National DNA databanks were initially established to catalogue the identities of violent criminals and sex offenders. However, since the mid-1990s, forensic DNA databanks have in some cases expanded to include people merely arrested, regardless of whether they've been charged or convicted of a crime. The public is largely unaware of these changes and the advances that biotechnology and forensic DNA science have made possible. Yet many citizens are beginning to realize that the unfettered collection of DNA profiles might compromise our basic freedoms and rights.
Two leading authors on medical ethics, science policy, and civil liberties take a hard look at how the United States has balanced the use of DNA technology, particularly the use of DNA databanks in criminal justice, with the privacy rights of its citizenry. Krimsky and Simoncelli analyze the constitutional, ethical, and sociopolitical implications of expanded DNA collection in the United States and compare these findings to trends in the United Kingdom, Japan, Australia, Germany, and Italy. They explore many controversial topics, including the legal precedent for taking DNA from juveniles, the search for possible family members of suspects in DNA databases, the launch of "DNA dragnets" among local populations, and the warrantless acquisition by police of so-called abandoned DNA in the search for suspects. Most intriguing, Krimsky and Simoncelli explode the myth that DNA profiling is infallible, which has profound implications for criminal justice.

eBook - ePub
Genetic Justice
DNA Data Banks, Criminal Investigations, and Civil Liberties
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Genetic Justice
DNA Data Banks, Criminal Investigations, and Civil Liberties
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
Criminal LawIndex
Biological SciencesPart I
DNA in Law Enforcement: History,
Applications, and Expansion
Applications, and Expansion
Chapter 1
Forensic DNA Analysis
DNA analysis is one of the greatest technical achievements for criminal investigation since the discovery of fingerprints. Methods of DNA profiling are firmly grounded in molecular technology.
—Committee on DNA Forensic Science,
National Academy of Sciences1
National Academy of Sciences1
For those who can benefit from a primer on genetics and DNA profiles, this chapter reviews the nomenclature and genetic technology that form the basis of forensic DNA analysis. After a brief discussion of the basics of the genetic code, we explain such topics as DNA typing methods, short tandem repeats (STRs), and random-match probabilities. This chapter is designed for people who have very little background in molecular biology and forensic DNA analysis. Those who already possess this knowledge can proceed directly to chapter 2.
What Is DNA?
Deoxyribonucleic acid, or DNA for short, is the chemical in cells that specifies the composition of proteins and, along with other cellular components, contributes to their synthesis. DNA is also largely responsible for the inherited characteristics of organisms. The structure of DNA, as first postulated by James Watson and Francis Crick in 1953, is often compared with a spiral staircase or double helix with rungs or steps (see figure 1.1). The spine or backbone of the helix (analogous to the banister of the spiral staircase) consists of sugar-phosphate groups that link the steps of the spiral staircase and thus are constant throughout the length of the DNA strand for all individuals. The steps of the spiral staircase are composed of chemicals that are called bases or nucleotides. There are only four possible bases, adenine, guanine, thymine, and cytosine, denoted by the letters A, G, T, and C, respectively. The pattern or arrangement of these letters determines a person’s genotype, or genetic identity, as opposed to a person’s physical identity or phenotype (defined as the physical appearance or biochemical characteristics of an organism). No two people, with the possible exception of identical twins, have exactly the same series of letters that make up their DNA.
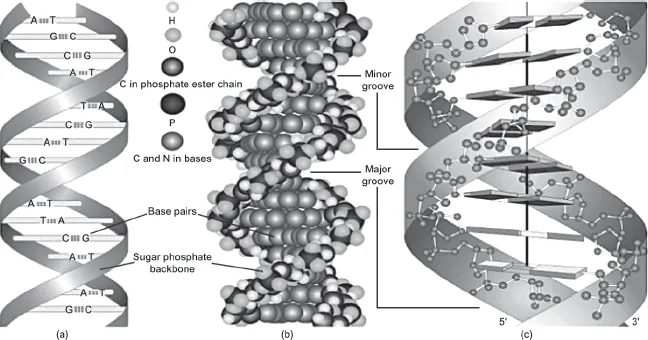
FIGURE 1.1. The double helix DNA structure. Left: A helixlike structure with two ribbons representing the sugar-phosphate groups and the horizontal steps or bases of the DNA molecule. Center: The hydrogen bond connecting complementary bases. Right: A model of a DNA molecule represented by a twisted lattice of spherical components. Source: From Modern Genetic Analysis by A. J. F. Griffiths, W. M. Gelbart, J. H. Miller, and R. C. Lewontin, ©1999, by W.H. Freeman and Company. Used with permission.
