For learning the topics in this chapter, you are free to create your own data. However, if you want to reproduce the exercises exactly as they are explained, you will need the afore mentioned files from www.numbeo.com.
First, we will learn how to extract data from fields that exist in our dataset in order to generate new fields. For the first exercise, we will read a file containing data about the cost of living in Europe. The content of the file looks like this:
Rank City Cost of Living Index Rent Index Cost of Living Plus Rent Index Groceries Index Restaurant Price Index Local Purchasing Power Index
1 Zurich, Switzerland 141.25 66.14 105.03 149.86 135.76 142.70
2 Geneva, Switzerland 134.83 71.70 104.38 138.98 129.74 130.96
3 Basel, Switzerland 130.68 49.68 91.61 127.54 127.22 139.01
4 Bern, Switzerland 128.03 43.57 87.30 132.70 119.48 112.71
5 Lausanne, Switzerland 127.50 52.32 91.24 126.59 132.12 127.95
6 Reykjavik, Iceland 123.78 57.25 91.70 118.15 133.19 88.95
...
As you can see, the city field also contains the country name. The purpose of this exercise is to extract the country name from this field. In order to do this, we will go through the following steps:
- Create a new transformation and use a Text file input step to read the cost_of_living_europe.txt file.
- Drag a Split Fields step from the Transform category and create a hop from the Text file input towards the Split Fields step.
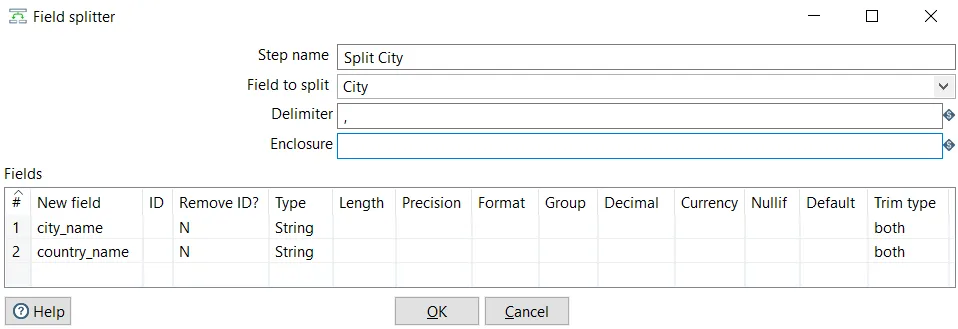
- Double-click the step and configure it, as shown in the following screenshot:
Configuring a Split Fields step
- Close the window and run a preview. You will see the following:
Previewing a transformation
As you can see, the Split Fields step can be used to split the value of a field into two or more new fields. This step is perfect for the purpose of obtaining the country name because the values were easy to parse. We had a value, then a comma, then another value. This is not always the case, but PDI has other steps for doing similar tasks. Let's look at another method for extracting pieces from a field.
This time, we will read a file containing common daily food items and their prices. The file has two fields—food and price—and looks as follows:
Food Price
Milk (regular), (0.25 liter) 0.19 €
Loaf of Fresh White Bread (125.00 g) 0.24 €
Rice (white), (0.10 kg) 0.09 €
Eggs (regular) (2.40) 0.33 €
Local Cheese (0.10 kg) 0.89 €
Chicken Breasts (Boneless, Skinless), (0.15 kg) 0.86 €
...
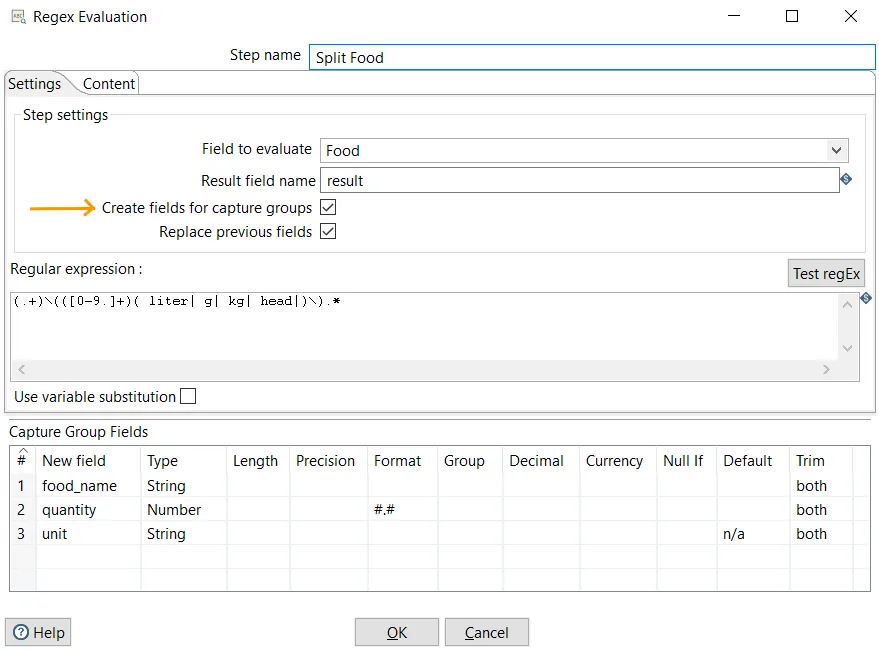
Suppose that we want to split the Food field into three fields for the name, quantity, and number of units respectively. Taking the value in the first row, Milk (regular), (0.25 liter), as an example, the name would be Milk (regular), the quantity would be 0.25, and the unit would be liter. We cannot solve this as we did before, but we can use regular expressions instead. In this case, the expression to use will be (.+)\(([0-9.]+)( liter| g| kg| head|)\).*.
Let's try it using the following steps:
- Create a new transformation and use a Text file input step to read the recommended_food.txt file.
In order to define the Price as a number, use the format #.00 €.
- Drag a Regex Evaluation step from the Scripting category and create a hop from the Text file input toward this new step.
- Double-click the step and configure it as shown in the following screenshot. Don't forget to check the Create fields for capture groups option:
Configuring a Regex Evaluation step
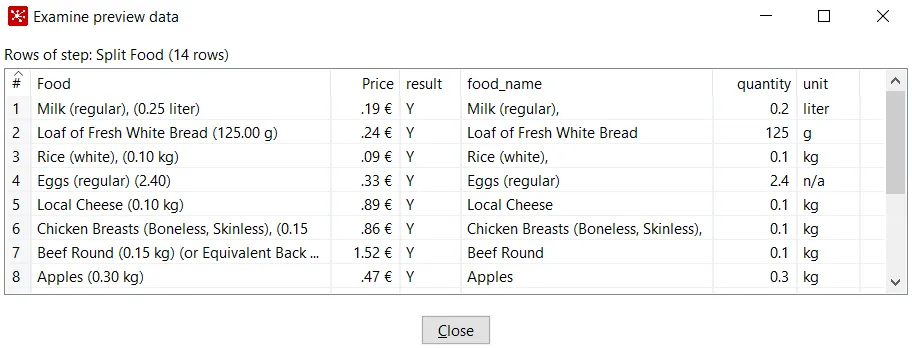
- Close the window and run a preview. You will see the following:
Previewing a transformation
The RegEx Evaluation step can be used just to evaluate whether or not a field matches a regular expression, or to generate new fields, as in this case. By capturing groups, we were able to create a new field for each group captured from the original field. You will also notice a field named result, which in our example has a Y as its value. This Y mean...