![]()
1 Introduction: Envisioning Semantic Information Spaces
Indexing languages, interoperability, information retrieval, semantic technologies – is it really worth examining the particular interaction of these rather differing subjects, as we do in this book? In this preliminary chapter we try to give a first answer why we think it is. Therefore we will pick up the idea of a semantic information space again, which was already mentioned in the preface and make it more concrete by envisioning some examples. We will take a first naive look at search situations and the impact of semantic knowledge representation, yet without considering the conceptual or technical background. Thus in this first look, information retrieval systems, indexing languages and semantic technologies are treated as a black box, which ideally provides a search environment that can be somehow characterized as a semantic information space.
Examples in this book are heterogeneous and (amongst some others) taken from the domains of chemistry, physics and biology, particularly ornithology. Although neither the authors nor the subjects of this book are affiliated to these disciplines, we will nevertheless occasionally revert to them, as they are clearly outside of our own profession and can be seen insofar as a “neutral” domain, which seems to provide a lower risk of misunderstanding than examples from the less accurate fields of humanities or social sciences would probably provide. However, there are of course no special skills in natural sciences needed to read and understand the examples and to follow the argumentation. All examples are trivial enough to be understood even without any substantial chemical, physical or zoological knowledge.
When speaking of an “information space”, one could quite generally think of two extremes: either a collection of information resources that are widely homogenous in form and content and centralized in one storage or a heterogeneous collection, distributed over several repositories and organized independently from each other – the first extreme is e.g. embodied by traditional library collections, while the most prominent example for the latter is the World Wide Web. In the following, both extremes and every possible specification between them shall be understood as information spaces.
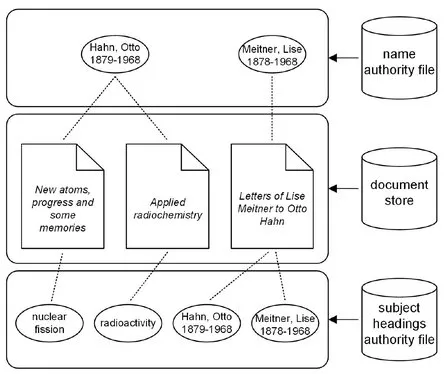
We begin our consideration with a relatively simple organized information space. Figure 1.1 shows a situation that is remindful of a bibliographic database. The document store contains a number of bibliographic records, which are representing two monographs written by the German chemist and Nobel Prize laureate Otto Hahn and one book of correspondence from the physicist Lise Meitner to Otto Hahn. To represent the authorship of Otto Hahn and Lise Meitner for each document consistently, a name authority file is used, which contains personal name authority records of both scientists that can be linked to the stored documents. In doing so, one can easily search the information space e.g. for all documents written by Otto Hahn – this search operation is often referred to as a collocation search.
Fig. 1.1: Authority files in information spaces.
Another search operation can be described as a subject search. That would be a search e.g. for all documents about “radioactivity”. To carry out subject searches, the information space must somehow provide the information of what each document is “about” – in the indexing context we also speak of the aboutness of a document (cf. Ingwersen 1992, 50–54). In bibliographic databases this aboutness is traditionally represented by one or more subject headings or thesaurus descriptors. In order to provide a consistent representation, the subject headings can be organized in a subject headings authority file, so that each subject heading has its own authority record that can be linked to the appropriate document records (cf. Fig. 1.1).
There is nothing special to the situation described so far and everybody who has ever used an online catalog of a library should be familiar with it, as it corresponds to the way bibliographic data has been organized for a long time and still continues to be organized by documentary institutions and especially libraries. However, knowledge representation is beginning beyond this situation.
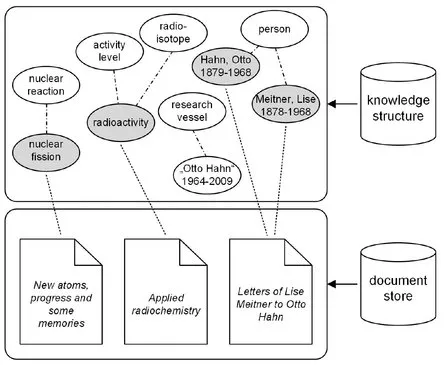
In Figure 1.2 the authority files are replaced by a network-like structure. The now grey shaded elements of Figure 1.1 seem to become more complex, as they are somehow embedded in a meaningful context – later on in this book, we will address these elements precisely and speak more abstractly of entities of a knowledge representation. What we are characterizing here rather vague as a “meaningful context” raises these entities from the keyword-based level in Figure 1.1 to a conceptual level in Figure 1.2. We will examine this important step in the following chapters and confine ourselves here to the determination that these concepts primarily can be used for indexing the stored documents and thereby fulfill the same basic descriptor function as simple keywords, but that they also open up a broader context, as they are connected to other, somehow related concepts. In the following, this situation will be referred to as a knowledge structure.