When a multicellular organism reproduces, it is the DNA within the reproductive cells (gametes or sperm and eggs) of the organism that serves as the template for the development of the fertilized egg. This fertilized egg develops into an organism of the same species, with species-similar but not necessarily identical physical (phenotypic) properties.
The complete set of human DNA is found in virtually every one of our cells (except the sperm and egg cells, which contain one-half of the DNA, and red blood cells, which have no nucleus), in every organ, and in our blood and immune system. DNA is found both in the nucleus of our cells and in the cell’s mitochondria (a component of the cell outside the nucleus that resides in the cytoplasm). The long, continuous nuclear DNA molecules are distributed on chromosomes, which also contain ribonucleic acid (RNA) and proteins. Humans have 23 pairs of chromosomes that are packaged in the nucleus of each cell. The DNA in the chromosomes is packed tightly, wound up and coiled into the nucleus of the cell. Proteins called histones help stabilize the tightly packed DNA within each chromosome.
Although DNA is thought to provide essential instructions for the functioning of our cells, it is not self-effectuating—it does not act by itself. DNA responds to prompts from the cell’s proteins, the body’s enzymes and hormones, RNA molecules, and sometimes external environmental factors. As Barry Commoner notes in “Unraveling the DNA Myth,” “Genetic information arises not from DNA alone but through its essential collaboration with protein enzymes.”2
Outside an organism, DNA can persist for many years under optimal conditions (see box 1.1). However, prolonged exposure to sunlight, warm temperatures, high humidity, and bacterial and fungal activities can result in DNA degradation. Some of the chemical enzymes released upon cell death may initiate the degradation of DNA. It is also more likely to degrade when it is on soiled rather than clean materials.
BOX 1.1 Brown’s Chicken Massacre and the Persistence of DNA Evidence
In 1993 seven people were ruthlessly killed in a robbery and left in two walk-in refrigerators at Brown’s Chicken and Pasta, a suburban Chicago restaurant. Collected from a trash can at the scene of the crime was a partly eaten dinner (two half-eaten chicken pieces). DNA testing techniques at that time were not sophisticated enough to produce any DNA profiles from traces of human saliva, so the chicken was frozen in hopes that developments in DNA testing would allow for future testing. Seven years later, that testing occurred, producing two DNA profiles. The profiles did not match any of the crime victims or suspects that police had at that time. Two years later, in 2002, a woman came forward with important details of the crime to police, including names of people who, she claimed, spoke about their involvement in the robbery. Police obtained a DNA sample from one suspect and matched it to a sample of saliva from the chicken dinner. A month later, Juan Luna and James Degorski were arrested and charged with the murders. Luna’s defense argued unsuccessfully that the DNA evidence against him should not be allowed because it had been mishandled over the years, including that it had been retested on multiple occasions and handled by scientists who acknowledged that they had not worn gloves. Both Luna and Degorski were found guilty of all seven counts of murder and were sentenced to life in prison.
Source: Authors.
What Is the Size of DNA?
If you uncoiled the entire nuclear DNA of a single human somatic cell (any cell other than sperm, egg, or red blood cells), holding the strands of the double helix end to end, its length would be about 2 meters (around 6 feet). The DNA is so thin and so tightly coiled that it can be this long but reside within the nucleus of the cell, which is about 5 millionths of a meter in diameter.
The length of a thread of DNA is usually measured in units called kilobases (kb). One kb is the molecular length equal to 1,000 base pairs of double-stranded DNA (there are two strands in the double helix), or 1,000 pairs of the bases (A, G, C, or T).
How many kilobases are there in the entire human genome? A human genome is made up of approximately 6 million kb (or 6 billion base pairs; see figure 1.1), 3 billion base pairs for each set of 23 chromosomes. To give some sense of this length, typing out the letters in a complete strand of our nuclear DNA would take up 57 million lines (where each line contained approximately 53 letters) and would fill about 1.2 million single-spaced pages.
Our DNA is distributed unequally among our 23 pairs of chromosomes. For example, chromosome 1, the largest human chromosome, has a length of 245,000 kb and would require 4.6 million lines of print or approximately 100,000 pages, while chromosome 22 of about 49,000 kb would require 925,000 lines of print or approximately 20,000 pages.
