenStack
About this book
Discover new opportunities to empower your private cloud by making the most of the OpenStack universeAbout This Book• This practical guide teaches you how to extend the core functionalities of OpenStack• Discover OpenStack's flexibility by writing custom applications and network plugins• Deploy a containerized environment in OpenStack through a hands-on and example-driven approachWho This Book Is ForThis book is for system administrators, cloud architects, and developers who have experience working with OpenStack and are ready to step up and extend its functionalities. A good knowledge of basic OpenStack components is required. In addition, familiarity with Linux boxes and a good understanding of network and virtualization jargon is required.What You Will Learn• Explore new incubated projects in the OpenStack ecosystem and see how they work• Architect your OpenStack private cloud with extended features of the latest versions• Consolidate OpenStack authentication in your large infrastructure to avoid complexity• Find out how to expand your computing power in OpenStack on a large scale• Reduce your OpenStack storage cost management by taking advantage of external tools• Provide easy, on-demand, cloud-ready applications to developers using OpenStack in no time• Enter the big data world and find out how to launch elastic jobs easily in OpenStack• Boost your extended OpenStack private cloud performance through real-world scenariosIn DetailOpenStack is a very popular cloud computing platform that has enabled several organizations during the last few years to successfully implement their Infrastructure as a Service (IaaS) platforms. This book will guide you through new features of the latest OpenStack releases and how to bring them into production straightaway in an agile way.It starts by showing you how to expand your current OpenStack setup and how to approach your next OpenStack Data Center generation deployment. You will discover how to extend your storage and network capacity and also take advantage of containerization technology such as Docker and Kubernetes in OpenStack. Additionally, you'll explore the power of big data as a Service terminology implemented in OpenStack by integrating the Sahara project. This book will teach you how to build Hadoop clusters and launch jobs in a very simple way. Then you'll automate and deploy applications on top of OpenStack. You will discover how to write your own plugin in the Murano project. The final part of the book will go through best practices for security such as identity, access management, and authentication exposed by Keystone in OpenStack. By the end of this book, you will be ready to extend and customize your private cloud based on your requirements.Style and approachThis guide is filled with practical scenarios on how to extend and enhance OpenStack's functionality. We will be covering various installation and configuration platforms along with a focus on plugins and extending OpenStack's core functionalities.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Massively Scaling Computing Power
- Discussing the compute service in detail and adding a new compute node using Ansible
- Listing and configuring supported hypervisors in OpenStack, including Docker and Xen
- Defining new approaches on how to scale the compute service by leveraging a few OpenStack terminologies regarding compute cluster segregation
- Learning the mechanism of scheduling and weighing in OpenStack to boost the compute workload
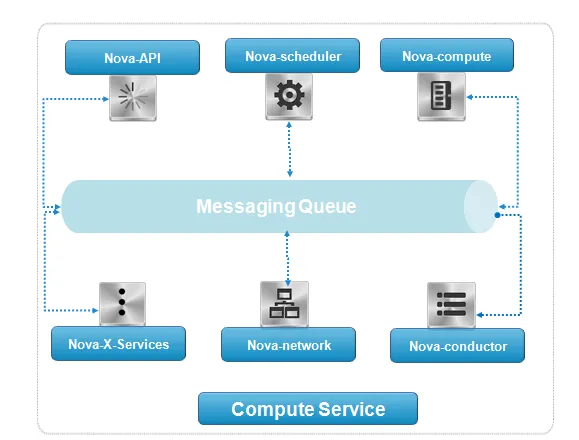
Decomposing the compute power
- nova-compute: This runs on the compute node as described in Chapter 1, Inflating the OpenStack Setup. It is responsible for communicating with the hypervisors. Nova-compute interacts with each hypervisor by means of drivers. It creates compute resources by picking up requests from the message queue.
- nova-scheduler: This runs on the cloud controller as described in Chapter 1, Inflating the OpenStack Setup. It is responsible for finding the right placement (physical server) of the initiated request to create a VM. The request will be left in the message queue along with additional information regarding the server information where the nova-compute service will create the compute resource.
- nova-api: This runs on the cloud controller as described in Chapter 1, Inflating the OpenStack Setup. It is responsible for handling API calls from other services through the messaging queue service.
- nova-conductor: This runs on the cloud controller as described in Chapter 1, Inflating the OpenStack Setup. It is responsible for managing access to the database for read/write operations for security and data coherence reasons.
- nova-consoleauth: This runs on the cloud controller as described in Chapter 1, Inflating the OpenStack Setup. It is responsible for providing authentication to the VNC console by the means of the VNC protocol.
- Metadata service: Optionally, this can run on the compute node as described in Chapter 1, Inflating the OpenStack Setup. It is responsible for booting a virtual machine with a custom configuration that will be consumed by the compute service.
Empowering the compute service
- Memory: At least 4 GB RAM
- Processor: At least 4 64-bit x86 CPUs
- Disk space: At least 40 GB free disk space
- Network: At least two NICs
... # Compute Node config.vm.define :cn02 do |cn02| cn02.vm.hostname= "cn02" cn02.vm.provider "virtualbox" do |vb| vb.customize ["modifyvm", :id, "--memory", "4096"] vb.customize ["modifyvm", :id, "--cpus", "4"] vb.customize ["modifyvm", :id, "--nicpromic2", "allow-all"] end end
- Configure the target host to be reachable by ADH (an LXC-internal network). Make sure that you have properly configured the networking setup in VirtualBox. This can be applied by just running vagrant as follows:
# vagrant up
- Before we start to deploy the new compute node, we will need to first go through the Ansible configuration files discussed in Chapter 1, Inflating the OpenStack Setup. The following stanza will be added to the /etc/openstack_deploy/openstack_user_config.yml file to instruct Ansible to use the second compute node and run the nova-compute service:
# Compute Hosts compute_hosts: ... compute-02: ip: 172.16.0.105
- The last change can be committed to git as follows:
# git add -A # git commit -a -m "Add Test Compute Node 02"
- Now we have a new host added to the list of compute nodes, we can start the deployment by running Ansible playbooks from ADH as follows:
# cd /opt/openstack-ansible/playbooks # openstack-ansible setup-hosts.yml --limit compute-02
- Updating the infrastructure using Ansible can be performed as follows:
# openstack-ansible os-nova-install.yml --skip-tags nova-key-distribute --limit compute-02
# openstack-ans...
Table of contents
- Title Page
- Copyright and Credits
- Packt Upsell
- Contributors
- Preface
- Inflating the OpenStack Setup
- Massively Scaling Computing Power
- Enlarging the OpenStack Storage Capabilities
- Harnessing the Power of the OpenStack Network Service
- Containerizing in OpenStack
- Managing Big Data in OpenStack
- Evolving Self-Cloud Ready Applications in OpenStack
- Extending the Applications Catalog Service
- Consolidating the OpenStack Authentication
- Boosting the Extended Cloud Universe
- Other Books You May Enjoy
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app