Fig. 1.2: Knowledge structures in information spaces.
Searching the information space in Figure 1.2 with a descriptor “radioactivity” leads not only to the indexed monograph of Otto Hahn “Applied radiochemistry”, but also to the related descriptors “activity level” and “radioisotope”. It becomes apparent that an information seeker, who is interested in “radioactivity”, could also be interested in certain levels of radioactivity or in concrete radioactive isotopes. The same seems to apply to “nuclear fission” and “nuclear reaction” – it isn’t unlikely that an information seeker with an interest in nuclear fission may also be interested in other nuclear reactions. Beyond that, the knowledge structure of Figure 1.2 also establishes a relationship between Otto Hahn and the rather abstract concept “person” explicit, as well as between Otto Hahn’s research colleague Lise Meitner and “person”. As a human there’s no difficulty in the cognitive interpretation of these relations – we can easily see that Otto Hahn and Lise Meitner are persons, even if we never heard their names before. By using semantic technologies, this knowledge can be made machine-readable, so that it would be able to infer (Glossary C3.2) that Otto Hahn is a person due to the fact that the concept “Hahn, Otto” is related to the concept “person” in a specific way. Likewise the risk of confusing the person Otto Hahn with the homonymous research vessel, which was launched in 1964 and named after the famous scientist, could be avoided.
At this point we have already mentioned many aspects and reached to the core issues of this book. In the following, we will take a closer look at searches in information spaces and the underlying information retrieval processes and therefore give a first impression of the usefulness of relations like the above described. We will also look at the interdependency between indexing and information retrieval processes, introduce Knowledge Organization Systems (KOSs) as types of knowledge structures that are designed to support indexing and retrieval and finally concern questions like how it could be made explicit and recognizable for a KOS that a document “Letters of Lise Meitner to Otto Hahn” is about letters that Lise Meitner wrote to Otto Hahn and not vice versa.
Based on this, we will provide a more systematic discussion of the specific types of relations and their functionality within and between knowledge structures – later on we will speak of them as intra- and intersystem relations. Yet, before that, some preliminary considerations will be provided, in order to facilitate a better understanding of the mentioned issues.
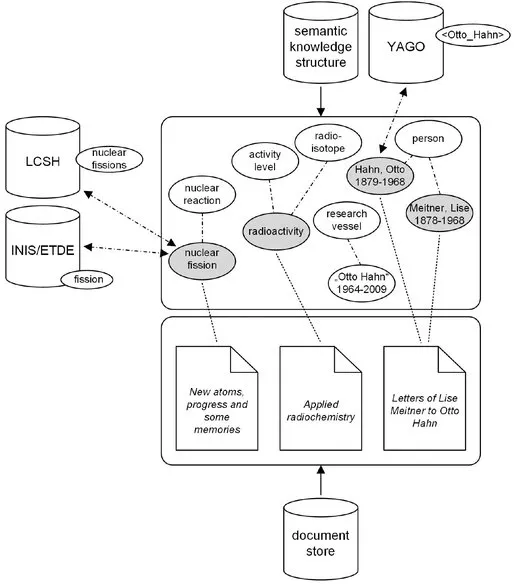
Accordingly, we will address the functionality of intersystem relations, i.e., those relations that are bridging two knowledge structures and therefore make them somehow interoperable. In this context, we will focus on the problems of heterogeneity that may arise e.g. from the use of different knowledge structures for indexing purposes. This is denoted in Figure 1.3, where single concepts of our introduced example knowledge structure are linked to other, really existing structures, namely the Library of Congress Subject Headings (LCSH), the International Nuclear Information System / Energy Technology Data Exchange (INIS/ETDE), and the YAGO project.
dp n="19" folio="5" ? Fig. 1.3: Interoperability in information spaces.
These three structures, which were arbitrary selected for this example, are quite different in their organization, coverage and purpose. The LCSH can be characterized as an authority file, INIS/ETDE is a thesaurus that has been developed and used by the International Atomic Energy Agency (IAEA), and YAGO is an ontology mainly built up with vocabulary from the Wikipedia. Since we haven’t introduced the thesaurus and the ontology as two essential types of knowledge representation yet, we won’t stress the differences between these structures here and now. Instead, we simply assert that concepts of one structure can also be part of another structure, as denot...