What Is a Gene?
A gene is usually defined as a segment of DNA that can be used by the machinery of the cell to synthesize a protein. In humans most of the genes are in the nucleus of the cell, dispersed across the 23 pairs of chromosomes (see figure 1.2). Genes can range in size from 100 bases (.1 kb) to as large as 2 million bases (2,000 kb). An average gene is about 5,000 bases long (5 kb).
A gene located on one of a pair of chromosomes (a particular form of a gene or a noncoding DNA sequence is called an allele) may be the same but is not necessarily identical to that of its “copy” located on the other chromosome of the pair. One of the genes residing on a chromosome was contributed by the egg and the other by the sperm. A person can often be perfectly healthy with one “good” and one “defective” copy of a gene.
The totality of the DNA in an organism or cell is called its genome. The human genome can be thought of as a set of encyclopedias with 23 volumes, where each chromosome represents one volume. The DNA code comprises the text of those volumes, and the genes make up discrete chapters or paragraphs inside each volume.
The stretch of DNA on which the gene resides has more DNA than is required to encode a protein. The region of the DNA that is used to synthesize the protein is called the coding region (also called exon). The extraneous DNA on the segment, which is excised during the process of transcription (when the protein is being synthesized), is called the noncoding region (or the intron). To use the analogy of the page of text, imagine a sequence of letters (each representing a single nucleotide) such as AAGTACATATGAACAT. Suppose that the letters CAT represent the noncoding text (intron). When the gene is read and copied into a usable message for synthesizing a protein, the noncoding regions are removed, and the remaining segment in our example is AAGTA-ATGAA. This segment (representing the functional gene) is used to make a protein product.
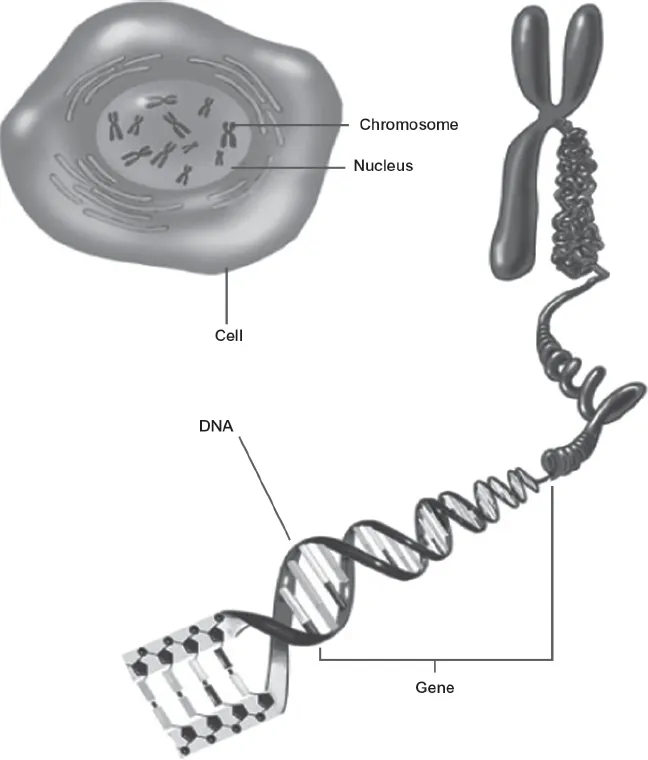
FIGURE 1.2. Human chromosomal DNA in the cell nucleus. Clockwise from the top: The cell and its nucleus, one of the 23 chromosomes, and the DNA molecule. Source: National Institute of General Medical Sciences, National Institutes of Health.
In human cells, where there are 3 billion base pairs of DNA in the nuclei, the number of genes, defined as functional segments of DNA that are used to encode proteins, is still uncertain. The International Human Genome Sequencing Consortium placed the number of protein-coding genes at 20,000 to 25,000. Other groups predict larger numbers. It is estimated that 97 to 98 percent of our DNA consists of noncoding regions.3 Some of these sequences may have other functions. For example, promoters reside near the genes and initiate gene expression starting with transcription (the process of preparing a readable RNA message of the DNA so a protein can be synthesized by a process known as translation). Other DNA sequences, called enhancers, can raise the amount of product produced. There is also noncoding DNA, sometimes referred to as “junk DNA” or “evolutionary debris,” that allegedly has no function, or at least not one that is known.
More recently, through a project called ENCODE (meaning the encyclopedia of DNA elements), scientists have discovered that a large amount of the DNA previously considered useless is essential to regulatory processes in the so-called functional part of the genome where gene transcription takes place.4 In the words of geneticist Francis Collins, formerly director of the U.S. National Human Genome Research Institute, “Transcription appears to be far more interconnected across the genome than anyone had thought.”5 The so-called noncoding regions probably play a role in coding small RNA molecules.
The Typing of DNA for Forensic Identification
Sequencing DNA means reading its code, or the series of four letters (A, G, C, and T) that make up the bases of the DNA molecule. As discussed earlier, humans have about 3 billion nucleotides in each of the 23 pairs of chromosomes. The sequence of nucleotides (reading of the human DNA) is 99.9 percent identical for all people. In other words, human genetic variation is accounted for by only 0.1 percent of DNA, or about 3 million bases.6 It is this variation in a segment of DNA that allows forensic scientists to determine whether two DNA samples could have come from the same individual.
The process of DNA analysis always begins with a sample of biological material: it could be a strand of hair, blood, sperm, tissue, skin cells, or saliva. To be useful for the analysis, the sample must have intact cells or DNA that has been removed from the cell. Unless the samples are very carefully handled, they can become contaminated by elements from the environment, such as DNA from plants, animals, insects, bacteria, or other human beings.7
If the biological sample contains cells, the first task is to break open the cells (lysing the cell membrane) or to dissolve the matrix surrounding the DNA (as in a hair shaft) to retrieve the DNA. The separation of the DNA from the biological sample is called extraction, while the separation of sperm-cell and non-sperm-cell DNA is called differential extraction. Breaking the membrane of the cell to release its DNA can be done by exposing the cells to detergents and other chemicals; different chemical recipes are effective for different cell types. Once the DNA is removed from the cell, it has to be broken down into manageable pieces so that it can be identified by its unique sequence of bases. One method to accomplish this involves the use of proteins isolated from bacteria called restriction enzymes (EcoRI in figure 1.3) that cut DNA at specified sites, leaving fragments of DNA varying in length and defined by the presence of a restriction site.
To identify specific fragments with the genetic variation of interest, scientists use probes—short, single-stranded fragments of DNA that are synthesized in a laboratory and labeled radioactively or with some other detectable molecule. A probe will seek out and attach to its complementary sequence (if it is present) to form a double-stranded sequence of DNA. Within the DNA code, base A is always complementary to base T, and G is always complementary to C. Thus a probe consisting of the nucleotide AGTTAGC is the complementary strand to TCAATCG.
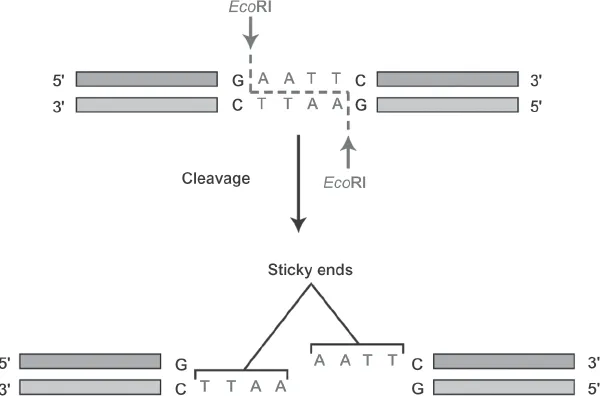
FIGURE 1.3. A restriction enzyme EcoRI is used to cut double-stranded DNA at a specific site, leaving the ends available for reattachment to...
Table of contents
- Cover
- Half title
- Title
- Copyright
- Contents
- Foreword
- Acknowledgments
- Introduction
- PART I: DNA in Law Enforcement: History, Applications, and Expansion
- PART II: Comparative Systems: Forensic DNA in Five Nations
- PART III: Critical Perspectives: Balancing Personal Liberty, Social Equity, and Security
- Appendix: A Comparison of DNA Databases in Six Nations
- Notes
- Selected Readings
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Genetic Justice by Sheldon Krimsky,Tania Simoncelli in PDF and/or ePUB format, as well as other popular books in Biological Sciences & Criminal Law. We have over 1.5 million books available in our catalogue for you to explore.